🚒 JPA N + 1 Problem
🚒 JPA N + 1 Problemrefers to aphenomenonin which if anentitywithreferencesbecomes retrieved (1), extraSQL queriesbecome further invoked by the number of alreadyretrieved entitiesordata(N).
For instance, given a Member entity and an Order entity where their relations are One to Many (Member - Order), and further given that all members become retrieved (e.g. 10 members), there could be further 10 plus extra SQL queries to retrieve Order entities strictly relevant to the retrieved members thereby becoming N (orders) + 1(member) while the optimisation would be retrieving all related data at once by sending a SQL query formed in join statements.
Below presents the entities, repository interface, and the stored data that will be used to clarify the JPA N + 1 problem:
Member
@Entity
@Getter @Setter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "username")
private String name;
@OneToMany(mappedBy = "member")
private List<Order> orders = new ArrayList<>();
}Order
@Entity
@Getter @Setter
@Table(name = "orders")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Order {
@Id @GeneratedValue
private Long id;
@ManyToOne
@JoinColumn(name = "member_id")
private Member member;
@Column(name = "total_cost")
private BigDecimal totalCost;
}MemberRepository
public interface MemberRepository extends JpaRepository<Member, Long> {
}Data
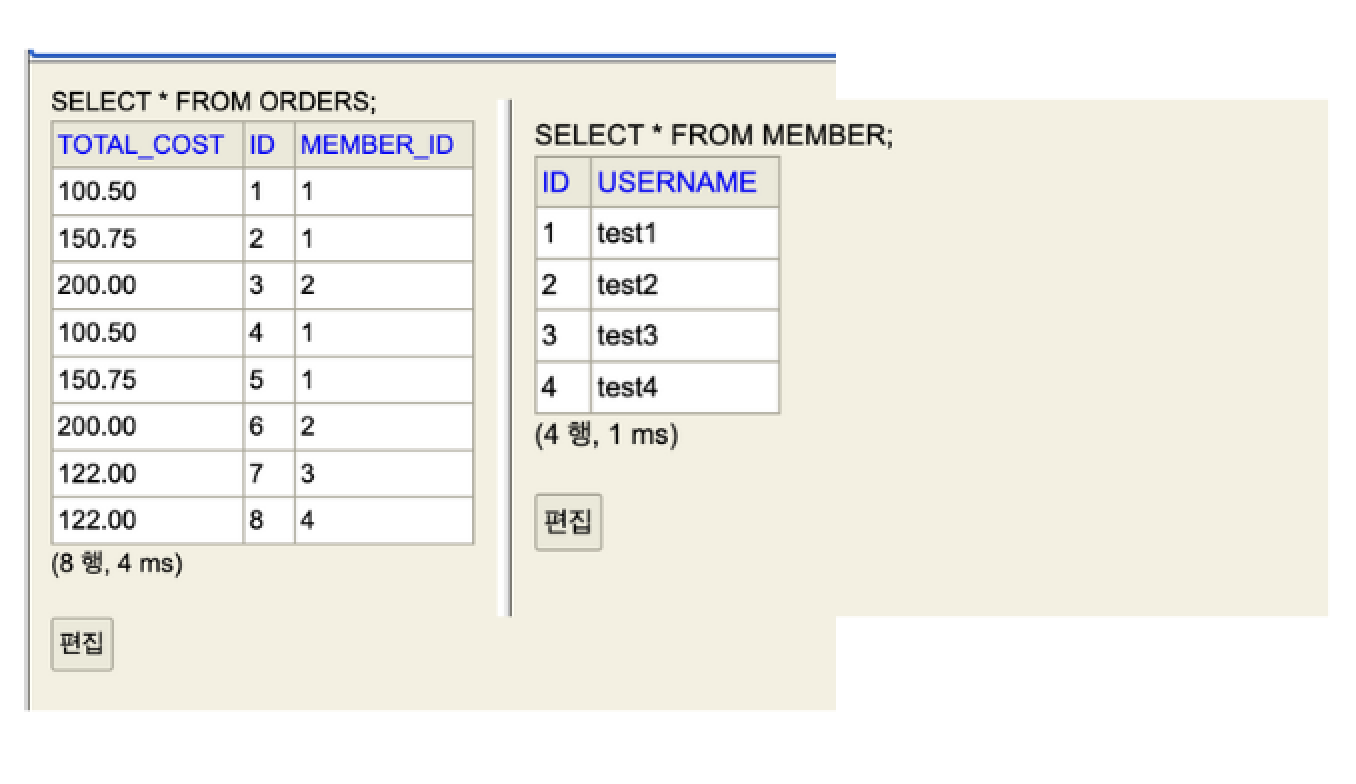
💡 Notes
🚒 JPA N + 1 Problemoccurs regardless of thefetching strategydefined in theN to N annotations.
