🦴 Spring JPA Persistence Context
🦴
Persistence Contextis astoragewhere a set ofentitieswithunique identitiesare persisted.
Persistence Context is a logical concept without its physical presence and is accessible via EntityManager that handles the lifecycle of all entities and database resources such as db connections.
Persistence Context provides underneath features:
🔎 First-Level Cache✍️ Transactional Write-Behind✔️ Dirty Checking🚽 Flush
where these will be discussed in the following sections.
💡 NOTES
🧑⚕️ An
Entity Manageris responsible for performingpersistence logicby interacting with thepersistence contextand changing thestateofentities. TheEntity Managercan change thestateof anentityusing methods such aspersist,merge,remove, andclose. Additionally, theEntity Managercan retrieveentitiesfrom thefirst-level cacheof thepersistence contextand synchronise with thedatabasebyflushing queriesstored in thetransactional write-behind. It is also possible to fetchdatadirectly from thedatabaseusingJPQLorNative Query.
🐣 Entity Life Cycle
🐥
Entityrefers to a piece ofdatathat is stored in thedatabase.
In Spring JPA, entity can be represented with the @Entity annotation, and annotated classes are then identified by Spring JPA as a frame that should contain data from the database in which Spring JPA executes automatic mapping.
Below could be a good example of a class with @Entity annotation:
Item Entity
@Entity
@Getter @Setter
public Item {
@Id
@GenereatedValue
private Long id;
private String name;
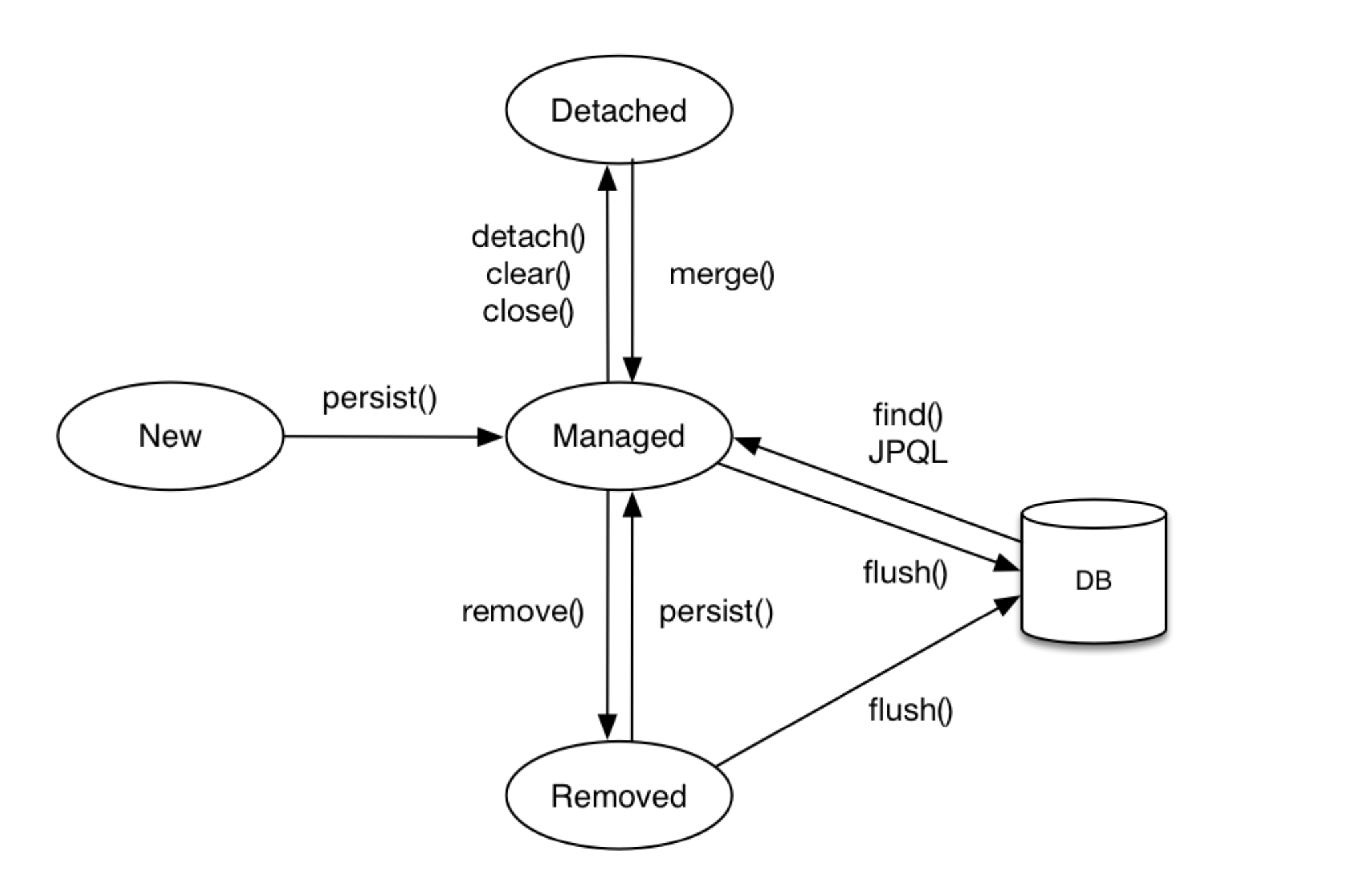
}Entity lifecycle with its graphical representation can be summarised as below:
-
🐣
new/transient- a state where an
entityis a pureJavaobject. - no relation to a
persistence context.
- a state where an
-
🧑🌾
managed- a state
managedby apersistence context.
- a state
-
🐓
detached- a state once
