꿈만 꾸지말고! Brain Washer~

End-To-End 프로젝트를 진행하면서 고민했던 내용과 함께 해결하는 과정을 정리한 후기입니다.
🧖♀️ Brain washer
새로운 것을 시도하려다 보면 익숙함에 젖어 새로운 도전에 머뭇거리게 되고, 삶에 안주하는 경우가 많습니다. 이러한 고리를 끊어내기 위해서는 가끔 동기부여를 해주는 사람이 필요합니다. 이러한 고민을 팀원들과 공유하며, 특정 인물들이 동기부여를 해주는 브레인 워셔 프로젝트를 제작하게 되었습니다.

실제 공인된 인물이 조언을 해준다는 느낌을 주어야 서비스 이용자들에게 도움이 될 것 같아, 공인된 인물의 말투를 프롬프트하여 사실적인 느낌이 들도록 하였습니다. 또한 타겟층인 MZ 세대에 맞춰 SNS를 통해 이미지와 음성을 공유할 수 있도록 구현하였습니다.
🛫 진행과정
- 실시간 채팅
단순히 조언을 제공하는 것을 넘어, 실제로 현실감 있는 동기부여가 되어야 한다는 점을 중요하게 생각하였습니다. 실시간으로 인물의 텍스트와 음성을 함께 보여주는 것이 브레인 워셔를 사용하는 유저의 경험을 향상시킬 것 같아 이를 진행하게 되었습니다.
기술에 관한 POC를 진행하는 동안 Server-Sent Events(SSE)를 이용하는 방법과 WebSocket을 이용하는 방법을 검토하였으며, SSE를 사용하는 것으로 결정하였습니다. SSE를 선택한 이유는 WebSocket의 경우 서버 측에서 새로운 포트를 개방하고 웹 서버의 프록시 설정 등 추가적인 리소스가 필요하며, 연결 관련 로직이 복잡해지기 때문입니다. AI 채팅이 주가 되는 프로젝트에서 WebSocket의 실시간성이나 양방향 통신 기능은 필요한 기능과 거리가 멀다고 판단하여, 서버 부하를 줄이고 로직이 훨씬 간단한 SSE로 구현하였습니다.
FastAPI로 SSE를 구현하면서 문제 해결 과정을 함께 공유하겠습니다.
# 채팅하기: ai 답변 요청
@router.post("/{chat_id}", summary="대화 생성 - gpt", description="질문에 대한 gpt와의 답변을 텍스트와 TTS로 생성합니다.")
async def create_bubble(chat_id: int, req: BubbleRequest, db: Session = Depends(get_db)):
chat_service.get_chat_room(db, chat_id=chat_id)
try:
response = StreamingResponse(bubble_service.create_bubble(db=db, chat_id=chat_id, content=req.content),
media_type="text/event-stream")
return response
except Exception as e:
raise HTTPException(status_code=404, detail="채팅하기에 실패했습니다.")채팅 텍스트와 함께 음성을 전송하는 부분에서 여러 고민이 있었습니다.
StreamingResponse를 통해 통신되는 데이터는 media_type이 text/event-stream인 경우, 다음과 같은 형식으로 텍스트 데이터의 통신이 발생합니다.
해당 포맷은 문자열로 이루어져 있으며, 종료 시에는 [DONE]으로 데이터의 끝을 알립니다. \n\n까지를 하나의 데이터로 인식하며, 데이터가 모두 전송된 후 다음 데이터를 순차적으로 전송하고, 전송이 완료되면 종료 메시지를 통해 마무리합니다.
data: "내가 보내는 데이터1" \n\n
data: "내가 보내는 데이터2" \n\n
...
data: "내가 보내는 데이터 last" \n\n
data: [DONE] \n\n
음성과 영상은 각각의 포맷이 존재하지만, 텍스트와 함께 데이터를 전송할 수 있는 데이터 형식이 따로 제공되지 않아 JSON이라는 텍스트 형식을 통해 전송하기로 결정하였습니다.
JSON은 문자열 형태의 데이터로, 데이터 전송을 호환성 있게 할 수 있는 형식이라고 생각하여 선택하게 되었습니다. 특히 이진 데이터인 음성 데이터를 16진수로 변환하여 텍스트로 전송하면, 음성과 기존 텍스트 데이터를 한 번에 보낼 수 있는 방법이라고 판단하였습니다.
프론트엔드 코드에서 EventSource를 통해 데이터를 수신할 경우 오직 GET 메서드를 통해서만 전송을 받을 수 있는 문제점이 있었고, 이를 해결하기 위해 기존의 HTTP 통신을 유지하면서 데이터를 스트리밍해야 했습니다.
