MoE(Mixture of Experts)
Mixture of Experts(MoE)
- Increase model capacity with less computational cost
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini∗, Krzysztof Maziarz, Andy Davis1, Quoc Le, Geoffrey Hinton and Jeff Dean
Google Brain, Jagiellonian University
23 Jan 2017
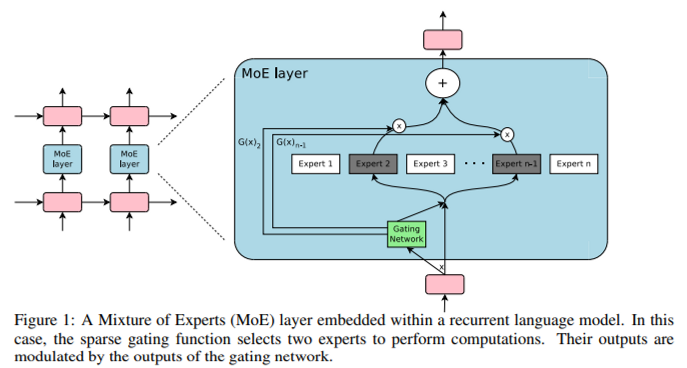
일부 ffn와 lstm을 MoE로 교체하여 언어 모델링과 번역에서 큰 성능향상을 보였습니다. 그런데 Transformer에 MoE를 적용할때에는 다음과 같은 issue가 발생합니다.
- Model complexity
- high communication costs
- training instabilities
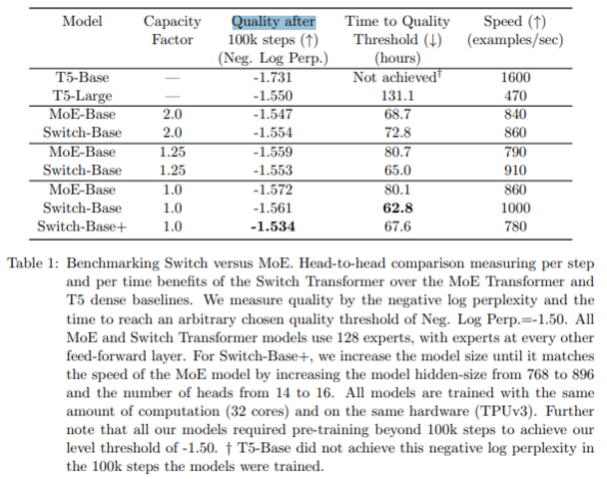
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Google
16 Jun 2022
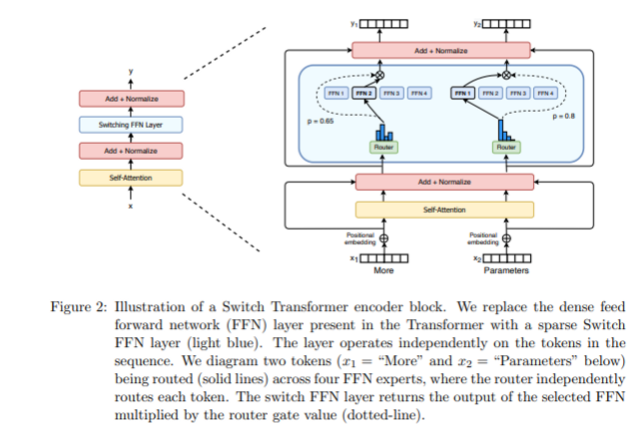
- FFN은 2개 또는 4개마다 1개를 switch layer로 교체한다는 컨셉
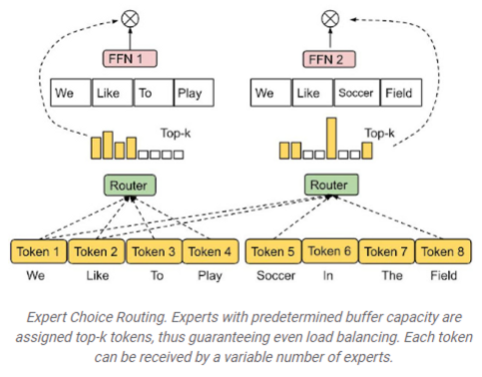
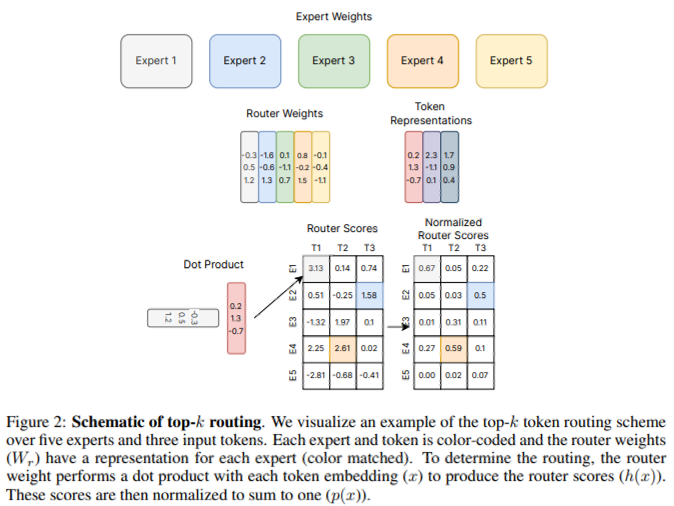
- token과 token parameter를 입력으로 받아 임베딩이 router로 전송됩니다. router는 모든 전문가들에게 배포하고, 위 피규어 2에서는 전문가 4명 중 2번이 전문가일 가능성이 가장 높다는 것을 알 수 있습니다. 그리고 right token는 첫번째 ffn weight에서 가장 높은 확률을 가지기 때문에 첫번째일 확률이 높다. 즉, 확률이 가장 높은 전문가에게 보내는것.