❤️🔥 EAGER
For instance, with EAGER strategy where all the references become retrieved at the event of a referencing data becoming retrieved, two distinct behaviours can be observed depending on the:
- 🚴♀️🏃
Entity Manager - 🏭
JPQL
Underneath represents a member class with the EAGER strategy:
Member
@Entity
@Getter @Setter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "username")
private String name;
@OneToMany(mappedBy = "member", fetch = FetchType.EAGER)
private List<Order> orders = new ArrayList<>();
}🚴♀️🏃 Entity Manager
A data retrieval via Entity Manager, only allows a single data retrieval, and as the below SQL presents, all required references that are defined as EAGER become fetched with join statement, implying there is no N + 1 problem.
Entity Manager
em.find(Member.class, 1L);SQL
select
m1_0.id,
m1_0.username,
o1_0.member_id,
o1_0.id,
o1_0.total_cost
from
member m1_0
left join
orders o1_0
on m1_0.id=o1_0.member_id
where
m1_0.id=? 🏭 JPQL
Over JPQL, however, followed by its internal logics creating SQL queries in which it may not be always optimised, for all member retrieval calls involving 4 members retrieval, extra 4 SQL queries on orders becomes invoked without any join statements, leading to N + 1 problem.
JPQL
@Test
void findMemberOrderEager() {
List<Member> members = memberRepository.findAll();
// or
List<Member> members = em.createQuery("SELECT m FROM Member m", Member.class)
.getResultList();
}SQL
select
m1_0.id,
m1_0.username
from
member m1_0
select
o1_0.member_id,
o1_0.id,
o1_0.total_cost
from
orders o1_0
where
o1_0.member_id=?
select
o1_0.member_id,
o1_0.id,
o1_0.total_cost
from
orders o1_0
where
o1_0.member_id=?
select
o1_0.member_id,
o1_0.id,
o1_0.total_cost
from
orders o1_0
where
o1_0.member_id=?
select
o1_0.member_id,
o1_0.id,
o1_0.total_cost
from
orders o1_0
where
o1_0.member_id=?😎 Lazy
LAZY refers to a fetch strategy, strictly opposite to EAGER in which LAZY invokes any retrieval data calls on references whenever necessary. Meanwhile in the persistence context, it fills a proxy instance for the references.
Underneath could be a member class with the LAZY strategy:
Member
@Entity
@Getter @Setter
@NoArgsConstructor
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "username")
private String name;
@OneToMany(mappedBy = "member", fetch = FetchType.LAZY)
private List<Order> orders = new ArrayList<>();
}Under the context Lazy strategy, regardless of any JPA standardised data retrieval contexts, a single SQL query for members will be dispatched.
Entity Manager & JPQL
@Test
void findMemberOrderLazy() {
Member member = em.find(Member.class, ID);
List<Member> members = memberRepository.findAll();
// or
List<Member> members = em.createQuery("SELECT m FROM Member m", Member.class)
.getResultList();
}SQL
select
m1_0.id,
m1_0.username
from
member m1_0 Hence, the N + 1 problem appears to have been solved by setting a fetch strategy to Lazy.
