스파크 설치
환경 구성
1. jdk 8버전 이상 (1.8 , 11버전 다 지원한다.)
2. spark 설치
3. winutils.exe
4. 환경변수 설정
5. python or anaconda 설치
6. findspark 패키지 설치
1. jdk 8버전 이상 설치
개인적으로는 1.8버전을 추천 최초에 11버전으로 스파크 설치를 진행했는데 계속해서 경고문이 나타남, Stack Over Flow 에 검색해보니 1.8버전 or 자바 8버전으로 설치하면 경고문이 안나온다고해서 다운그레이드 하니 오류가 안나왓습니다.
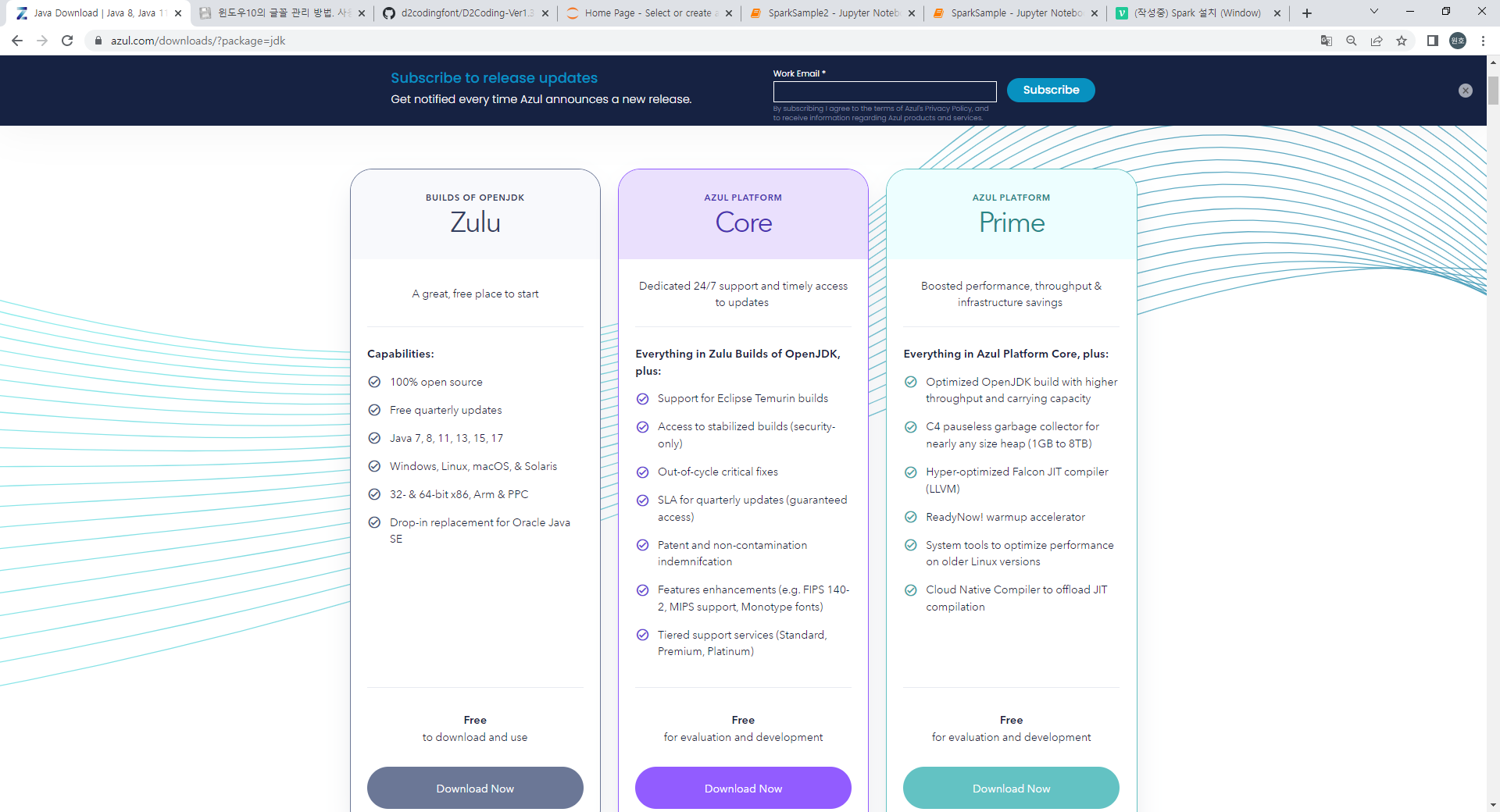
jdk는 zulu jdk 설치 하였습니다.
