Section1 Sprint2
https://github.com/KYOH95/ds-section1-sprint2-new
- Bayesian Theorem
- Confidence Interval
- 귀무가설(Null Hypothesis)
- AB Test
1. 데이터셋 업로드
라이브러리 import
import pandas as pd
import numpy as np
import random
import matplotlib.pyplot as plt
import seaborn as sns
google colab에 파일 업로드
from google.colab import files
files.upload()
데이터 읽기
df = pd.read_csv('데이터세트.csv')
df.shape
2. 결측치가 확인 후, 제거
df.isnull().sum()
df.info()
결측치 제거
df = df.dropna(axis=0)
인덱스 리셋
df = df.reset_index(level=None, drop=True, inplace=False, col_level=0, col_fill='')
3. 카이제곱 가설 검정
from scipy.stats import chisquare
특정 컬럼 (조건) 확인
condition = df["칼럼명"] == 1 & df["칼럼명"] > 2
df[condition]
유일 값 찾기
df["칼럼명"].nunique()
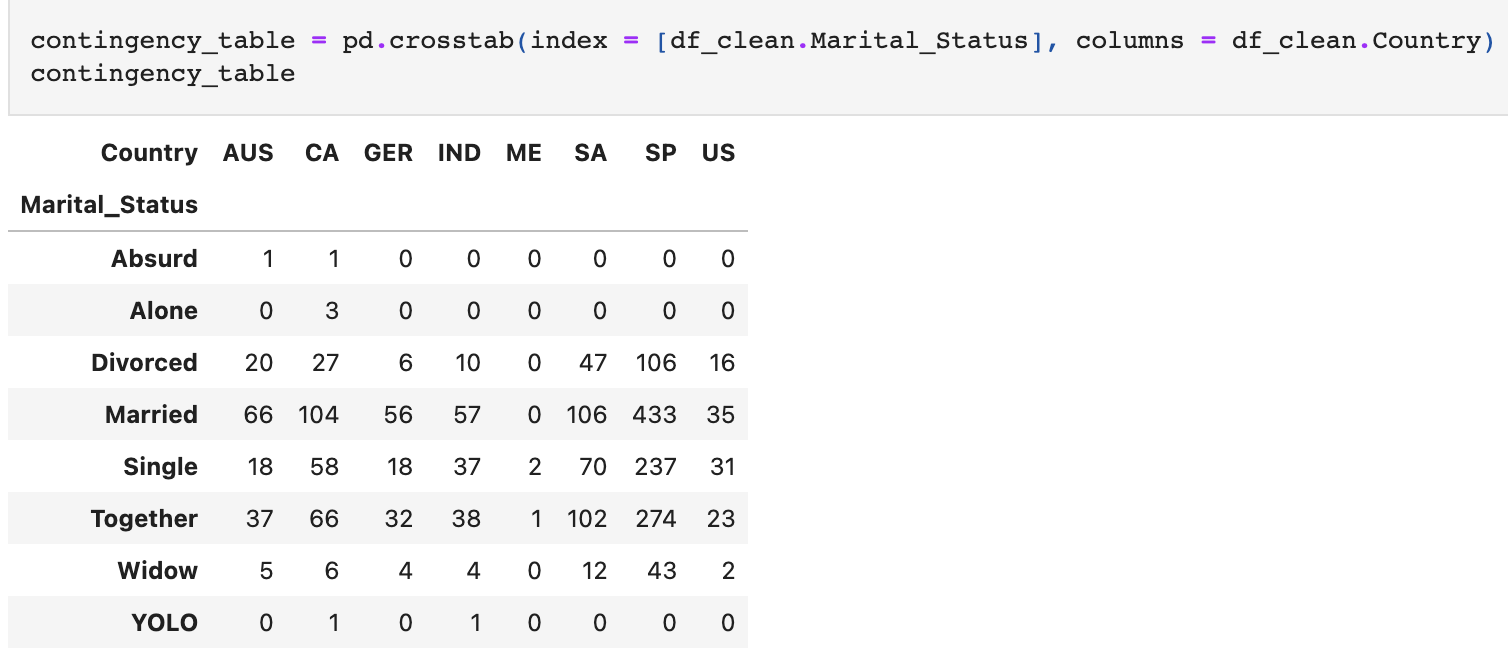
크로스 탭을 활용하여 테이블 다시 만들기
pd.crosstab(index = [df.Marital_Status], columns = df.Country)
참조: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.crosstab.html
chisquare(f_obs = array_obs, f_exp = array_exp, axis=None)
참조: https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.chisquare.html

4. P-value 해석
p-value가 3.35512*e^(-257)이기 때문에 사실상 0에 가깝다. 즉 유의미 하다고 볼 수 있는 수치 0.05(5%) 보다 작기 때문에 귀무 가설이 기각되고 대립가설이 성립된다.
만약 0.05 보다 높은 수치가 나온다면 대립가설이 기각되고 귀무가설이 채택된다.