N + 1 problem still persist at the acutal reference retrievals, regardless of data retrieval contexts where it may be clear from given the below loop:
Entity Manager & JPQL
@Test
void findMemberOrderLazy() {
List<Member> members = memberRepository.findAll();
// or
List<Member> members = em.createQuery("SELECT m FROM Member m", Member.class)
.getResultList();
for (Member member : members) {
for (Order order : member.getOrders()) {
System.out.println("order.getId() = " + order.getId());
}
}
}SQL
select
m1_0.id,
m1_0.username
from
member m1_0
select
o1_0.member_id,
o1_0.id,
o1_0.total_cost
from
orders o1_0
where
o1_0.member_id=?
select
o1_0.member_id,
o1_0.id,
o1_0.total_cost
from
orders o1_0
where
o1_0.member_id=?
select
o1_0.member_id,
o1_0.id,
o1_0.total_cost
from
orders o1_0
where
o1_0.member_id=?
select
o1_0.member_id,
o1_0.id,
o1_0.total_cost
from
orders o1_0
where
o1_0.member_id=?👏 Solutions
Hence, the above analysis could be summarised into:
🗒️ Summary
Regardless of
fetch strategies, eitherEAGERandLAZY,JPAcould potentially incurN + 1 problemsleading to considerableperformance issues.
JPA N + 1 could be addressed by underneath approaches:
- 👫
FETCH JOIN - 🚛
Batch - 🎯