JDK는 ORACLE사에 넘어간후 유료로 변경되었습니다. 물론 ORACLE사에서도 OPENJDK를 다운받을 수 있고 사용할 수 있습니다. 하지만 zulu는 운영환경과 개발환경을 통일시킬 수 있다는 장점이 있다고 해서 컴퓨터 포맷한김에 zulu 자바로 설치 했습니다.
[줄루 다운로드 경로] https://www.azul.com/downloads/?package=jdk
환경변수 설정
시스템 설정 -> 고급 시스템 설정 -> 환경 변수 -> 시스템 변수 (새로만들기)
이름 : %JAVA_HOME%
경로 : {자바가 설치된 경로}
경로가 굉장히 중요하다. 스파크는 띄어쓰기를 구분못하는 바보기때문!
저는 Program Files에 JAVA가 설치 되어있었기 때문에 C:\Progra~1\ {자바경로} 이렇게 설정했습니다. 안해놓으면,, 자바를 스파크가 못찾습니다... 삽질 오졌다.
시스템 설정에 path를 클릭하면 경로를 설정할 수 있는데, 경로에 %JAVA_HOME%\bin을 입력해주세요! 그리고 cmd창에서 javac -version 을 입력해서 설치 확인
2. Spark 설치!
[스파크 설치 경로] https://spark.apache.org/downloads.html
위에 스파크 설치 경로 클릭하셔서 사이트에 들어가면
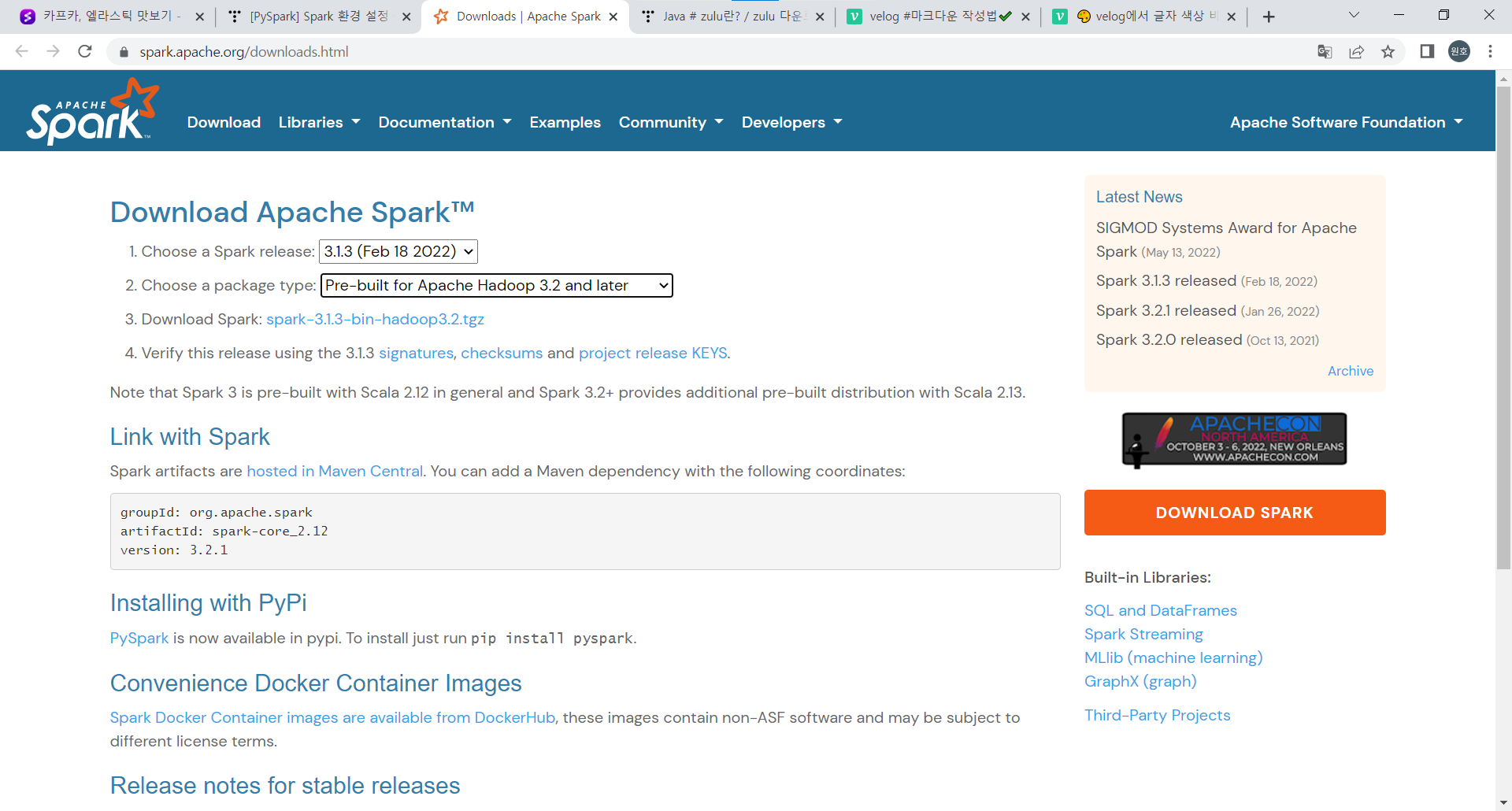
버전: 3.1.3 , 패키지타입: Pre-build for Apache Hadoop 3.2 and later 버전! 하고 3번의 Download Spark 경로로 들어가면 다운 받을 수 있습니다.
최신 버전을 다운 받지 않는 이유는 최신 버전에 오류가 있어서 경고문이나 오류가 뜨기 때문에 한단계 다운그레이드 해서 다운받았습니다.
