랜덤포레스트 모델을 통한 보드게임 추천 웹앱 배포
(코드스테이츠 데이터 엔지니어링 섹션 개인 프로젝트)
- 진행 기간: 8월 24일 ~ 8월 30일
- 사용 언어: Python, MySQL
- 프로젝트 발표 영상
- github 주소
프로젝트 개요
랜덤포레스트 모델을 통한 보드게임 추천 웹앱 배포
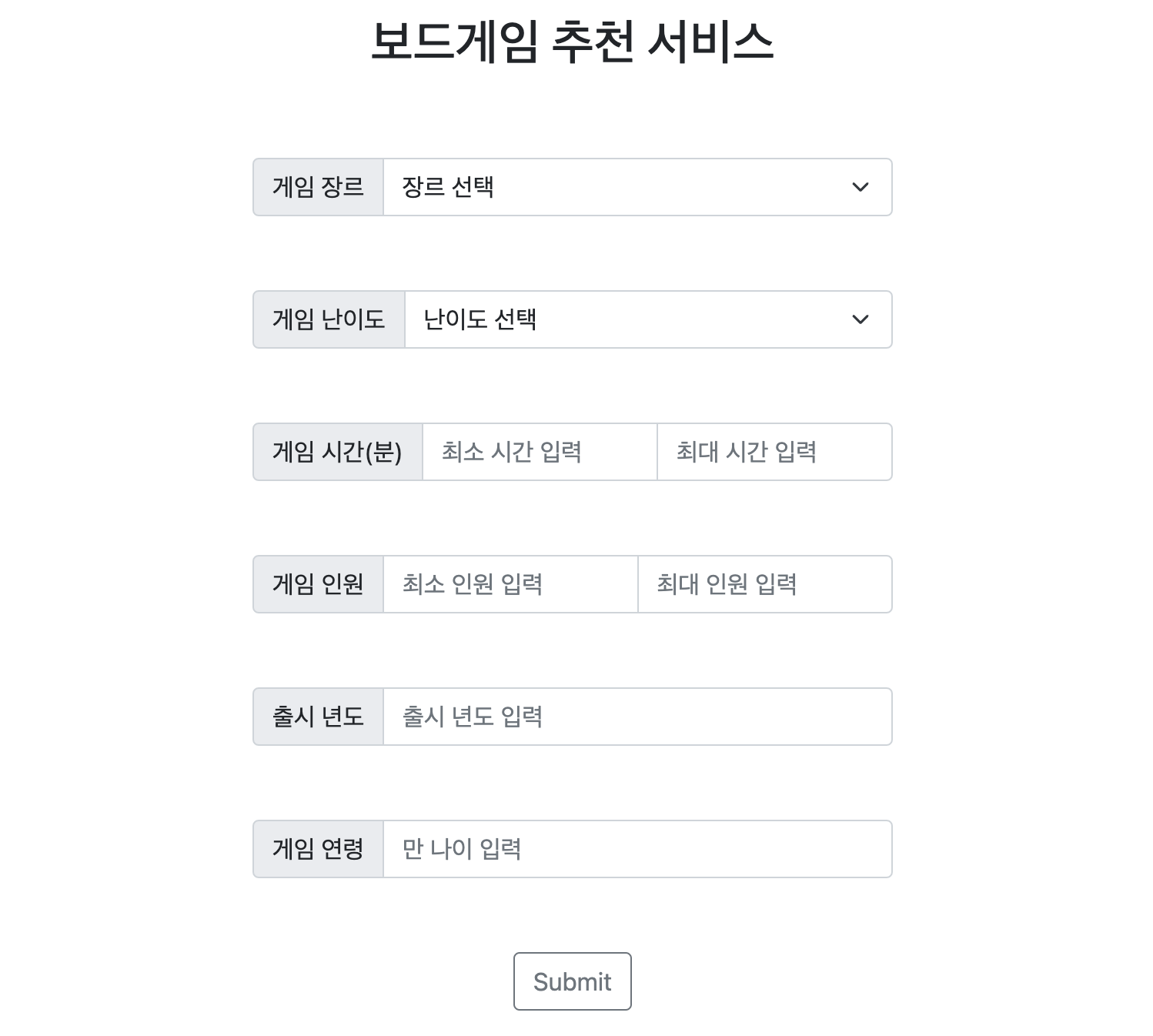
원하는 보드게임 조건(게임 장르, 난이도, 시간, 인원, 출시 년도, 연령)을 입력하면 보드게임을 추천해주는 웹 API 서비스 개발 및 배포.
클라우드 DB를 구축해 데이터를 저장하고, 적재된 데이터를 활용해 ML 모델을 포함한 서비스를 개발 및 배포하기까지의 파이프라인을 구축하는 프로젝트입니다.
- Board Game Geek의 데이터를 정리해서 저장해 놓은 CSV파일을 Kaggle에서 다운 받아 이용하고 PostgreSQL에 적재하였습니다.
psycopg2를 이용하여 적재 데이터에 연결하고 보드게임을 예측해주는 머신러닝 모델을 만들고, 이 모델을Pickling하였습니다.- Flask를 사용하여 훈련된 ML 모델을 serving하고, Heroku를 통해 서비스를 배포하였습니다.
