extend context length
Focused Transformer: Contrastive Training for Context Scaling
https://github.com/CStanKonrad/long_llama
- attention layer에 외부 메모리에 접근할 수 있도록 하여 (키, 값) 쌍 구성
- 문서 수가 증가함에 따라 관련된 key와 관련이 없는 key의 비율이 감소하면서, 모델이 관련이 없는 키에 더 집중하게 되는 문제점을 가지고 있습니다.
- 저자는 의미적으로 다른 value에 연결된 key가 overlap되어 구별하기 어려운 현상을 distraction issue로 정의하며 이러한 문제를 해결하기 위해 FOT(Focused Transformer)를 제안합니다.
- FOT(Focused Transformer)는 contrastive learning에서 영감을 얻은 training process로 (key,value) space의 구조를 늘려 광범위한 외부 메모리와 k-nearest neighbors lookup을 사용하여 context length의 확장을 가능하게 한다.
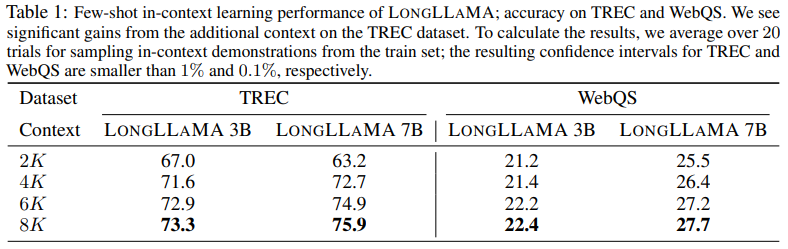
- 구현이 간단하고 비용 효율적인 미세 조정을 통해 아키텍처를 수정하지 않고 메모리로 기존 모델을 보강하는 이점을 제공합니다. 3B 및 7B OpenLLaMA 체크포인트에서 이를 시연합니다. 또한 암호 키 검색 Mohtashami 및 Jaggi에서 LONGLLAMA 모델이 256k 컨텍스트 길이를 성공적으로 처리함을 증명합니다.
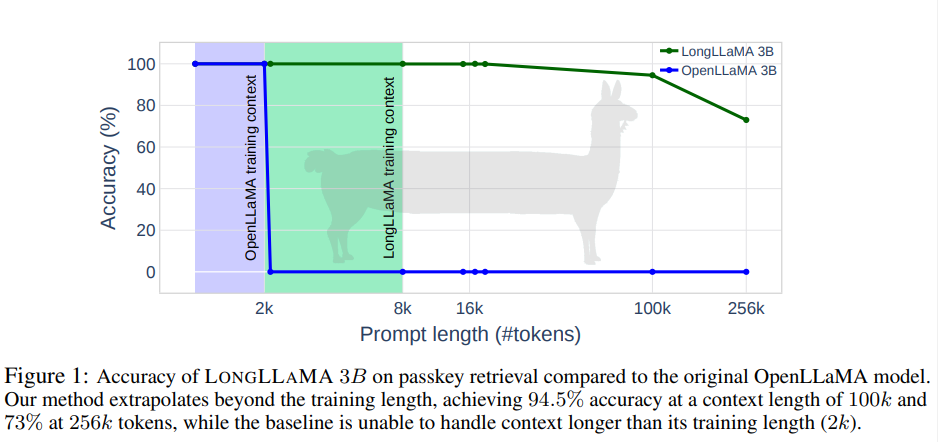
일부 attention layer가 k-nearest neighbors (kNN) algorithm을 통해 (key, value) pairs의 외부 메모리에 접근할 수 있도록 하여 효과적으로 컨텍스트를 연장할 수 있습니다. distraction issue를 다루고 더 큰 메모리를 사용할 수 있도록 해준다. 특히, 훈련 단계에서 우리는 의도적으로 메모리 어텐션 레이어를 관련된 키와 관련 없는 키 모두에 노출시킵니다. (예: 관련 없는 문서의 네거티브 샘플). 이 전략은 모델이 의미적으로 다양한 값과 연결된 키를 구별하여 구조를 향상시키도록 유도합니다.
이는 3B 및 7B OpenLLaMA 체크포인트의 미세 조정으로 입증됩니다. LONGLLAMA2 라는 결과 모델은 긴 컨텍스트가 필요한 작업의 발전을 보여줍니다. 우리는 LONGLLAMA 모델이 패스키 검색을 위해 256k 컨텍스트 길이를 적절하게 관리한다는 것을 추가로 설명합니다.