@Fetch(FetchMode.SUBSELECT) - ፨
Entity Graph
where these will be discussed in the following sections.
👫 FETCH JOIN
👫
FETCH JOINis aJPQL syntaxwhereFETCH JOINoptimisesinstructedjoin statements, maps all thereferenced dataas anentity, and stores it in apersistence context.
FETCH JOIN can be used in any join context from One to One, to One to Many relationships:
Fetch Join
public interface MemberRepository extends JpaRepository<Member, Long> {
@Override
@Query("SELECT m FROM Member m LEFT JOIN FETCH m.orders")
public List<Member> findAll();
@Override
@Query("SELECT m FROM Member m LEFT JOIN FETCH m.orders LEFT JOIN FETCH m.lockers")
public List<Member> findAllMemberWithOrdersAndLockers();
}Regarding, collection fetch joins referring to One to Many and Many to Many relationships, there are two points to further consider.
- 1)
SELECT DISTINCT - 2)
Cartesian Product
1) SELECT DISTINCT (Before Hibernate 6)
FETCH JOIN on One to Many over a collection leads the resulting table to have duplicate entities, followed by normalisation. Hence, if, for instance, looped, the identical entity can be retrieved multiple times.
SELECT DISTINCT in JPQL implies that any duplicate data with the same identity can be compressed into a single entity:
SELECT (FETCH JOIN)
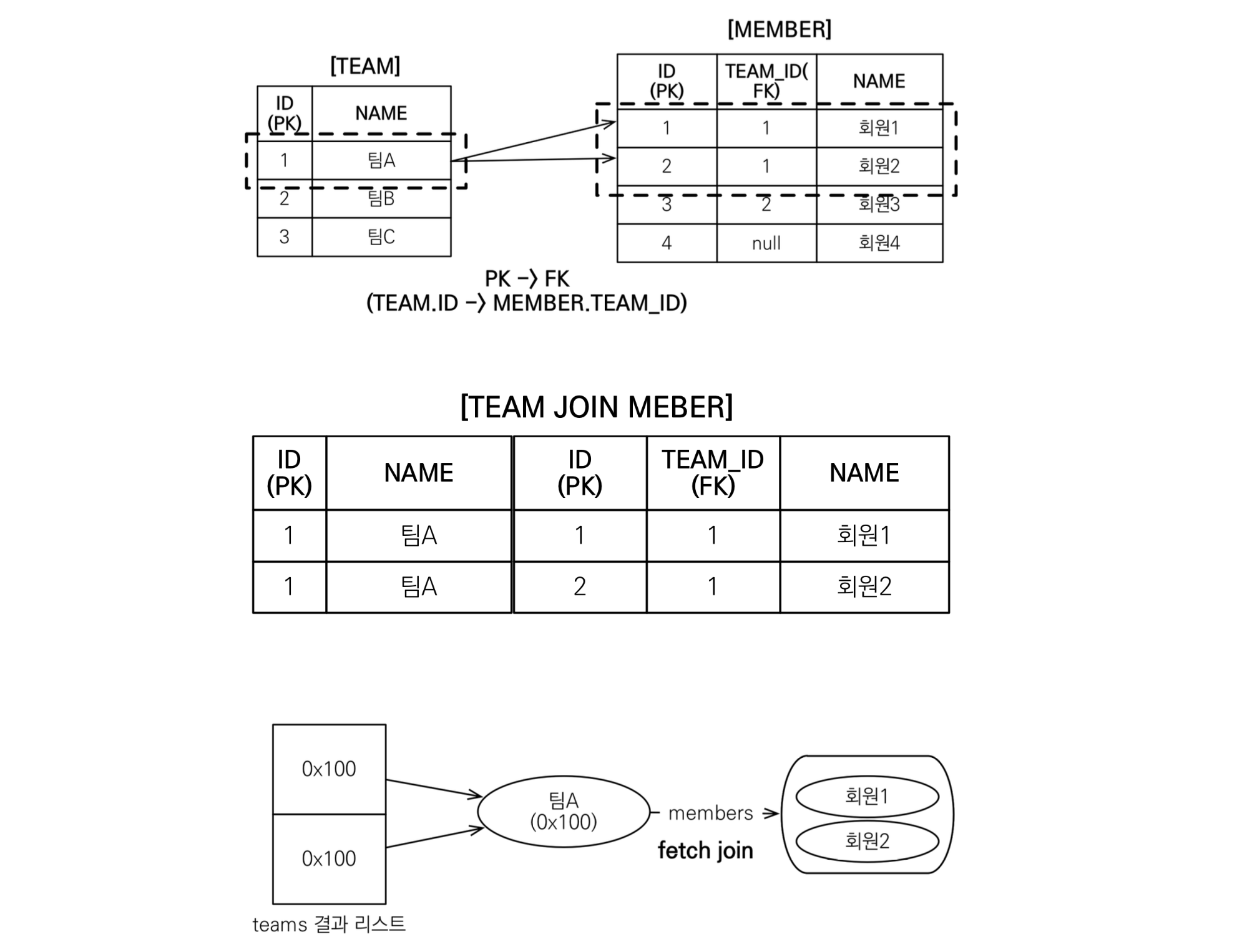 자바 ORM 표준 JPA 프로그래밍 - 기본편
Available at here
자바 ORM 표준 JPA 프로그래밍 - 기본편
Available at here
SELECT DISTINCT (FETCH JOIN)
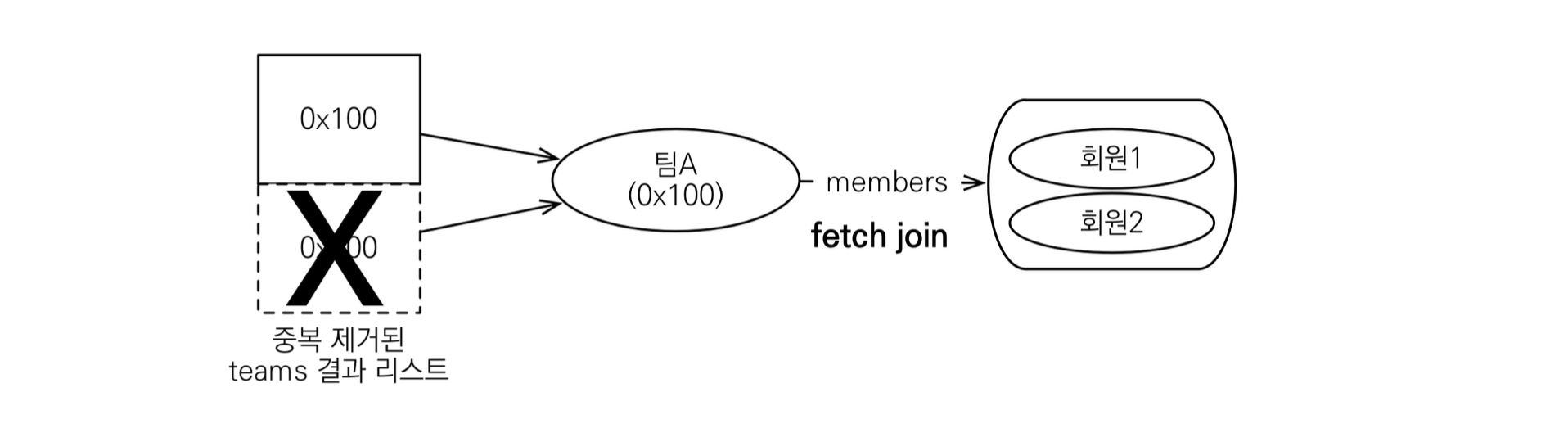 자바 ORM 표준 JPA 프로그래밍 - 기본편
Available at here
자바 ORM 표준 JPA 프로그래밍 - 기본편
Available at here
2) Cartesian Product
Cartesian Product refers to a phenomenon where the joined data in a table sizes up to a multiplication of all rows over all the joined tables. In JPQL, Cartesian Product occurs over multiple joins on - to Many (collections) relationships, implying it is advisable to only fetch join a single collection for the performances.
🗒️ Notes
By default
multiple fetch joinsonmultiple collectionsis prevented whereMultipleBagFetchExceptionoccurs if such event occurs.
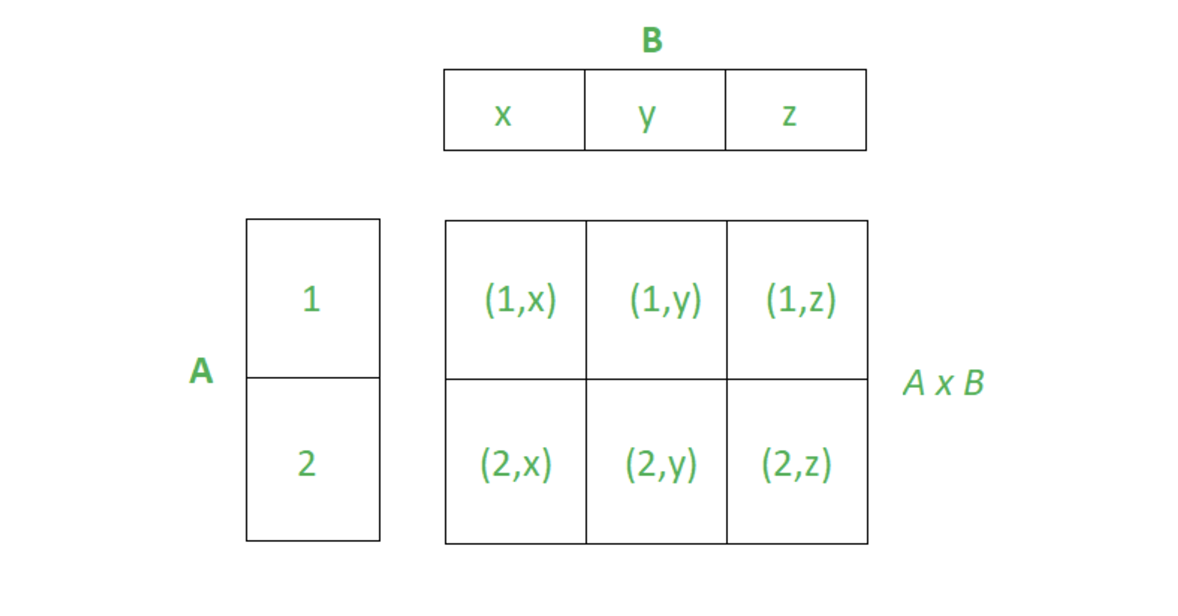 Geeks for Geeks
Available at here
Geeks for Geeks
Available at here
🚛 BATCH
🚛
BATCH fetchingis a feature provided byHibernateto optimisedata retrievalwhen dealing with relationships that arelazy-loaded.By default,
lazy loadingcan lead to theN+1 problem, butBATCH fetchinghelps reduce thisoverheadbygrouping the fetchingof relatedentitiesinchunks..