managedby apersistence contextbut currentlydetached.
- a state once
-
🍗
removed- a state
removedfrom apersistence contextand adatabase.
- a state
 자바 ORM 표준 JPA 프로그래밍 - 기본편
Available at here
자바 ORM 표준 JPA 프로그래밍 - 기본편
Available at here
In JPA, the above state can be achieved via the underneath code:
JPA (Entity Lifecycle)
EntityManagerFactory emf = Persistence.createEntityManagerFactory(PERSISTENCE_UNIT_NAME);
EntityManager em = emf.getEntityManager();
// new/transient
Item item = new Item();
item.setId(1L);
item.setName("item1");
// managed
em.persist(item);
Item findItem = em.find(Item.class, 1L);
// detached
em.detach(findItem);
em.clear();
em.close()
// remove
em.remove(findItem);🔎 First-Level Cache
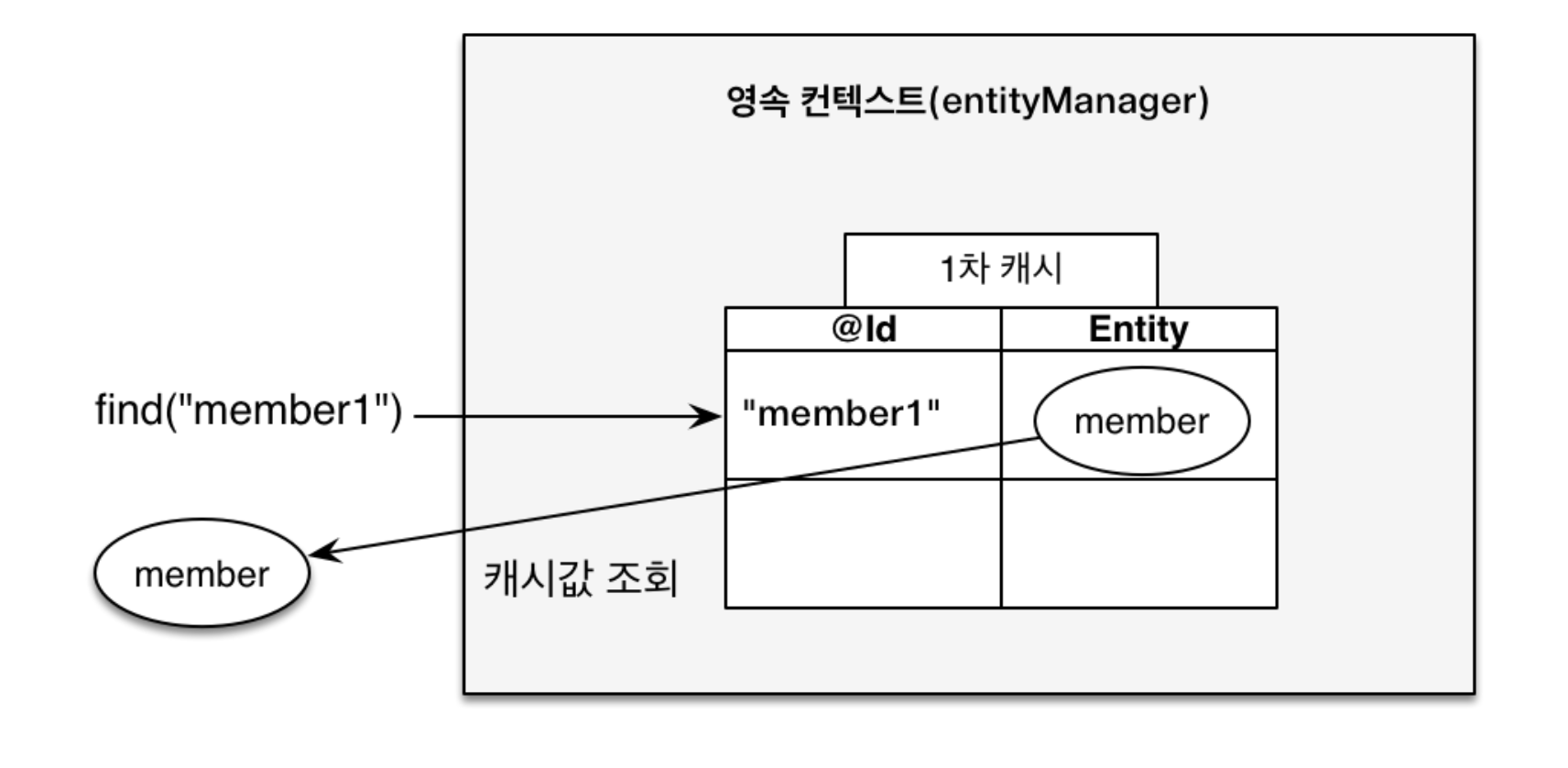
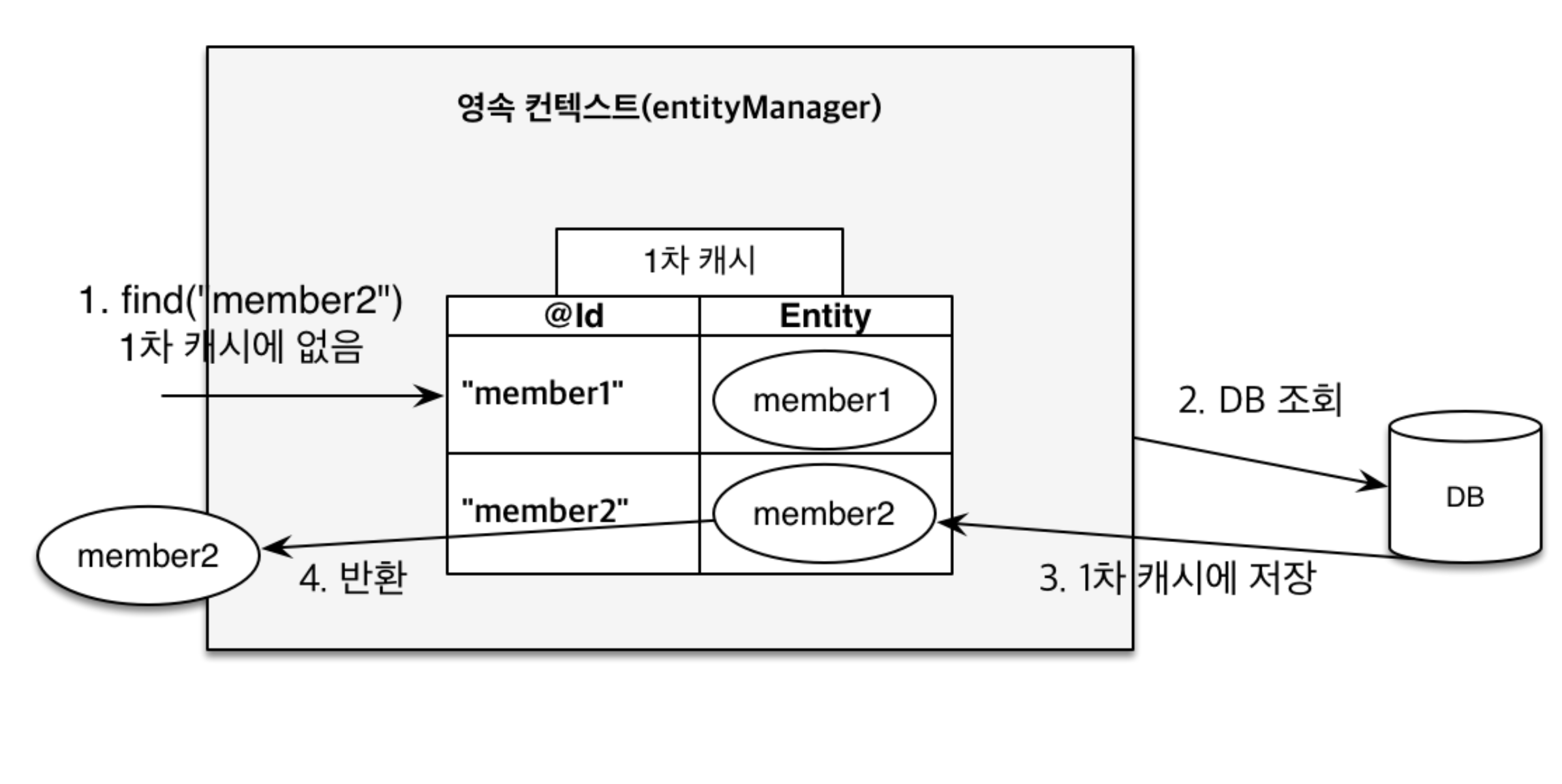
🔎 First-Level Cacheis acachewithin apersistence contextwhere anentityis stored in aHashMapas akey-value pair(id=@id,value=entity instance).
Via first-level cache, equality across identical entities becomes secured as a specified @id becomes an identifier to retrieve a cached value.
Any managed entities becomes retrievable from a first-level cache once a relevant persist() and find() method calls are invoked.
Specifically, persist() will save an entity in a first-level cache while find() will look up a database and then store the retrieved data into a first-level cache if there is no cache data so that for the sequential find() calls, the cached data becomes retrieved without necessarily connecting to the database.
The overall process can be graphically illustrated as below:
 자바 ORM 표준 JPA 프로그래밍 - 기본편
Available at here
자바 ORM 표준 JPA 프로그래밍 - 기본편
Available at here
A persistence context only exists within a single transaction, implying that a first-level cache only exists within a single transaction as well. Hence, performance-wise, first-level cache appears not to be considerable.