알집 파일을 다운 받으신 후에 반디집으로 원하는 경로에 압축을 풀어주시면 됩니다.!
저는 C:\Spark 경로에 풀어줬습니다.
3. winutils.exe 설치
스파크는 원래 하둡위에서 돌아가는거라 하둡을 설치해줘야한다고 알고 있었는데, 이번에 진행할때는 하둡을 따로 설치하지 않고 하둡버전에 맞는 winuitls.exe를 추가해서 진행했다.
[winutils.exe]https://github.com/cdarlint/winutils
↑위에 경로로 다운로드 버전으로 다운 하시면 됩니다.
winutils.exe파일은 Hadoop 폴더 만들고 그 안에 bin 폴더 만든후에 놓으면 된다.
내 경로는 C:/Hadoop/bin/winutils.exe로 되어 있다.
4. 환경 변수 설정
환경변수 설정 제일 귀찮다. 자바 환경 변수 설정과 동일하다. HADOOP_HOME , SPARK_HOME에 path 에서 %HADOOP_HOME%\bin, %SPARK_HOME%\bin 으로 path 경로를 잡아주자!
5. python이나 anaconda 설치
나는 Anaconda를 설치 했다. conda는 더럽게 무겁다. 하지만 편하다. 무거운거 싫으신 분은 python으로 설치 후 jupyter notebook을 따로 설치해서 사용하면 되고 편한게 좋은 나는 그냥 anaconda로 ㄱㄱ..
[스파크 다운로드 경로]https://www.anaconda.com/products/distribution
↑위에 경로로 다운로드 버전으로 다운 하시면 됩니다.
아나콘다 설치 후 anaconda3 도 기본 path경로로 설정해주자!