To enable Batch fetching, @BatchSize annotation can be preseted above the field or a class within the reltionships:
Member (@BatchSize field)
@Entity
@Getter @Setter
@NoArgsConstructor
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "username")
private String name;
@BatchSize(size = 2)
@OneToMany(mappedBy = "member", fetch = FetchType.LAZY)
private List<Order> orders = new ArrayList<>();
}where the @BatchSize(size = N) defined in any fields applies to the orders collection in the Member entity.
Order (@BatchSize class)
@Entity
@Getter @Setter
@Table(name = "orders")
@BatchSize(size = 5)
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Order {
@Id @GeneratedValue
private Long id;
@ManyToOne
@JoinColumn(name = "member_id")
private Member member;
@Column(name = "total_cost")
private BigDecimal totalCost;
}and @BatchSize(size = N) defined in any classes applies to all instances of the Order entity. Specifically it optimises lazy loading for Order entities in any relationship that references them.
Underneath presents the actual code snippet where the above @BatchSize is applied:
JPQL (@BatchSize)
@Test
void findMemberBatch() {
List<Member> members = em.createQuery("SELECT m FROM Member m", Member.class)
.getResultList();
// or
List<Member> members = memberRepository.findAll();
System.out.println("MEMBER " + members.get(0).getId());
// MEMBER 1
for (Order order : members.get(0).getOrders()) {
System.out.println("order.getId() = " + order.getId());
System.out.println("order.getTotalCost() = " + order.getTotalCost());
}
// order.getId() = 1
// order.getTotalCost() = 100.50
// order.getId() = 2
// order.getTotalCost() = 150.75
// order.getId() = 4
// order.getTotalCost() = 100.50
// order.getId() = 5
// order.getTotalCost() = 150.75
}SQL (@BatchSize)
select
m1_0.id,
m1_0.username
from
member m1_0
select
o1_0.member_id,
o1_0.id,
o1_0.total_cost
from
orders o1_0
where
o1_0.member_id in (?, ?, ?, ?, ?)🎯 @Fetch(FetchMode.SUBSELECT)
🎯
@Fetch(FetchMode.SUBSELECT)modifies the default behaviour oflazy loadingby using asubquery (subselect), which allows for a more efficient way offetching related entities.
Below contains code snippets of @Fetch(FetchMode.SUBSELECT):
Member (@Fetch(FetchMode.SUBSELECT))
@Entity
@Getter @Setter
@NoArgsConstructor
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "username")
private String name;
@OneToMany(mappedBy = "member", fetch = FetchType.LAZY)
@Fetch(FetchMode.SUBSELECT)
private List<Order> orders = new ArrayList<>();
}JPQL (@Fetch(FetchMode.SUBSELECT))
@Test
void findMemberSubselect() {
List<Member> members = em.createQuery("SELECT m FROM Member m", Member.class)
.getResultList();
// or
List<Member> members = memberRepository.findAll();
}SQL (@Fetch(FetchMode.SUBSELECT))
select
o1_0.member_id,
o1_0.id,
o1_0.total_cost
from
orders o1_0
where
o1_0.member_id in (select
m1_0.id
from
member m1_0)፨ Entity Graph
፨
Entity GraphinJPAis amechanismto define and control how relatedentitiesare fetched from thedatabase.