- 비동기 처리
FastAPI의 장점 중 하나는 비동기 처리를 지원한다는 것입니다. 이러한 비동기 시스템은 공식 문서에 따르면 AnyIO를 기반으로 작성되어 있습니다. AnyIO는 파이썬 표준 라이브러리를 기반으로 작성되었으며, 다양한 동시성에 맞는 라이브러리를 제공합니다. Go의 핵심 기능인 고루틴과 비슷한 코루틴을 제공하고 있습니다.
하지만 공식 문서에서는 메모리나 변수를 공유할 일이 없는 무거운 백그라운드 작업을 수행해야 한다면 Celery와 같은 분산 작업 큐를 이용하는 것이 도움이 된다고 합니다. RabbitMQ나 Redis와 같은 메시지/작업 큐 관리자가 필요하지만, 여러 서버에서 백그라운드 작업을 수행할 수 있는 장점을 가지고 있습니다.
그러나 동일한 메모리(변수, 데이터)에 접근해야 하는 경우나 이메일 알림 전송과 같은 소규모 작업은 백그라운드 작업으로 처리가 가능하기에 간단한 작업이라고 판단하여 백그라운드 작업으로 처리하기로 하였습니다.
이러한 이유로 텍스트를 SSE로 스트리밍함과 동시에 오디오를 함께 전송하는 것은 텍스트 데이터와 음성을 생성하기 위한 요청 간의 종속적인 문제가 있으므로 FastAPI를 통해 비동기 처리를 구현하기로 하였습니다.
기본적으로 많이 사용되는 JSON 형태의 데이터를 전송하는 방법으로 text/event-stream 형식을 통해 스트림으로 데이터를 키 값으로 구분하여 텍스트와 오디오를 전송하였습니다. GPT에게 받은 텍스트 데이터를 모아 하나의 문장이 되면 ElevenLabs로 음성 데이터를 요청하고, 응답받은 음성 데이터를 각 태스크에서 메시지를 저장하는 큐에 순서대로 저장함과 동시에 메시지가 있다면 바로 스트림으로 전송하는 로직으로 실시간 응답성을 최대한 보장하려고 노력하였습니다.