- Tableau를 사용하여 데이터 분석 시각화 및 대시보드를 제공하였습니다.
-
서비스 파이프라인은 아래와 같습니다.

-
서비스 핵심 기능의 모습은 아래와 같습니다.
문제 정의
[문제 상황]
- 최근에 보드게임을 즐기는 사람이 늘어남에 따라 보드게임 카페가 활성화되기 시작했습니다.
- 세상에 보드게임의 종류가 너무 많고 장르가 다양하여 보드게임 카페 직원이 모든 고객들의 니즈를 충족시키며 쉽게 추천해주기 어렵다고 판단하였습니다.
- 하지만 여러 보드게임 카페에서 실행되고 있는 추천 웹서비스가 존재 하지 않았습니다. 따라서 보다 편리하게 일을하고 동시에 손님의 요청을 빨리 받아드릴 수 있도록 서비스를 제작하였습니다.
사용한 데이터셋
[필요한 데이터셋]
- ML 모델 학습을 위한 보드게임 정보가 다양한 데이터 셋
- 결과물로 이미지 출력을 위해 이미지 또한 보함되어 있어야하는 데이터 셋
[선정한 데이터셋]
- 보드게임긱 이라는 유명 해외사이트에서 API를 통해 저장한 csv 파일 데이터 셋 (kaggle에서 다운)
데이터 저장
[데이터의 적재]
클라우드 DB인 PostgreSQL에 저장하였는데, 이때
psycopg2라이브러리를 사용하였습니다.
클라우드 DB 생성(ElephantSQL 이용)
클라우드 DB에 데이터 적재하기
import psycopg2 import pandas as pd import database_info #connect to postgresql cloud database conn = psycopg2.connect( host=database_info.host, port=database_info.port, database=database_info.database, user=database_info.user, password=database_info.password) #connect cursor cur = conn.cursor() #create table cur.execute("DROP TABLE IF EXISTS BoardGameGeek;") cur.execute("""CREATE TABLE BoardGameGeek( id INTEGER, thumbnail VARCHAR(256), image VARCHAR(256), game VARCHAR(128), description VARCHAR(16384), yearpublished INTEGER, minplayers INTEGER, maxplayers INTEGER, playingtime INTEGER, minplaytime INTEGER, maxplaytime INTEGER, minage INTEGER, boardgamecategory VARCHAR(256), usersrated INTEGER, average FLOAT, bayesaverage FLOAT, rank INTEGER, averageweight FLOAT ) """) #read csv file from local computer df = pd.read_csv('/Users/kyoh/Downloads/Section3/project3/project3_heroku/board_games_info.csv') #make meaningful dataframe with valualble columns from the whole dataset df = df[["id","thumbnail","image","primary","description","yearpublished","minplayers","maxplayers","playingtime","minplaytime", "maxplaytime","minage","boardgamecategory","usersrated","average","bayesaverage","Board Game Rank","averageweight"]] #only need 0-1000 most reviewed(famous) games df = df[0:1000] #save new csv file # df.to_csv("board_game_1000.csv", mode='w') df_list_tuple = list(df.itertuples(index=False, name=None)) sql = """INSERT INTO BoardGameGeek (id, thumbnail, image, game, description, yearpublished, minplayers, maxplayers, playingtime, minplaytime, maxplaytime, minage, boardgamecategory, usersrated, average, bayesaverage, rank, averageweight) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)""" #load dataset into the database(postgresql) cur.executemany(sql, df_list_tuple) conn.commit()#데이터베이스 안에 확정지어 적재 cur.close() conn.close()
ML 모델 개발
[모델 선택]
- 이번 서비스에 사용할 ML 모델로는 랜덤 포레스트 모델을 선택하였습니다.
이번 프로젝트의 목표는 전체적인 데이터 파이프라인을 구축해보는 것으로, ML 모델이 높은 성능을 내도록 하는 것은 주목표가 아니었습니다.- 따라서 빠르게 구축할 수 있으며 비교적 고성능의 기능을 낼 수 있는 랜덤 포레스트 모델을 사용했고, 하이퍼 파라미터 최적화 등의 작업은 이번 프로젝트 간 수행하지 않았습니다.
[진행 과정]
- DB에 저장되어 있는 데이터를 가져와 학습시키기 위해
sklearn라이브러리를 이용하였습니다.# 모델링 pipe = make_pipeline( OrdinalEncoder(handle_missing="value"), SimpleImputer(), RandomForestClassifier() ) #fit the model pipe.fit(X, y)
- 추후 웹 앱에서 해당 모델을 사용하기 위해
피클링(Pickling)하였습니다. (= 모델 인코딩)#피클링(pickling) with open('model.pkl','wb') as pickle_file: pickle.dump(pipe, pickle_file)
API 서비스 개발 및 배포
[API 서비스 개발]
- 웹 어플리케이션 개발은
Flask를 이용하여 진행하였습니다.- 이 과정에서 피클링했던 ML 모델을 디코딩하였고(=언피클링)
- 사용자가 입력한 조건(게임 장르, 난이도, 시간, 인원, 출시 년도, 연령)에 알맞는 보드게임을 추천해 줄 수 있도록 개발하였습니다.