Entity Graphdefines whichattributesandrelationships(associations) should beeagerly loadedwhen querying anentity, overriding the defaultfetch strategydefined in theJPA mappings(FetchType.LAZYorFetchType.EAGER) at runtime.
Entity Graphs can be either stated statically over the @Entity or dynamically over the queries including the JPQL queries from the JPA repositories, or the user-specified queries followed by @Query.
Entity graphs enables the fetching associations and strategies to be determined at the runtime without necessarily modifying the already written JPQL or Criteria queries and statically declared fetching relationships over the entities.
Hence, entity graphs results in the data fetching to be more:
- 🦑
flexible - ♻️
reusable - 🔔
declarative (user point of view)
Examples below specifies how statically and dynamically @EntityGraphs can be used over JPA:
Member (@EntityGraph)
@Entity
@Getter @Setter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@NamedEntityGraph(
name = "Member.all",
attributeNodes = {
@NamedAttributeNode("orders"),
@NamedAttributeNode("team")
}
)
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "username")
private String name;
@OneToMany
private Team team;
@OneToMany(mappedBy = "member", fetch = FetchType.EAGER)
private List<Order> orders = new ArrayList<>();
} MemberRepository (@EntityGraph)
public interface MemberRepository extends JpaRepository<Member, Long> {
@EntityGraph("Member.all")
public List<Member> findEntityGraphByUserName(@Param("username") String username);
@Override
@EntityGraph(attributePaths = { "orders" })
public List<Member> findAll();
@EntityGraph(attributePaths = { "orders" })
public List<Member> findEntityGraphByUserName(@Param("username") String username);
@EntityGraph(attributePaths = { "order" })
@Query("SELECT m FROM Member m)
List<Member> fetchMembers();
}🗒️ Notes
Like
Fetch Join,multiple fetch joinsonmultiple collectionsis prevented whereMultipleBagFetchExceptionoccurs if such event occurs.
🦠 Practices (FETCH JOINS on Collections)
As noted, fetch joins via 👫 FETCH JOIN or ፨ ENTITY GRAPHS over multiple collections incurs MultipleBagFetchException followed by it producing cartesian products of all rows, thereby potentially incurring OutofMemory Exception.
One easiest approach to address this, if multiple fetches join over the multiple collections is necessary is using Set instead of List data ~N (One to Many, Many to Many) relationships.
Set can pose performance issues as Set needs to eliminate duplicates, which means it has to compare with existing data to check for duplicates. While this isn't usually a major problem, it becomes an issue when dealing with lazy-loaded collections.
Specifically, if a collection is uninitialised and a value is added to it, the proxy is forced to initialise (Eagerly Fetch the data), leading to Lazy Loading to have no implications on the overall functioning. This happens because Set requires the entire collection to perform the duplicate check.
On the other hand, *List does not require this duplicate check. Therefore, adding data to a List does not trigger initialisation fitting to the purpose of Lazy Loading. However, MultipleBagFetchException may persist over the multiple fetches joins over the multiple collections.
🕵️♀️ Solution
The potential and widespread solution to the MultipleBag issue is letting N + 1 to occur or perhaps optimise N + 1 via 🚛 @BatchSize, the approach that fetches the data in chunks. 🎯 @Fetch(FetchMode.SUBSELECT) can also become a good solution.
MultipleBag issue is simply unavoidable such that the optimal strategy is to fetch collective associations of ~N (One to Many, Many to Many) relationships independently but optimally via perhaps 🚛 @BatchSize.
📄 Practices (Paging Issues)
Above approaches: 👫 FETCH JOIN and ፨ Entity Graph appear to have critical issues in Paging via offset and limit keywords in SQL.
📄 Paging issues arise in circumstances in which references of ~N (One to Many, Many to Many) become eagerly fetched, leading to fetched data in rows to have bigger rows.