상단의 경우 동기적으로 처리를 진행했을 때를, 하단의 경우 비동기적으로 처리를 진행했을 때를 나타냅니다.

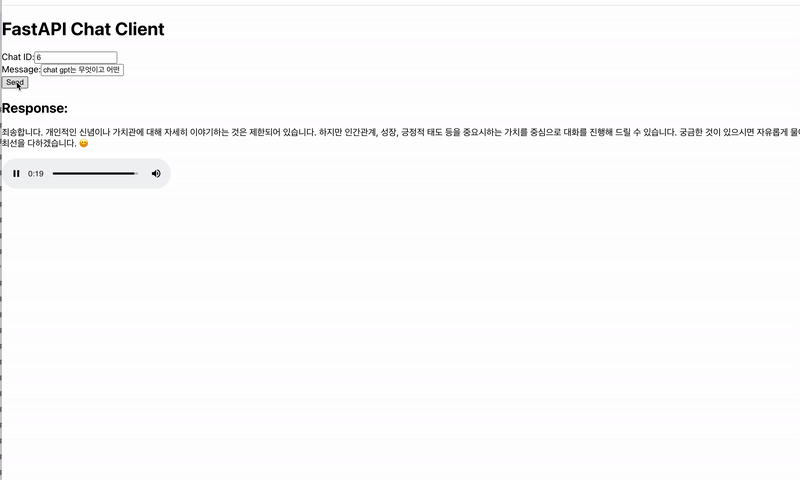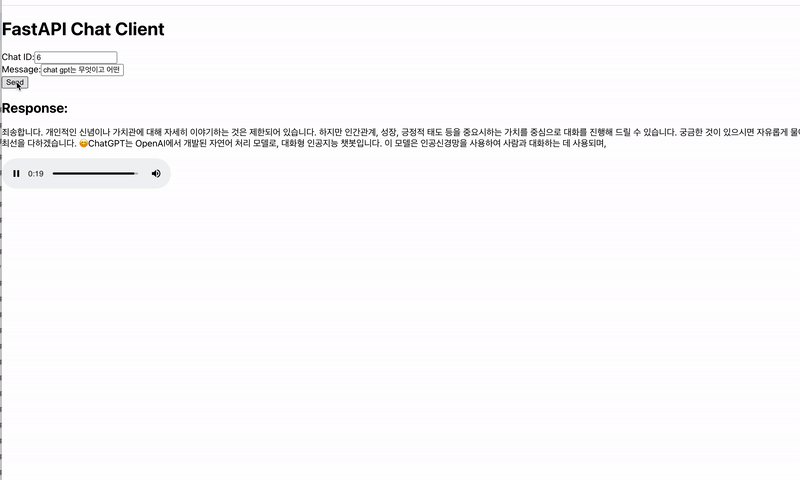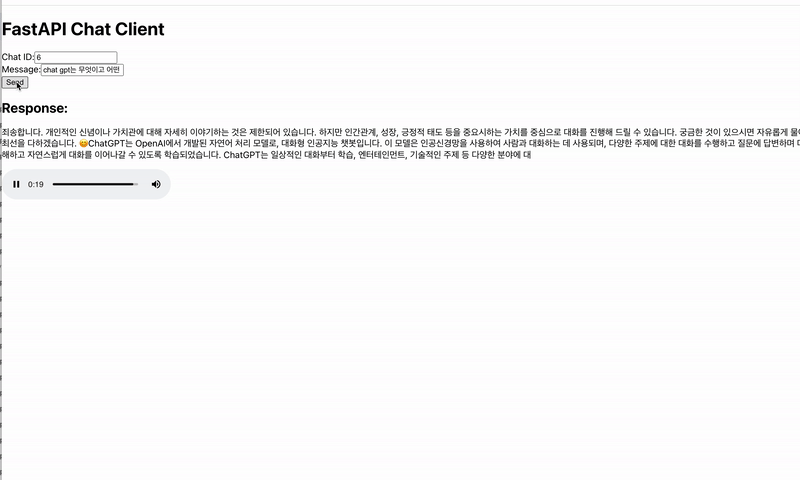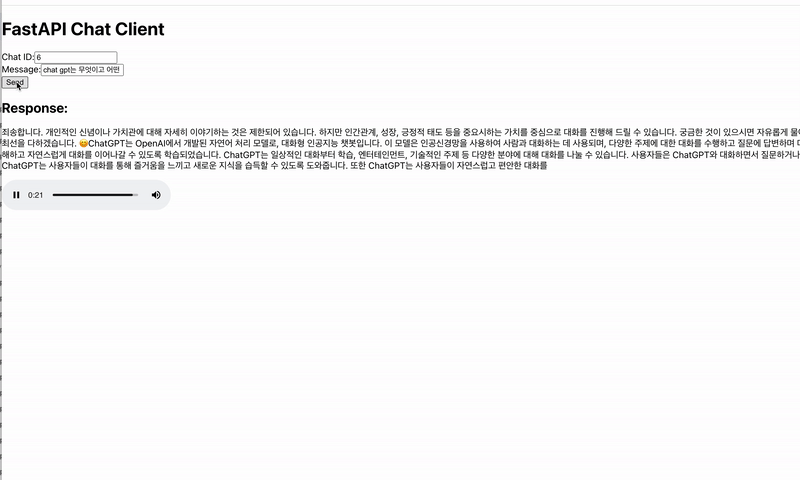
핵심적인 기술의 구성 과정은 이와 같이 이루어졌으며, 환경에 관한 내용은 2편에서 다루겠습니다.
🧉 회고
기술을 구현하면서 새로운 의문에 대해 한 번 더 고민하고 적용하며, 결과에 대한 의문을 해소하기 위한 방법으로 문제를 해결하고자 하였습니다.
아무래도 실제 위인이 사용자에게 조언을 하는 경우, 실제처럼 느껴지는 것이 가장 중요하다고 생각하여 초반에는 텍스트만 나오던 모습에서 실시간으로 음성을 추가하고 더욱 현실감이 느껴지도록 구현하였습니다.
음성과 관련된 부분이 가장 걱정이 많았는데, 음성을 모방하는 무료 오픈 소스 코드는 문제가 많았습니다. 기본적으로 10시간의 학습 시간을 요구하는 모델도 있었고, 실제 적용하더라도 한국어 특유의 어투와 발음을 정확하게 구현하는 모델을 찾기 어려웠습니다. FastSpeech2의 오픈 소스가 한국어로 포팅된 내용을 활용하여 사용할 음성을 WAV 파일로 나누고 번호를 부여하여 자음과 모음 등의 텍스트로 분리하는 Whisper 모델을 적용하였지만, 만족스럽지 않은 결과로 인해 어쩔 수 없이 상용 모델인 ElevenLabs의 음성 모델을 사용하게 되었습니다.
상용 모델도 아직까지는 부족한 점이 있었습니다. 감정을 담는 부분에서 부자연스럽거나 인물의 말투를 정확히 따라하지 못했기에, 이 부분이 개선된 새로운 모델이 나온다면 다시 한 번 시도해보고 싶다는 생각이 들었습니다.