- 여러 전문가들에게 토큰을 보내기 때문에 통신 비용이 증가시킬 수 있다.
Method
1. selective precision

10,000 step 학습 후 손실이 자주 발산한다는 점에서 sparse 모델은 dense 모델보다 훨씬 더 불안정합니다. 따라서 안정적으로 훈련될 수 있도록 float32에서 일부를 casting 해야 합니다. 서로 다른 프로세서에서 텐서를 통신할 때 속도가 너무 느리기 때문에 fp32에서는 권장 하지 않고,
안정적인 학습을 위해서는 낮은 정확도에서 학습을 해야 하기 때문입니다. casting하는 유일한 부분은 router 계산 부분으로, 이 부분에는 통신이 따로 없기 때문에 speed 를 1390에 맞출 수 있었습니다.
2. reduced initialization scale and slower lr warmup
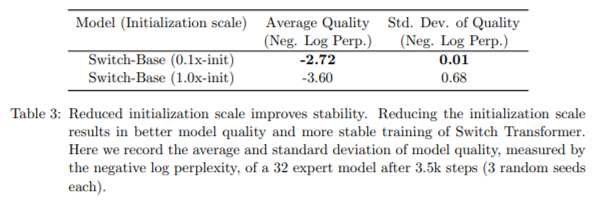
단순히 초기화 규모를 훨씬 작게해서 성능향상 도모
3. higher regularization for experts for finetuning
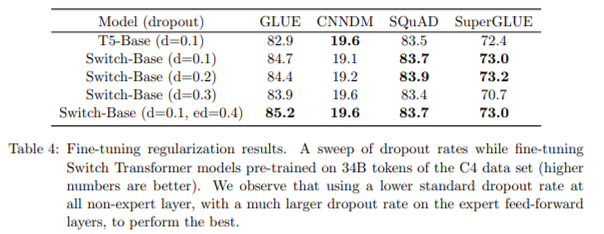
파라미터가 훨씬 많아 오버피팅 가능성이 훨씬 높기 때문에 전문가 레이어에만 훨씬 더 많은 드롭아웃 적용합니다.
4. load balancing : a differentiable auxiliary loss and cross entropy loss to balance the load across experts
각 전문가가 대략 동일한 양의 토큰을 얻을 수 있도록 차별화 하는 로드 밸런싱 기술로 cross entropy loss와 load balancing loss 추가하여 적용합니다.