A good example could be below:
Member
@Entity
@Getter @Setter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "username")
private String name;
@OneToMany(mappedBy = "member")
private List<Order> orders = new ArrayList<>();
}Order
@Entity
@Getter @Setter
@Table(name = "orders")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Order {
@Id @GeneratedValue
private Long id;
@ManyToOne
@JoinColumn(name = "member_id")
private Member member;
@Column(name = "total_cost")
private BigDecimal totalCost;
}MemberRepository
public interface OrderRepository extends JpaRepository<Order, Long> {
@EntityGraph(attributePaths = { "orders" })
@Query("SELECT m FROM Member m")
List<Member> findAllMembersWithEntityGraphOrders(Pageable pageable);
@Query("SELECT m FROM Member m JOIN FETCH m.orders o")
List<Member> findAllMembersWithFetchJoinOrder(Pageable pageable);
}where given the earliest entities: Member and Order entities, Paging issue occurs when Member eagerly fetches related Order entities either via provided FETCH JOIN or Entity Graph. This underlies the relationship between the two entities: Order and Member where from Member, Order has a ~N (One to Many, Many to Many) relationship to Member thereby producing the bigger combined rows.
LOG & SQL
HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory select
m1_0.id,
m1_0.locker_id,
m1_0.username,
o1_0.member_id,
o1_0.id,
o1_0.total_cost
from
member m1_0
join
orders o1_0
on m1_0.id=o1_0.member_idResults
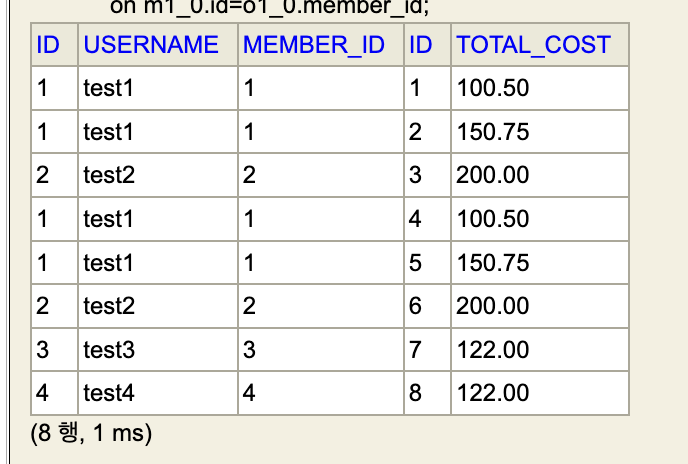
Specifically, the above is the SQL query and the SQL results followed by the execution of two methods in the MemberRepository interface, and it may be clear that SQL syntax applying pagination, offset and limit, is not present over the executed SQL query.
This simply occurs following the normalisation in RDMBS as the combined data has to have non-duplicating rows over their unique keys, resulting in 8 rows from the Orders to override 4 rows in Members and applying offset and limit over these combined rows may have non-intended results from a developer in which specifically, given limit 2 the fetched rows will be the first two rows with the first member, test1 than the intended first two members, test1 and test2.
Hence to address this and to enable paging, JPA processes the above table results in memory and applies paging. This, however, potentially poses performance issues or a server failover if there happens to be a lot of data (eg. billions).
🕵️♀️ Solution
The potential and widespread solution to the Paging issue is 🚛 @BatchSize, the approach that has been already discussed above as it fetches the data if relevant but in chunks, thereby eliminating the necessity of the fetch joins via 👫 FETCH JOIN or ፨ ENTITY GRAPHS
🔍 Conclusive Analysis
🚒 JPA N + 1 problem and its solution have been discussed in the above sections. Designing an optimal data fetching strategy is always critical if considering the related costs to connect with the database.
Developers, however, have to always consider the possibility of data fetching logic being over-engineered as frequently, letting the N + 1 problem occur could be a better solution than eagerly fetching the data. Hence, careful examinations and tests over the test servers could be important.
📚 References
자바 ORM 표준 JPA 프로그래밍 - 기본편 (김영한)
자바 ORM 표준 JPA 프로그래밍
Geeks for Geeks