✍️ Transactional Write-Behind
✍️
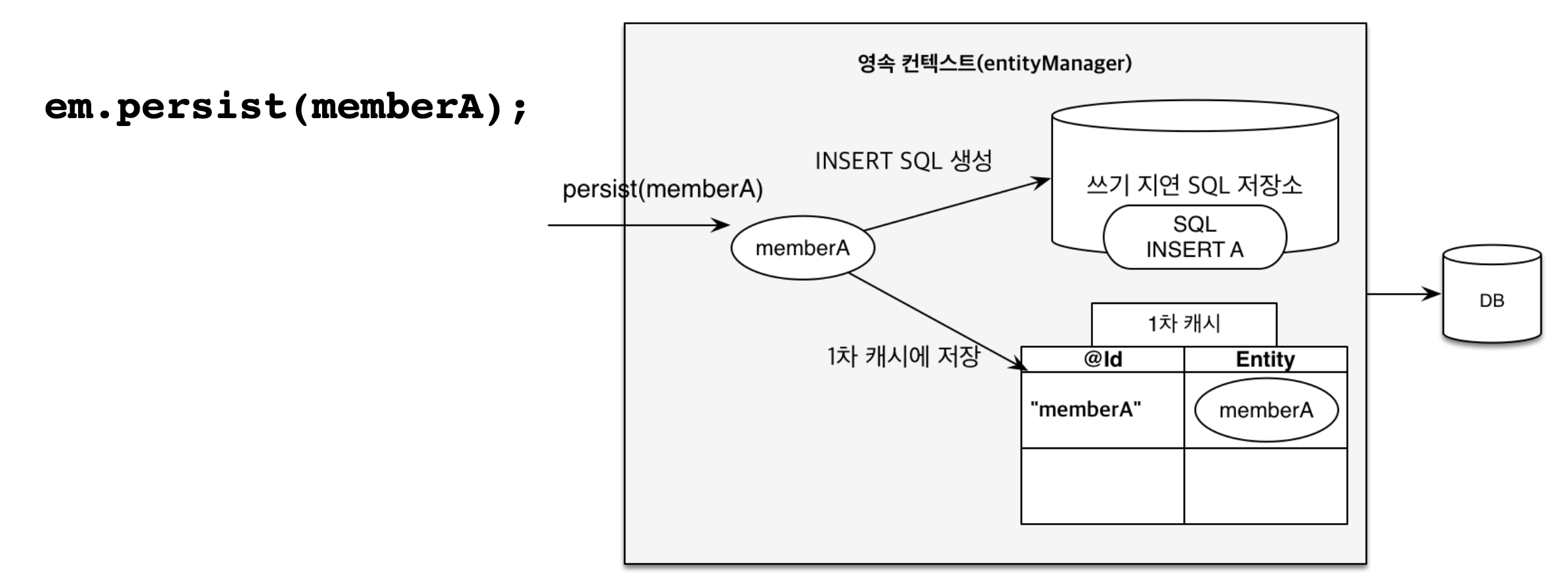
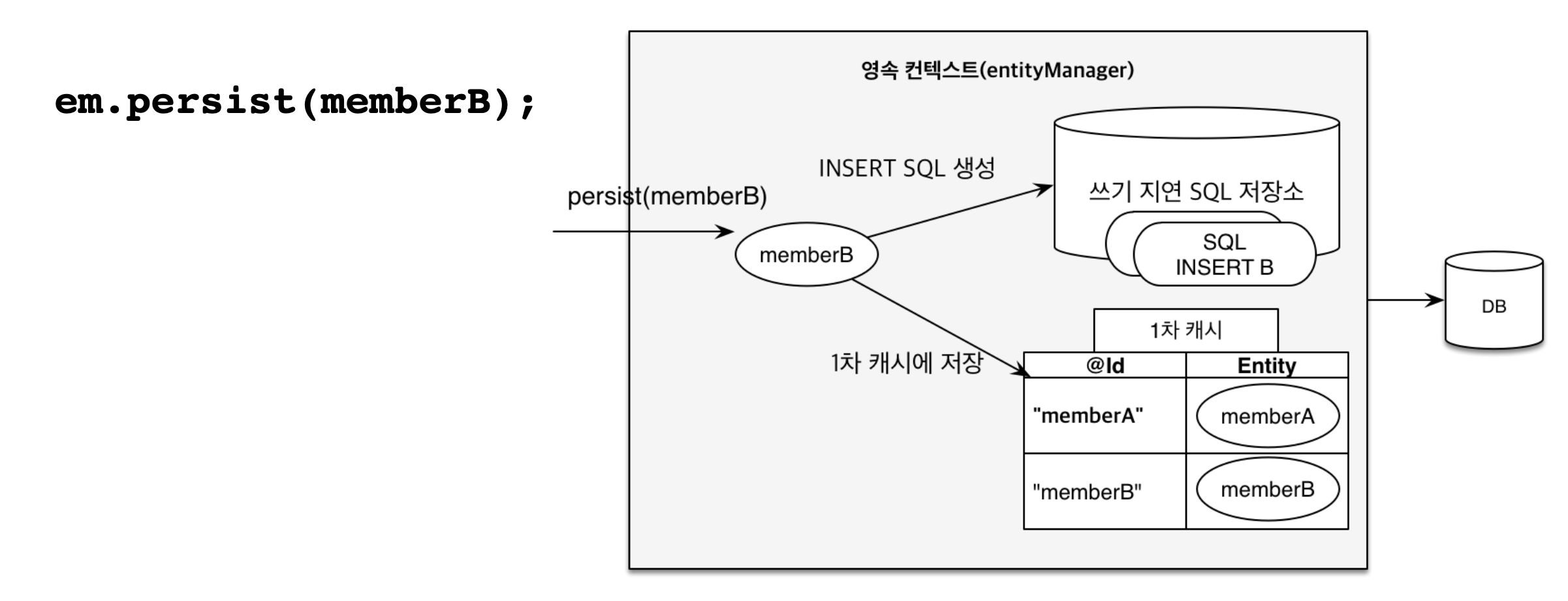
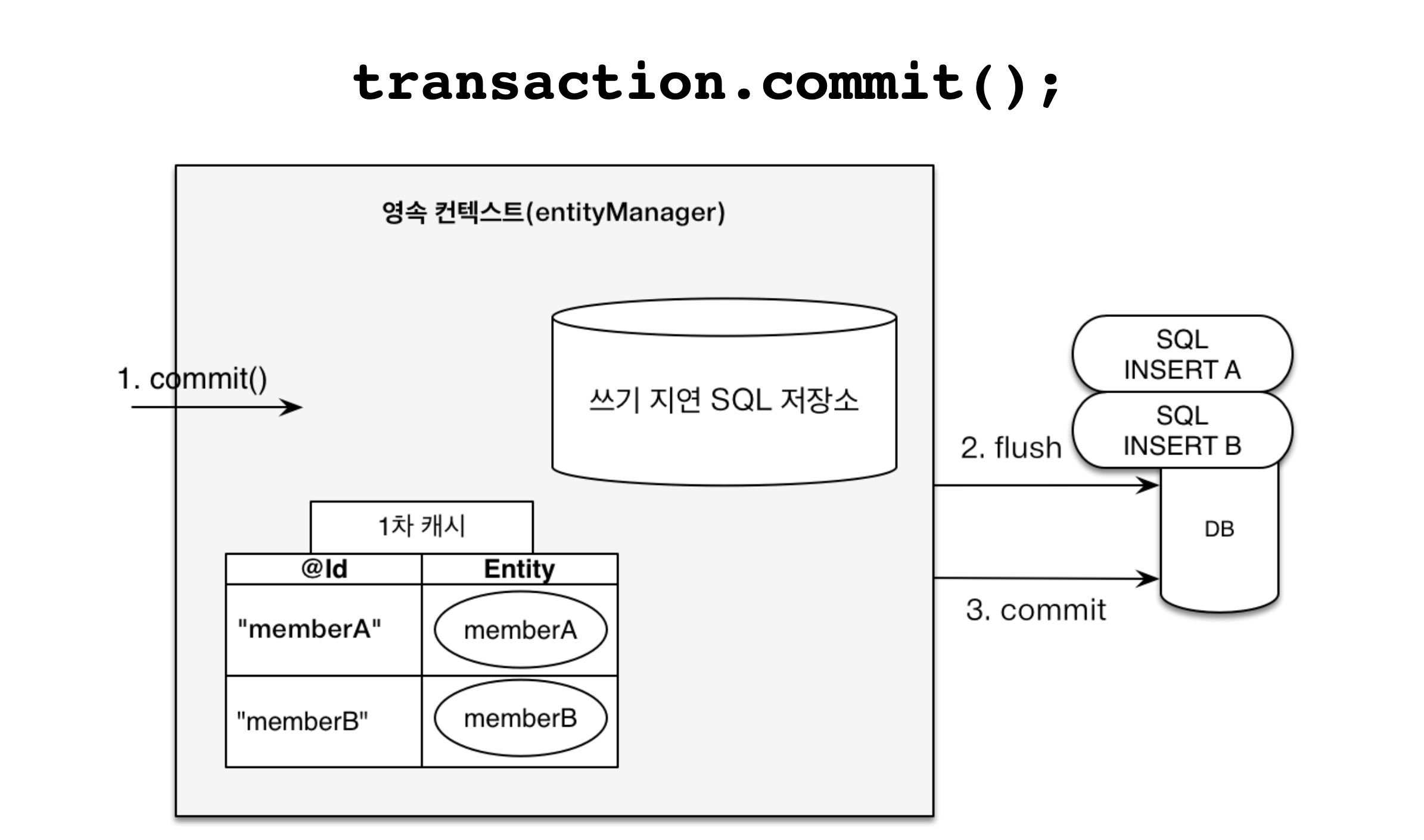
Transactional Write-Behindis a feature where any updates invokingSQL queriesto adatabaseare deferred until thetransaction commits.
The introduction of transactional write-behind deeply underlies in TCP connection between an application and a database in which connection is costly, and hence, sending all the SQL queries at once becomes a cost-effective practice.
Underneath presents good visual notations:
 자바 ORM 표준 JPA 프로그래밍 - 기본편
Available at here
자바 ORM 표준 JPA 프로그래밍 - 기본편
Available at here
✔️ Dirty Checking
✔️
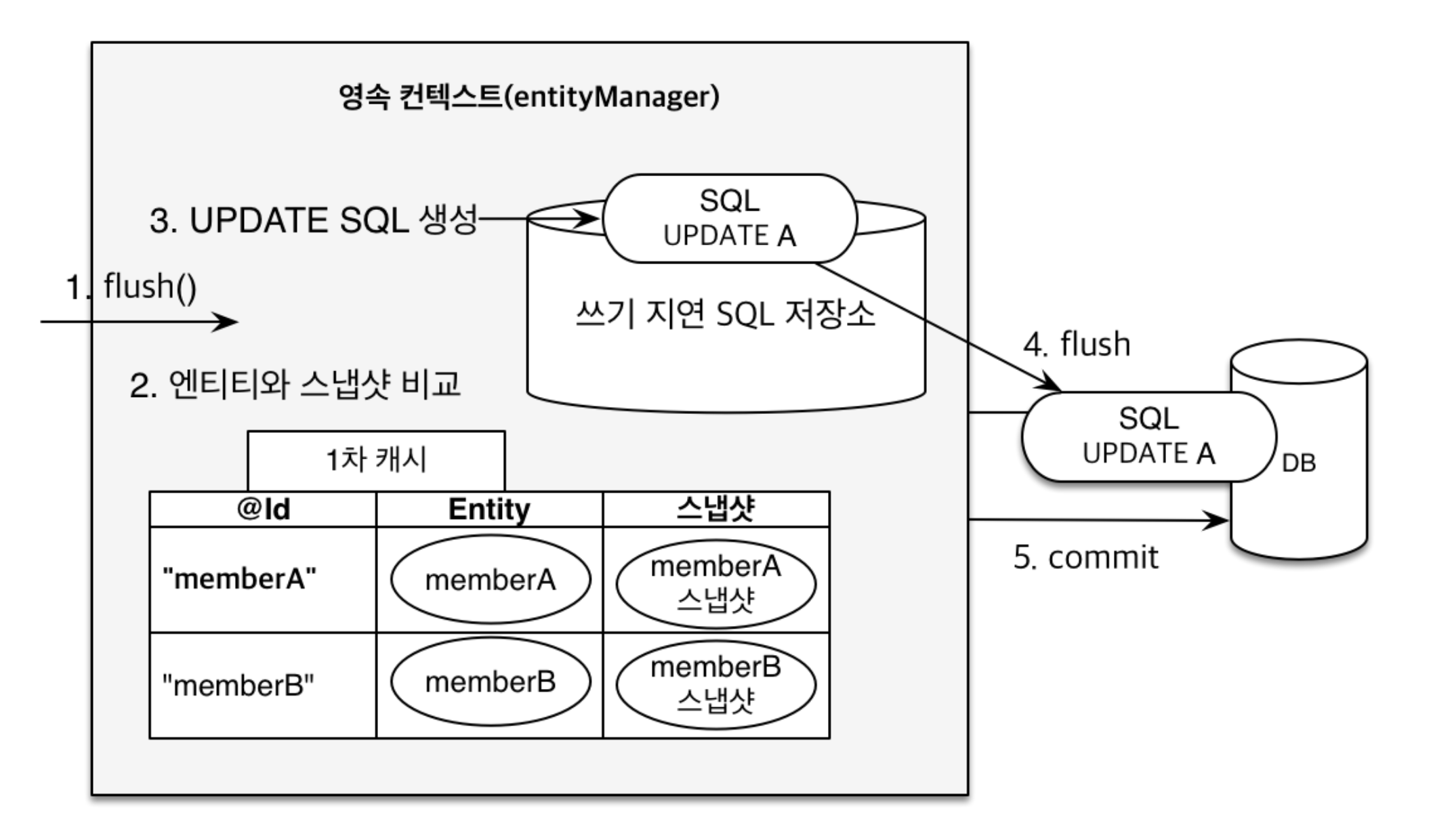
Dirty Checkingis amechanismthat apersistence contexttracks changes over themanaged entities.
Dirty Checking was introduced following inconvenience and performance issues related to changes over entities where an update SQL query had to be created for every entity update:
Updates
Item item = em.find(Item.class 1L);
item.setName("Hello"); -> UPDATE ... SET NAME = ?
item.setQuantity(1); -> UPDATE ... SET QUANTITY = ? Dirty Checking prevents the above inefficiency by introducing the snapshot of an entity where the snapshot refers to the initial version of the entity from a database. Persistence context then compares the snapshot to the entity with the final updates and constructs a single SQL UPDATE statement.
 자바 ORM 표준 JPA 프로그래밍 - 기본편
Available at here
자바 ORM 표준 JPA 프로그래밍 - 기본편
Available at here
🚽 Flush
🚽
Flushrefers to aJPAmechanism where all the updates within apersistence contextbecomes reflected to adatabase.
Flush does not necessarily empty a persistence context, but simply synchronises all the latest changes over managed entities that is persisted as transactional write-behind to a database.
Flush can be invoked by as below:
em.flush()- manualtransaction commit- autoJPQL query execution- auto
and flushing options can be altered in accordance to developers' demand via entity manager's setFlushMode setter().
JPA (flush)
em.setFlushMode(FlushModeType.AUTO) // default
em.setFlushMode(FlushModeType.COMMIT) // manual flush📚 References