Modulate expert capacity with capacity factor
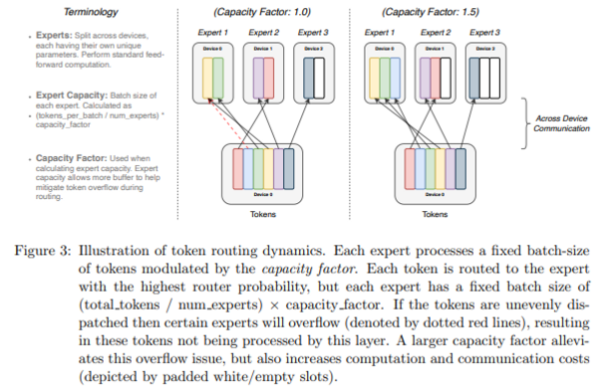
너무 많은 토큰이 하나의 전문가에만 route되면 expert capacity는 고정되어 있기 때문에 일부는 drop됩니다. 저자들은 각 전문가에 대해 고정된 배치 크기를 가져가야 하고, 토큰 drop이 있을 수 있기 때문에, 토큰이 드롭되거나 계산이 적용되지 않은 일부 토큰이 전문가에게 피해를 줄 수 있다고 생각했습니다. 따라서 1. 각 토큰을 확률이 가장 높은 전문가에게 보내는 일반적인 라우팅을 수행하고, 2. 드롭된 토큰은 두번째로 높은 확률 전문가에게 보내는 식으로 반복하여 진행하여 토큰이 드롭되지 않도록 보장합니다. 하지만 이 실험은 성능향상에는 직접적으로 기여를 하지 못했습니다.
또, 로드밸런싱은 모든 전문가가 매우 유사한 가중치를 학습한 다음 무작위로 토큰을 할당하도록 권장로, 사전학습시 약간의 로드발란싱 로스가 발생하여 실제로 토큰의 균형이 잘 잡히는 것을 확인하였습니다. 하지만 미세 조정중에 특정 작업에 대해 미세 조정하고 싶은 것처럼 로드밸런싱 손실이 있는 것이 도움이 되는지 여부에 대해 연구했습니다. 실제로 보조적인 loss를 끄는 것이 성능이 더 좋았고 60-70% 토큰이 삭제되더라도 실제로는 모든 토큰의 균형을 유지하는 것보다 훨씬 더 나은 성능을 발휘합니다.
로드밸런싱 로스를 사용하면 라우팅 매커니즘은 확실히 학습된다. 모델은 영원히 보내고 싶은 전문가를 선택하도록 확실히 권장된다. 로드 밸런싱 로스가 작은 수일 때 라우터가 여전히 의미론적이로 의미 있는 라우팅을 학습한다는 것을 관찰했습니다.
저자는 이 논문으로 각 example마다 다른 매개변수를 갖는 sparsity와 adaptive computation에 관한 연구를 진행하였고, Switch Transformer는 Selective precision(더 낮은 정밀도로 학습), reduced initialization scale and slolwer learning rate warmup, higher expert regularization, model-parallel experts로 각 토큰에 top1 routing인 하나의 expert를 선택하여 일반적인 sparse model을 발전시켰다.
Switch Transformer는 hidden state에 softmax를 사용하여 토큰당 top expert만 선택하여 gating을 단순화하고 더 좋은 scaling을 보여줍니다. 이 논문이 나오기 전까지 명시적으로 균형을 장려하기 위해 보조 손실이 필요했습니다. 이 loss term은 primary loss를 압도하지 않도록 조심스럽게 weight되어야 합니다. 그러나 auxiliary loss는 balancing을 보장하지 않으며 hard capacity factor가 부가되어야 합니다. 결과적으로 많은 토큰이 여전히 MoE layer에서 처리되지 않을 수 있습니다.
Mixture-of-Experts with Expert Choice Routing
Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew Dai, Zhifeng
Chen, Quoc Le, and James Laudon
Google, Mountain View, CA, USA
- Sparsely-activated Mixture-of-experts (MoE) models에 대한 새로운 routing method 제안합니다.
- 이 방법은 기존의 MoE 방법에서 전문가의 load imbalance 및 under-utilization을 해결하고 각 토큰에 대해 다양한 수의 전문가를 선택할 수 있습니다.
- 최신 GShard 및 Switch Transformer 모델과 비교할 때 2배 이상의 training 효율성 향상을 보여주고 GLUE 및 SuperGLUE 벤치마크에서 11개의 데이터를 미세 조정할 때 강력한 이득을 얻습니다.
- expert choice routing 접근 방식은 간단한 알고리즘 혁신으로 heterogeneous MoE를 가능하게 합니다.