6. Spark 설치 확인
- 재부팅하여 환경 변수 적용
- cmd 창에서 spark-shell 확인
C:\Spark로 이동한 후 실행 - cmd 창에서 pyspark를 쳐서 pyspark 설치 확인
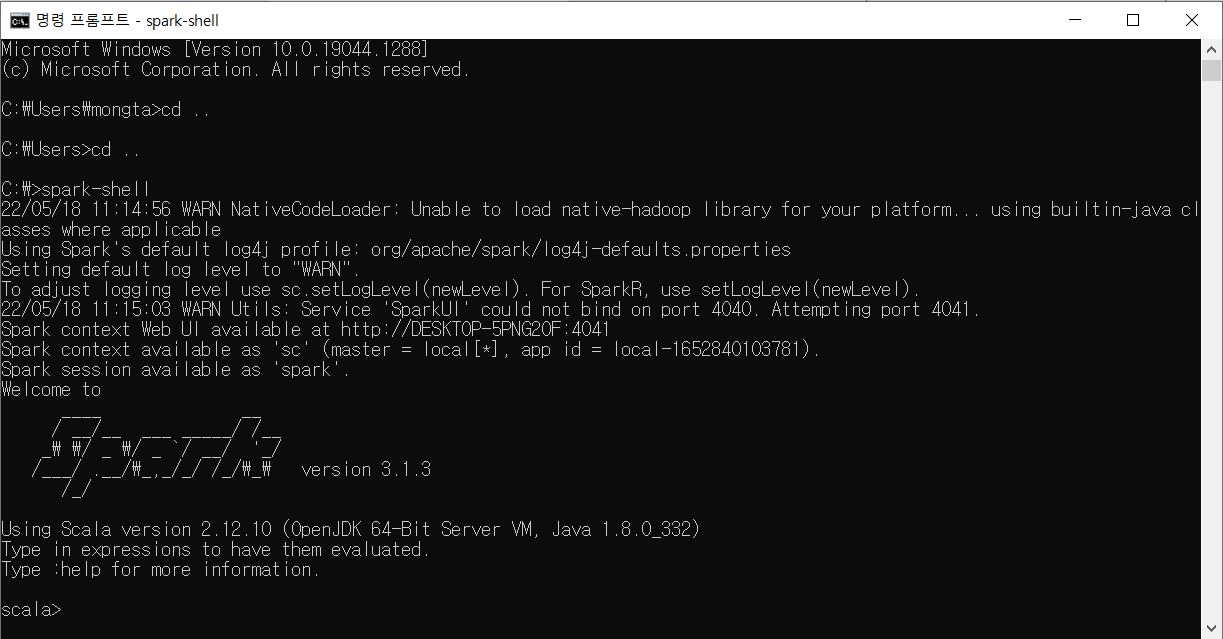
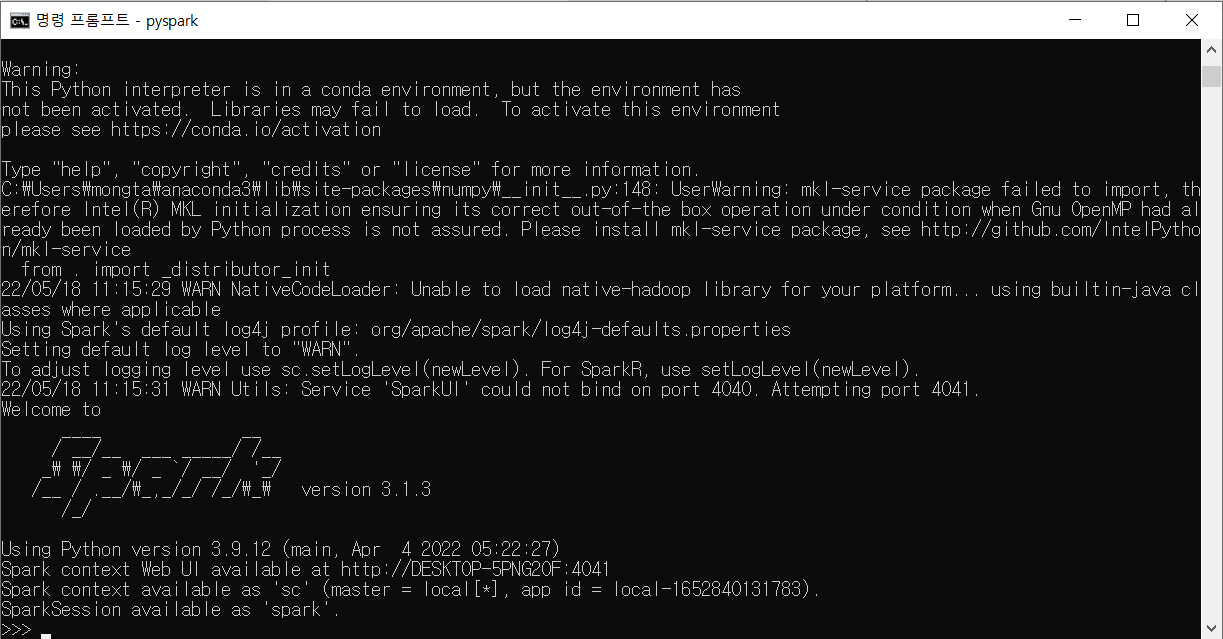
자 적용이 됫다 나오는 방법은 spark-shell은ctrl+cpysparkexit()라고 입력해주면 종료된다.
7. findspark 설치
pip install findspark 입력해서 findspark 를 설치해주세요! 