- OpenLLaMA models with FOT로 파인튜닝 한것
- 이전에 rotary positional encoding 수정으로 접근 한 방법과 달리 저자는 메모리에서 rotary positional encoding를 제거해서 256K token까지 extrapolate 했다. (8K까지만 train했지만 이론적으로 unbounded context length 산출)
2.Related Work
2.1.Long-context transformer architectures
2.2.Fine-tuning LLMs for longer context
2.3.Contrastive learning
Contrastive learning은 긍정적인 예와 부정적인 예를 비교하여 좋은 표현을 배우는 것을 목표로 합니다. CLIP [Radford et al., 2021] 및 SimCLR [Chen et al., 2020]은 이미지 도메인에서 최첨단 성능을 달성한 두 가지 인기 있는 대조 학습 방법입니다. Contrastive pre-training 동안 부정적인 예는 긍정적인 예와 구별하는 방법을 배우기 위해 동일한 배치에 보관됩니다. [Gao et al., 2021b]에 표시된 것처럼 대조 학습에서 배치 크기를 조정하면 표현의 품질이 향상되는 것으로 입증되었습니다. [Gao et al., 2019] 언어 모델링의 임베딩 공간은 임베딩이 좁은 원뿔에 빽빽하게 채워져 있어 이들을 구별하기 어렵게 만드는 퇴행성을 겪고 있다고 제안되었습니다. TRIME [Zhong et al., 2022]는 표현의 품질을 향상시키기 위해 배치 내 네거티브를 사용하는 메모리 증강으로 LM을 교육하도록 설계된 교육 접근 방식을 제안합니다. 이것과 우리 접근 방식의 주요 차이점은 출력 레이어에서 보간하는 대신 메모리 어텐션 레이어에 네거티브를 통합한다는 것입니다.
3.Method
- plug-and-play extension of transformer
models - 모델이 추론 시 외부 메모리에서 정보를 검색할 수 있도록 하여 컨텍스트를 효과적으로 확장하는 memory attention layers과 메모리 어텐션 레이어에서 사용하기 쉬운 (키, 값) 표현을 학습하도록 모델을 bias하는 crossbatch training procedure 사용
3.1 Memory attention layers
메모리 어텐션 레이어 L은 추론시 외부 메모리 데이터베이스에 대한 액세스 권한이 부여됩니다. 즉, ℓ ∈ L의 각 쿼리는 local context의 선행 키와 메모리와 가장 일치하는 상위 k개의 키에 주의를 기울입니다.
메모리 키는 쿼리와 내적하여 순위가 매겨지고 FAISS [Johnson et al., 2017]에서 실행하는 kNN 검색 알고리즘으로 검색됩니다.
메모리는 미리 ℓ에 의해 처리된 (키, 값) 쌍으로 점진적으로 채워집니다. 메모리 어텐션 레이어 디자인은 전반적으로 Memorizing Transformer[Wu et al., 2022]를 따르지만, gating을 제외하였다.
두 가지 주요 차이점은 1) 훈련 프로토콜 2) 메모리가 모델에 통합되는 방식입니다. 이 섹션에서는 이러한 차이점에 대한 추가 통찰력을 제공합니다.
1) Training protocol
2) Memory integration: MT는 gating 메커니즘, 메모리의 weighted average, local value를 사용하는 반면, FoT는 kNN lookup으로 검색된 (key, value) pairs를 local context로 여긴다. 둘다 성능에는 차이가 없지만 후자가 아키텍처 변화를 요구하지 않기 때문에 파인튜닝하기 쉬어 사용한다. 그리고 FoT에서 게이팅이 필요하지 않은 이유는 역전파할 수 없고 키와 값에 대한 기울기 계산할 때, 로컬 컨텍스트에 의존해야 하는 MT와 달리 이전 컨텍스트 Cprev의 (키, 값) 쌍을 통해 크로스배치 훈련이 역전파된다는 사실의 또 다른 이점입니다. 또 다른 이유는 Cprev가 각 배치에 내장되어 있어 부실함([Wu et al., 2022, 섹션 3.2] 참조)을 피할 수 있다는 사실일 수 있습니다.
3.2 Crossbatch training procedure
-
contrastive-inspired objective을 사용해서 이전 context를 통해 backpropagating
-
training 방식으로 (키, 값) 공간의 구조를 개선
-
메모리 attention 계층 ℓ ∈ L이 관련 정보에 쉽게 집중할 수 있도록 공간을 형성하는 것입니다.
-
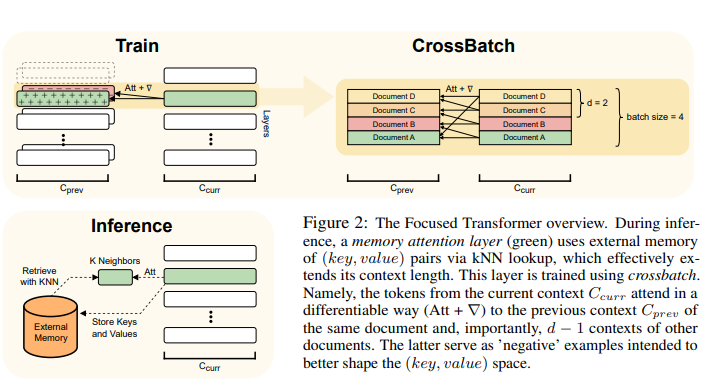
대조 학습에서 영감을 얻은 핵심 아이디어는 주어진 문서(양수)의 현재 및 이전 로컬 컨텍스트의 (키, 값) 쌍과 관련 없는 문서(음수)의 d-1 컨텍스트에 ℓ을 노출하는 것입니다. 중요한 것은 이것이 미분 가능한 방식으로 수행된다는 것입니다.