NeurIPS 2022에서 발표된 "Mixture-of-Experts with Expert Choice Routing"에서는 EC(Expert Choice)라는 새로운 MoE routing 알고리즘을 소개합니다. 우리는 이 새로운 접근 방식이 MoE 시스템에서 최적의 로드 밸런싱을 달성하는 동시에 token-to-expert 매핑에서 이질성을 허용하는 방법에 대해 논의합니다. 기존 MoE 네트워크의 토큰 기반 라우팅 및 기타 라우팅 방법과 비교할 때 EC는 매우 강력한 training 효율성과 높은 성능을 보여줍니다. Pathways MPMD(multi program, multi data) 지원을 통해 여러 다른 종류들로 이뤄진 mixture-of-experts을 가능하게 하는 Pathways의 비전 중 하나와 공감합니다.
네트워크의 일부가 example별로 활성화되는 조건부 계산 유형인 MoE(Mixture-of-experts)는 계산량의 비례하여 증가하지 않고 모델 capacity를 극적으로 증가시키는 방법입니다. MoE 모델의 sparsely-activated 변형(Switch Transformer, GLaM, V-MoE)에서는 experts의 부분집합이 토큰이나 example별로 선택되므로 네트워크에 sparsity가 생성됩니다. 이러한 모델은 여러 도메인에서 더 나은 확장성과 continual learning 설정(Expert Gate)에서 더 나은 능력을 입증했습니다. 그러나 expert routing 전략이 좋지 않으면 특정 전문가가 제대로 훈련되지 않아 experts가 부족하거나 과도하게 전문화될 수 있습니다.
Method
1. MoE Routing
MoE는 각각의 토큰을 가장 적합한 다수의 전문가에 할당하는 하위 네트워크를 채택하고 각 입력 토큰에 대해 한 명 또는 소수의 experts만 활성화합니다. 각 토큰을 가장 적합한 전문가에게 라우팅하려면 게이팅 네트워크를 선택하고 최적화해야 합니다. 토큰이 전문가에게 매핑되는 방식에 따라 MoE는 sparse하거나 dense할 수 있습니다.
Sparse MoE는 각 토큰을 routing할 때 전문가의 하위 집합만 선택하므로 dense MoE에 비해 계산 비용이 줄어듭니다. 최근에 k-평균 클러스터링, token-expert 친밀도를 최대화하기 위한 선형 할당 또는 해싱을 통해 sparse routing을 구현했습니다. Google의 경우 GLaM 및 V-MoE를 발표했습니다. 둘 다 top-k 토큰 라우팅을 사용하는 sparsely gated MoE를 통해 자연어 처리 및 컴퓨터 비전의 최신 기술을 발전시켜 sparsely 활성화된 MoE 레이어로 더 나은 성능 확장을 보여줍니다. 이러한 이전 작업의 대부분은 라우팅 알고리즘이 각 토큰을 가장 적합한 다수의 전문가에 할당하는 Token-Choice Routing 전략을 사용했습니다.
문제1: Load Imbalance
독립적인 Token-Choice Routing 방식은 종종 experts들간에 load balancing와 활용도 저하로 이어집니다. 즉, 일부 전문가는 대부분의 토큰으로 학습하고 나머지 전문가는 이용도가 낮아 모델 capacity가 낭비되어 전문화되지 않을 수 있습니다. 반면에 과도하게 활용되는 전문가는 메모리 부족을 방지하기 위해 각 단계에서 최대 토큰 수만 받기 때문에 일부 토큰은 처리되지 않는 문제가 있습니다.
또한, step latency는 가장 load가 많은 전문가에 의해 결정될 수 있기 때문에 load imbalance 문제는 step latency를 손상시켜 결국을 추론 시간에 방해를 줄 수 있습니다. 이전에는 이러한 문제를 완화하기 위해 로드 밸런싱에 auxiliary loss을 추가하였는데, 이는 특히 중요한 훈련 초기 단계에서 balanced load를 보장하지 않습니다. 실제로, 우리는 토큰 선택 라우팅의 일부 전문가에 대해 초과 용량 비율이 20%-40%에 도달할 수 있음을 경험적으로 관찰했으며, 이는 이러한 전문가에게 라우팅된 토큰의 상당 부분이 삭제될 것임을 나타냅니다.
문제2: Under Specialization
각 MoE 레이어는 게이팅 네트워크를 사용하여 토큰과 전문가 간의 affinity을 학습합니다. 이상적으로, 학습된 게이팅 네트워크는 유사하거나 관련 있는 토큰이 동일한 전문가에게 라우팅되도록 선호도를 생성해야 합니다.