아마 pip은 경로가 아닙니다 라고 뜨면 jupyter lab으로 들어가서 터미널 열고 pip install findspark라고 입력 후 import findspark라고 입력시 오류 안뜨면 설치 된거다!
jupyter lab들어가기!
jupyter notebook켜준 후 url 에 트리 삭제 후 lab을 적어주면 된다.
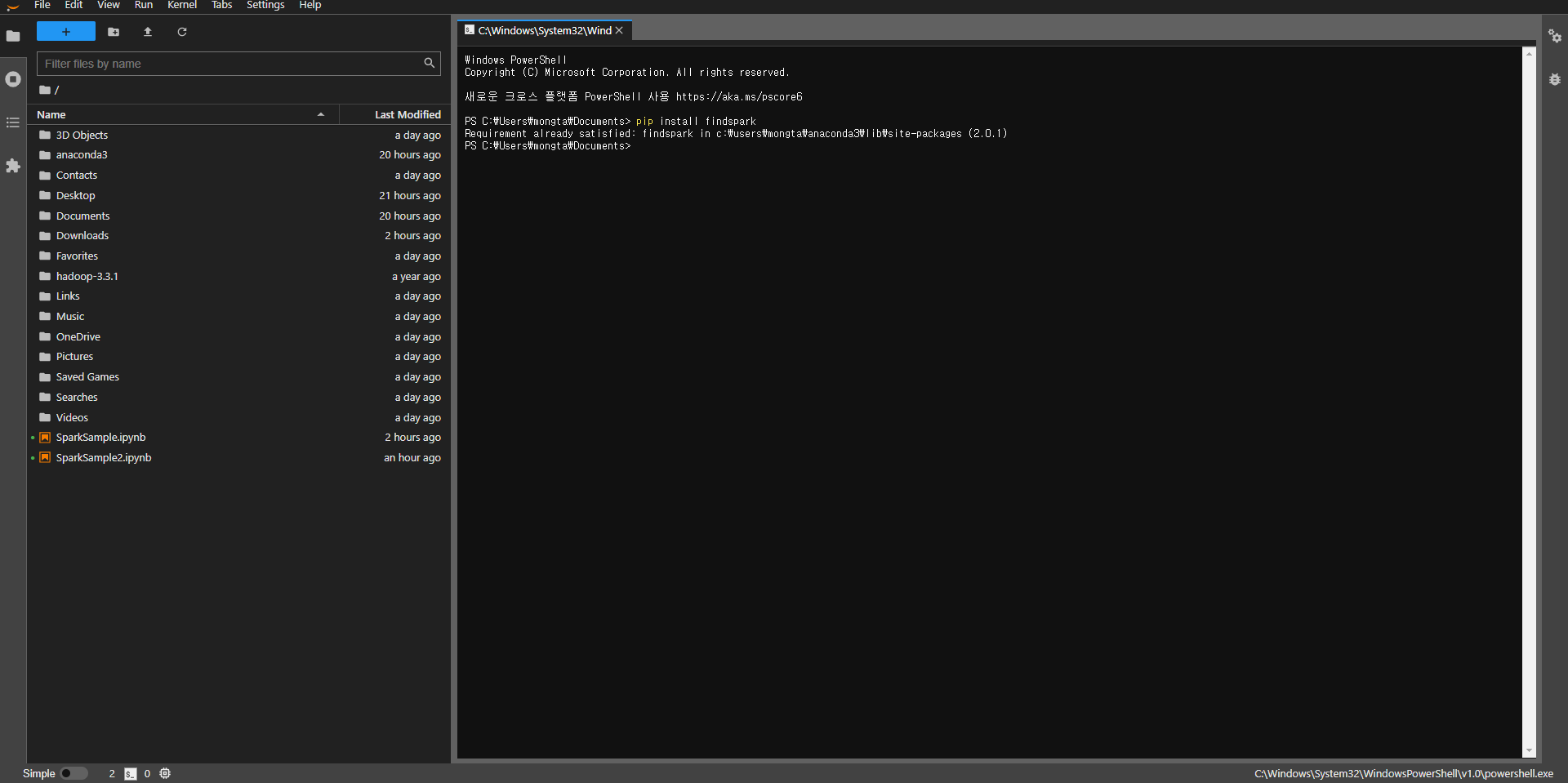
난 이미 설치가 되어있어 저렇게 나온다.
findspark 설치 이유
sys.path에 pyspark를 등록하는 작업을 하지 않았기 때문에, findspark를 통해서 jupyter에서 개발 하도록 하겠다.
8. 최후의 테스트
- spark 서버 work 확인
