AI Bootcamp
1.[Section0] 나만의 사전
from google.colab import filesfiles.upload()df = pd.read_csv('datadata.csv')
2.[Section1 Sprint1] EDA

https://github.com/KYOH95/ds-section1-sprint1-newEDAData PreprocessingFeature EngineeringBusiness InsightData Wrangling데이터 수집데이터 탐색데이터 정제import p
3.[Section1 Sprint2] Statistics
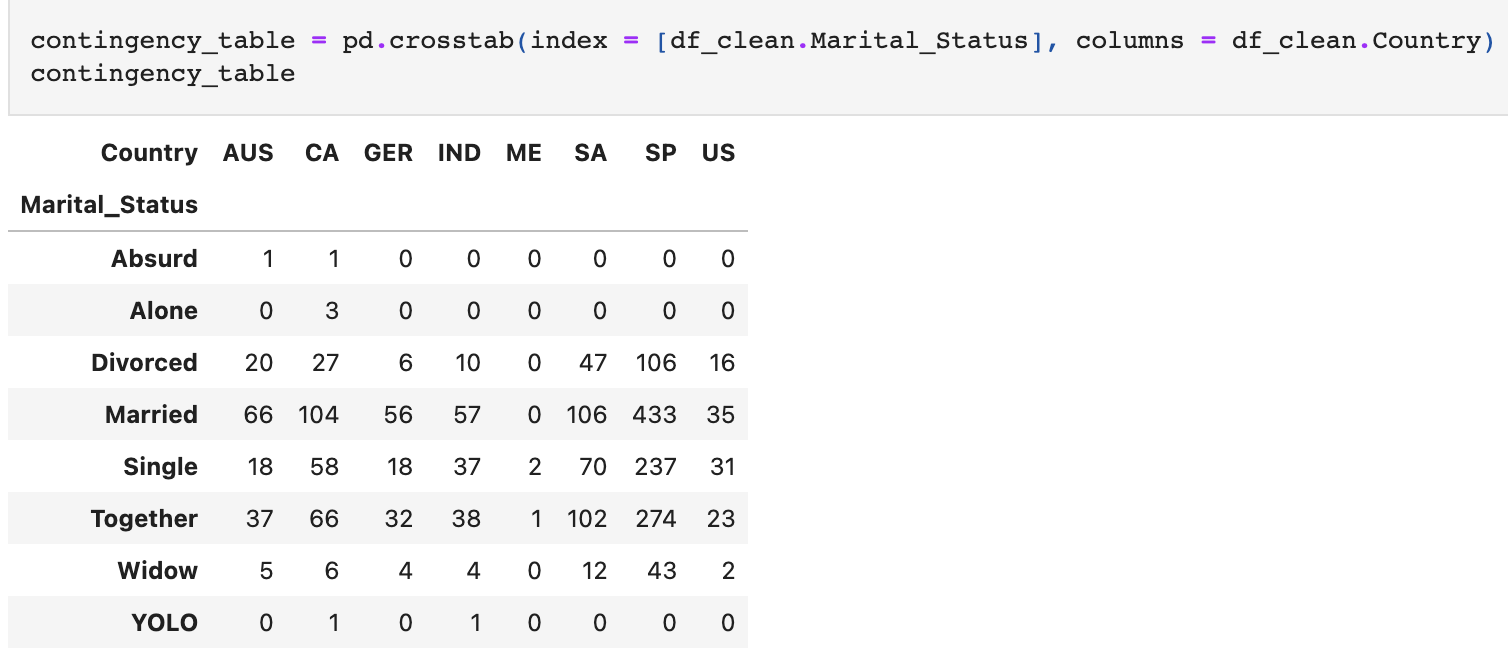
https://github.com/KYOH95/ds-section1-sprint2-newBayesian TheoremConfidence Interval귀무가설(Null Hypothesis)AB Test라이브러리 importimport pandas as pdim
4.[Section1 Sprint3] Linear Algebra
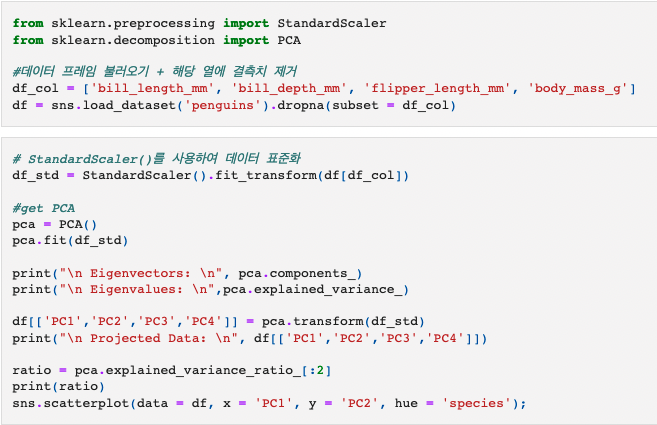
[Section1 Sprint3] Linear Algebra PCA 공분산(Covariance)과 상관계수(Correlation coefficient) 분산: 데이터가 흩어져 있는 정도를 하나의 값으로 나타낸 것(분산값이 클 수록 데이터가 서로 멀리 떨어져 있음) 편
5.[Section2 Sprint1] Linear Models
Logistic Regression
6.[Section2 Sprint2] Tree Based Model
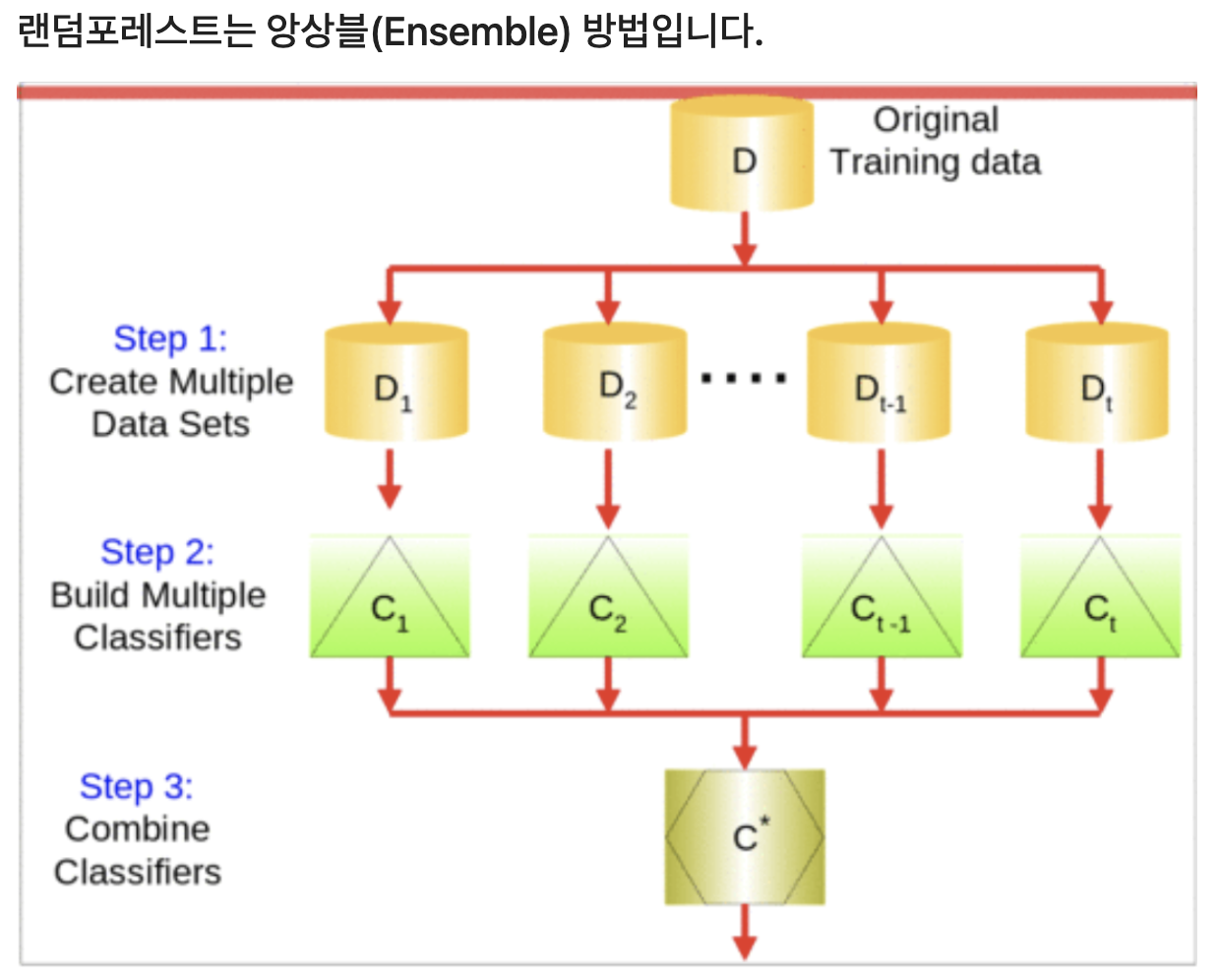