- 출력 페이지
[배포]
Heroku를 통해 로컬 뿐 아니라 다른 환경에서도 웹 접속이 가능하도록 배포까지 진행하였습니다.
[Web APP] 보드게임 추천 웹앱 링크

대시보드 구현
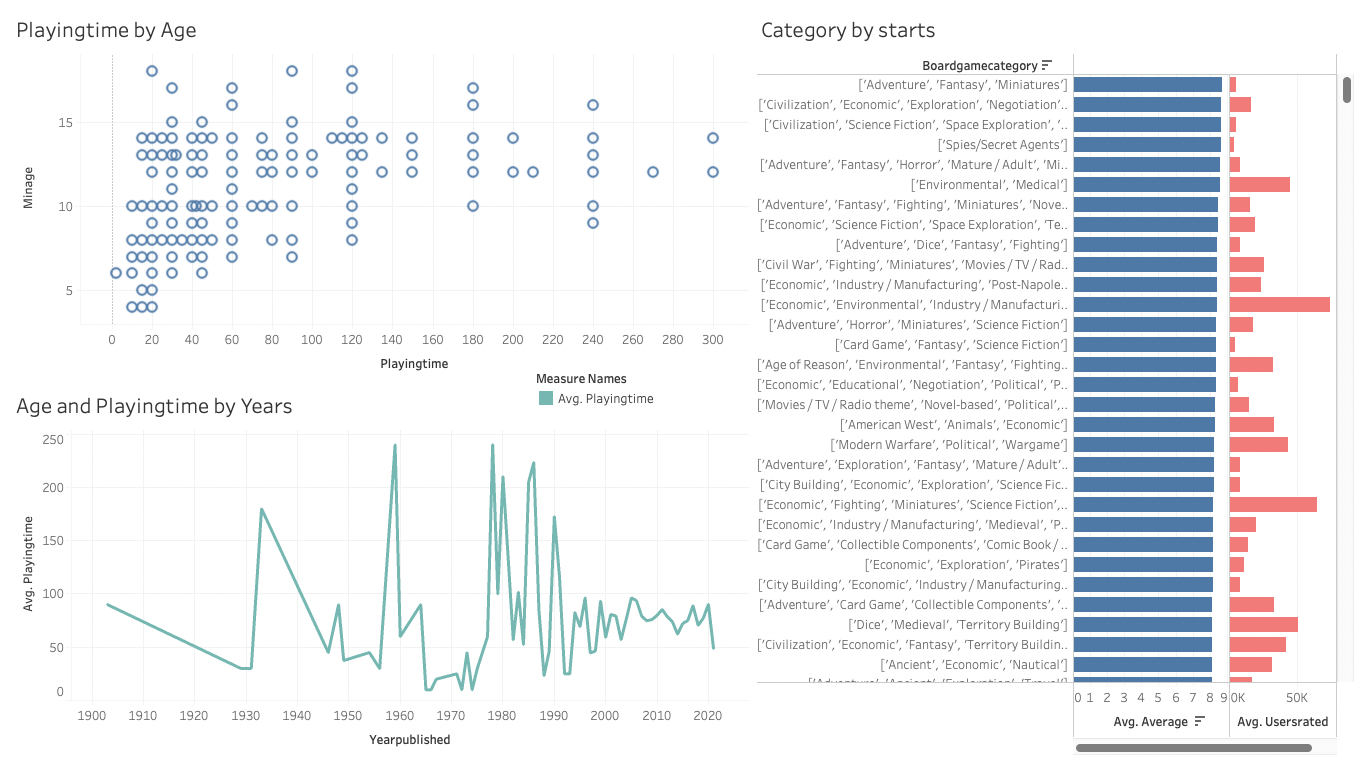
[대시보드]
Tableau라는 BI툴을 이용하여 구축한 DB를 연결해서 의미 있는 그래프들을 만들었습니다.- 그래프들을 모아 대시보드를 제작하였습니다.
향후 목표
- 이번 프로젝트의 포커스가 전체적인 데이터 파이프라인을 구축해보는 것으로 맞춰져 있었기에, ML 모델과 관련해 개선할 필요성을 느꼈다. 랜덤 포레스트 모델을 사용하였는데, 좀 더 정확한 예측이 가능하도록 모델 최적화 필요(하이퍼 파라미터 튜닝)
Heroku를 통한 배포 필요구현 완료!

Studying for Data Analysis, Data Engineering & Data Science
안녕하세요! 보드게임을 좋아해서 개인 사이드 프로젝트를 위해 검색 중에 발견했습니다ㅎㅎ 글 잘 읽고갑니다!