localhost:8080 - spark jobs 확인
localhost:4040
스파크 마스터 노드와 워크노드를 켜줄거다.
cmd 창을 관리자 모드로 두개를 켜주자!
스파크 bin가 있는 곳 까지 이동하자 내 경로는 C:\Spark\spark-3.1.3-bin-hadoop3.2\bin 이다.
spark-class org.apache.spark.deploy.master.Master를 입력해주면
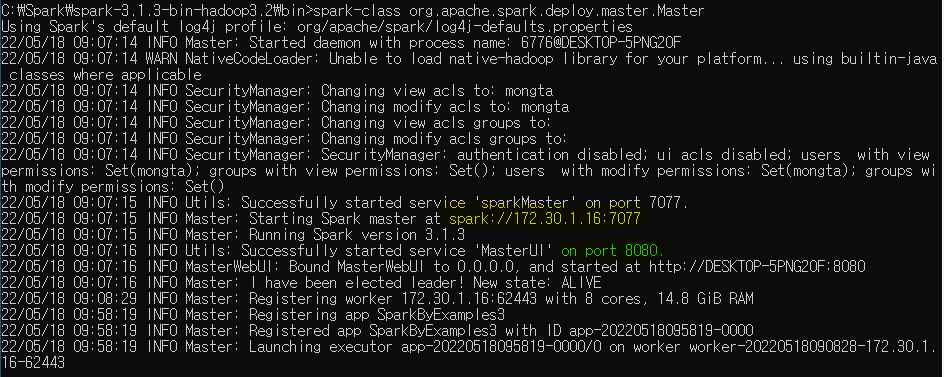
보면 노란색 url이 worknode를 부를때 사용할 url
초록색 port 8080은 worknode를 관리하는 ui page가 뜬다.