bootstrap 샘플링을 통해 여러개의 데이터 세트를 복원 추출한다.Bagging: Bootstrap Aggregating추출된 여러개의 샘플 세트을 가지고 각각의 '결정트리' 모델을 구현한다.앙상블 구현된 여러개의 '결정트리'들의 모델들의 예측결과를 다수결이나 평균
7.[Section2 Sprint3] Applied Predictive Modeling
8.[Section3 Sprint1] Git, github, Env

git 관련 간단한 문제 풀어보는 웹사이트 프로그램 https://codestates.github.io/sw-sprint-git-workflow/ Git Git은 버전 관리 시스템 (VCS, Version-Control System) 입니다. Git은 로컬에서 작
9.[Section4 Sprint2] 텍스트 전처리, 등장횟수 기반의 단어 표현

10.[Section4 Sprint2] 단어 분산의 표현, Word2Vec

11.[Section4 Sprint3 Day1] CNN, Transfer Learning

12.[Section4 Sprint3 Day2] Segmentation, Object Detection

13.[Section4 Sprint3 Day3] AutoEncoder

14.[Section4 Sprint3 Day4] GAN

15.프로젝트: 보드게임 추천 웹서비스

(코드스테이츠 데이터 엔지니어링 섹션 개인 프로젝트)진행 기간: 8월 24일 ~ 8월 30일사용 언어: Python, MySQL프로젝트 발표 영상은 여기에서 보실 수 있습니다.랜덤포레스트 모델을 통한 보드게임 추천 웹앱 배포원하는 보드게임 조건(게임 장르, 난이도, 시