-
이를 위해 배치의 각 요소가 다른 문서에 상응하는 데이터 파이프라인을 사용합니다. 처리된 각 문서에 대해 이전(Cprev) 및 현재(Ccurr) 로컬 컨텍스트를 임베딩한다.
-
Ccurr의 각 문서 δ에 대해 Cprev(음수)에서 오는 d − 1개의 다른 컨텍스트의 쌍과 함께 δ의 이전 로컬 컨텍스트(양수)에서 (키, 값) 쌍으로 구성된 집합 P를 만듭니다.
트레이닝 중에는 외부 메모리를 사용하지 않습니다. 여기에는 두 가지 중요한 결과가 있습니다. 첫째, 작업은 완전히 미분 가능하므로 p^δ의 모든 (키, 값) 쌍을 개선합니다. 둘째, 절차를 구현하기 쉽습니다.
추가적인 loss이 필요하지 않으며(즉, standard
transformer training objective 사용) 데이터 로드 파이프라인 수준과 약간의 self-attention 변화 정도로 학습이 가능합니다.
새로운 하이퍼파라미터는 d뿐이며 양성 샘플과 음성 샘플의 비율을 규정합니다. 일반적으로 작은 d ≤ 8에서 시작하고(그렇지 않으면 모델이 이전 로컬 컨텍스트를 무시하는 경향이 있음) 나중에 더 큰 값(예: d ≥ 64)으로 전환하는 것이 좋습니다.
- 후에 (key, value) pairs의 메모리로 증강하기 위해 attention layer의 부분집합인 L을 선택한다.
- training동안, 이 layer l을 현재 local context인 Ccurr와 이전 local context와 다른 문서에서의 d-1 context인 Cprev의 (key, value) pairs에 노출시킨다.
- input pipeline을 수정해서 각각의 batch index를 다른 문서에 일치시킨다.
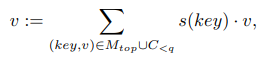
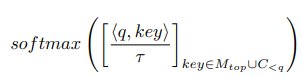
3.3 The distraction issue
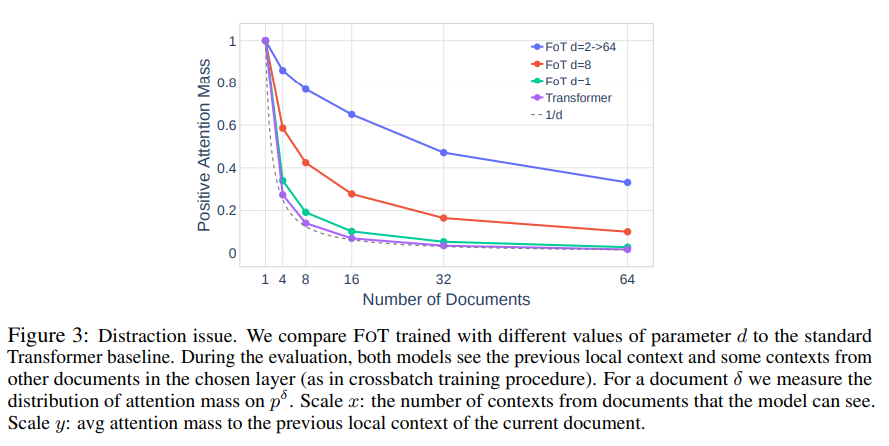
이 섹션에서는 주의 산만 문제라고 부르는 것을 개념화하고 대용량 메모리 데이터베이스를 사용할 때 주요 문제 중 하나라고 가정합니다. 즉, 표준 교육 중에 모델은 다른 문서에서 키를 구별하도록 인센티브를 받지 않습니다. 우리는 관련 문서와 관련되지 않은 문서에 집중된 관심이 고르게 분포되어 있음을 측정합니다. 그림 3을 참조하십시오. 보다 정확하게 문서 δ의 경우 wij를 섹션 3.2에서 설명한 대로 구성한 p δ ij와 관련된 소프트맥스 가중치라고 합니다. 긍정적인 관심 질량을 rd := P j w1j/ Pd i=1 P j wij 로 정의합니다. 우리는 rd ≈ 1/d를 관찰합니다. 이는 양수 키(현재 문서에서 i = 1에서 나옴) 및 음수 키에 의해 주의가 똑같이 산만해진다는 사실로 해석될 수 있습니다. 이는 메모리를 확장할 때 주의가 점점 산만해지기 때문에 바람직하지 않은 속성입니다. 우리는 크로스배치가 산만함 문제를 대부분 완화하여 집중된 관심을 가져온다는 것을 보여줍니다. 자세한 내용은 부록 B.4에서 확인할 수 있습니다. 섹션 5.4에서 산만함 문제가 당혹감과 같은 메트릭에 해로운 영향을 미친다는 것도 보여줍니다.
LongLLaMa
- One of the promises of our work is that FOT can be used to fine-tune already existing
large models to extend their context length. - OpenLLaMA-3B and OpenLLaMA-7B models trained for 1T tokens as starting points and fine-tune them with FOT.