중요! master 가 cmd에 켜져있는 상태여야함
spark-class org.apache.spark.deploy.worker.Worker spark://172.30.1.16:7077 을 입력하면
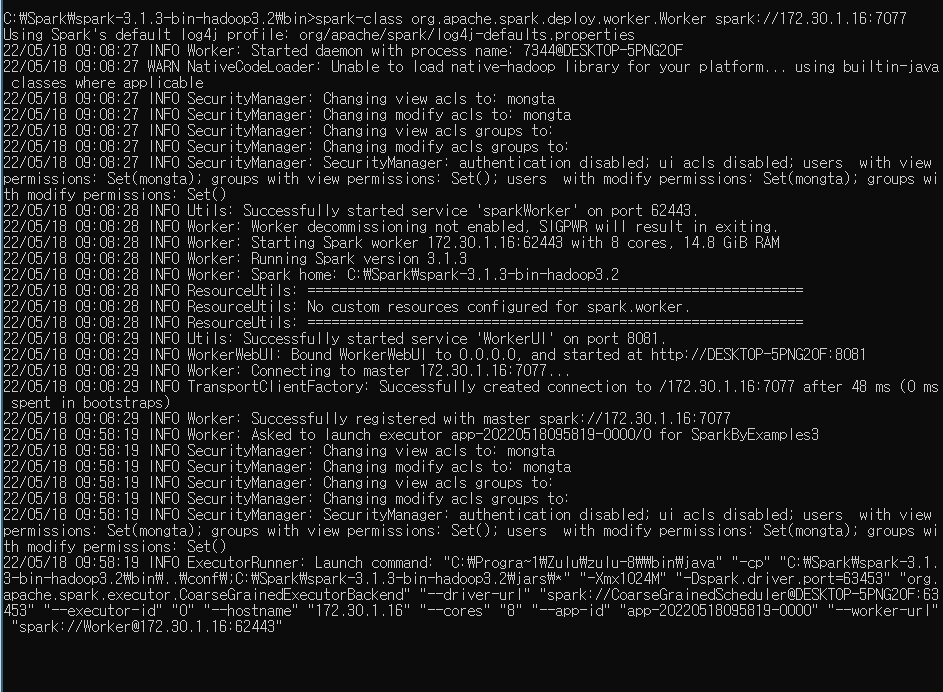
jupyter note book에서 확인
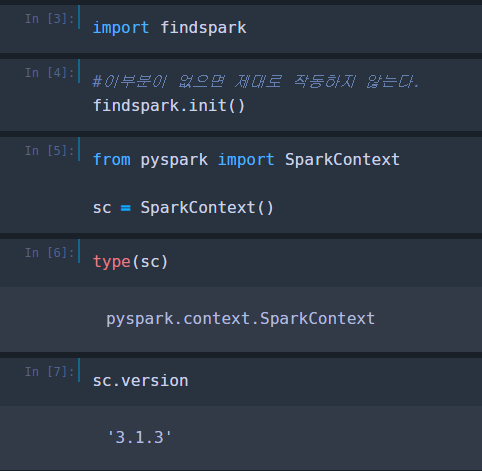
스파크 컨텍스트로 sparkContext가 잘들어오는지 확인한다. sc.version으로 sc버전도 확인한다.
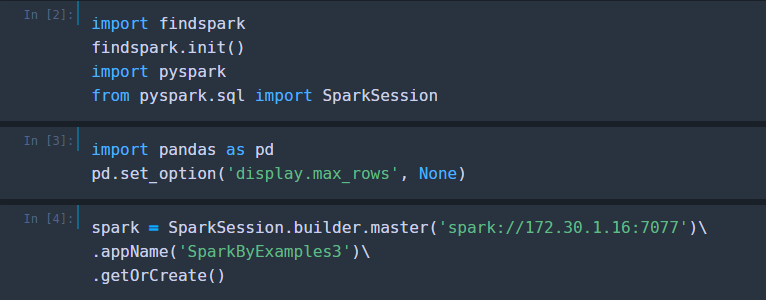
삭제 해둔 부분에는 , 위에 노란색 url을 적어주면 된다.
session 확인
session이 잘 만들어지면 localhost:8080
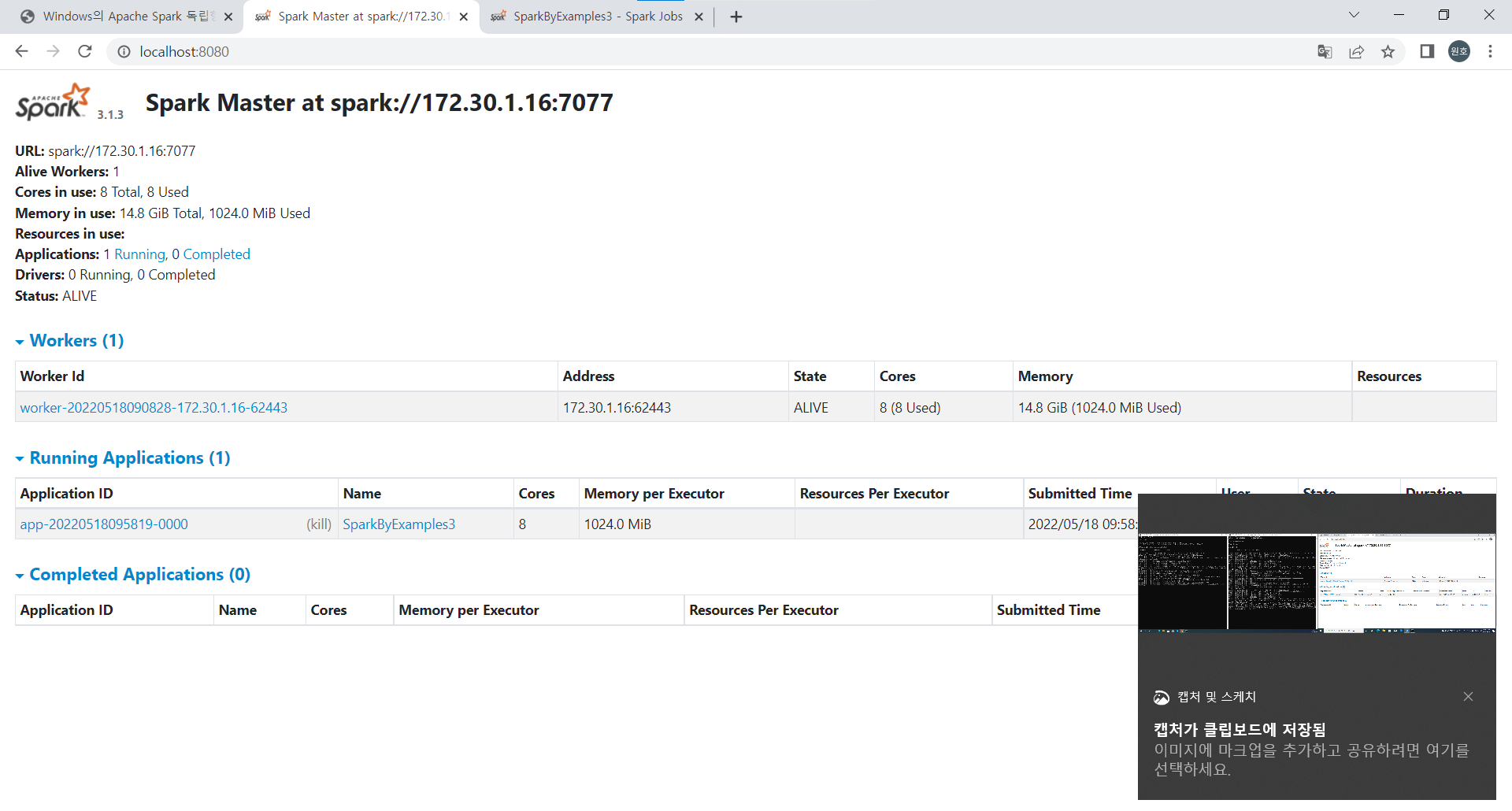
workers와 running application에 작업 현황이 올라온다.
오라클db사용자는 포트 충돌이 날수 있으니 알아서 해결!
이것으로 로컬에서 스파크 설치 및 실행 방법에 대해서 알아 보았다. 오류가 엄청 나서 개인적으로 어려웠다. 버전을 잘 체크하고 path경로를 정확하게 입력하면 쉽게 설치 되는거 같다