이전의 sparsely gated networks는 너무 많은 토큰이 단일 전문가에게 라우팅되는 것을 방지하기 위해 추가로 Regularization과 같은 auxiliary loss term을 도입했지만 그 효과는 한계가 있었습니다. 중복 전문가나 충분히 전문화되지 않은 전문가를 생성할 수 있습니다. 과소 전문화는 더 많은 로드 균형 조정을 선호하지만 덜 효과적인 라우팅을 선호하는 큰 보조 손실을 부과함으로써 발생할 수 있습니다. 로드 밸런싱과 전문화를 촉진하기 위한 보조 손실에 대한 올바른 균형을 찾는 것은 토큰 선택 라우팅에서 어려운 일입니다.
문제3: Same Compute for Every Token
token choice routings은 buffer overflow가 있을 때 토큰 삭제를 방지하기 위해 상당한 마진(계산된 용량의 2–8배)으로 expert capacity을 overprovision해야 합니다. load imbalance 외에도 서로 다른 토큰의 상대적 중요성에 관계없이 top-k 함수를 사용하여 각 토큰에 고정된 수의 experts를 할당합니다. 저자는 토큰의 중요성이나 난이도에 따라 다양한 수의 전문가가 서로 다른 토큰을 받아야 한다고 주장합니다.
2. Expert Choice Routing를 통한 Heterogeneous MoE
위의 문제를 해결하기 위해 Expert Choice(EC) Routing 방법을 사용하여 서로 다른 종류의 MoE를 제안합니다. 이는 설계상 완벽한 로드 밸런싱을 달성하며, 다양한 수의 전문가가 토큰을 받을 수 있으므로 모델 컴퓨팅을 보다 유연하게 할당할 수 있습니다.
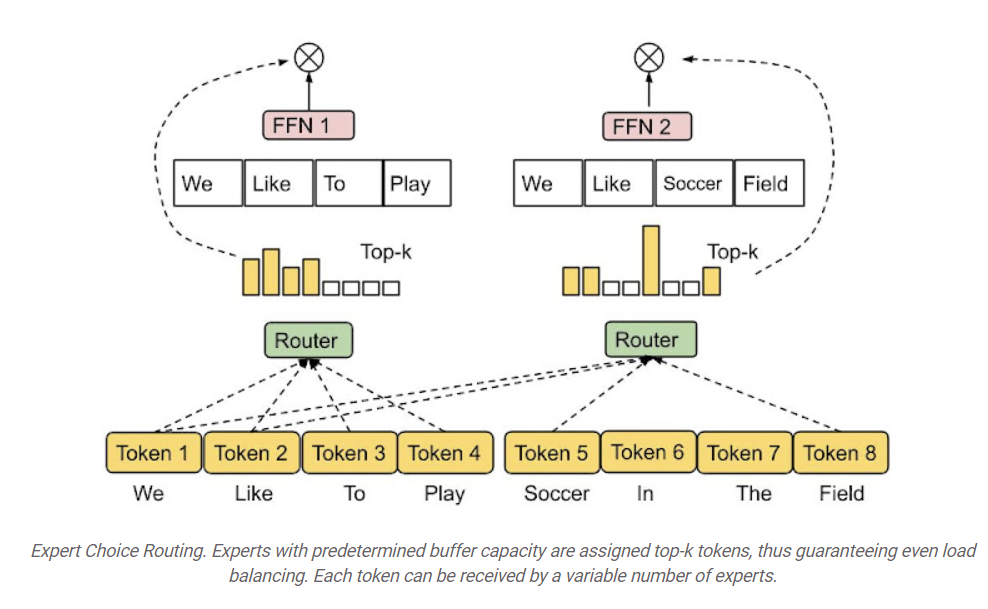
Expert Choice(EC) Routing방법은 각 전문가를 위한 top-k 토큰을 독립적으로 선택합니다. 여기서 k는 고정된 전문가 버퍼 용량, 즉 각 전문가가 수용할 수 있는 토큰의 수를 의미합니다. (토큰이 top-k 전문가를 선택하는 대신, 미리 정해진 버퍼 용량을 가진 전문가가 top-k 토큰에 할당됩니다.)
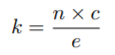
여기서 n은 입력 배치의 총 토큰 수(배치사이즈 × 시퀀스길이), c는 capacity factor, e는 전문가 수입니다. capacity factor c는 평균적으로 토큰이 얼마나 많은 전문가를 활용하는지 나타냅니다.
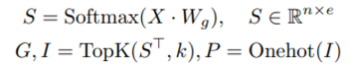
저자는 I, G 및 P 3개의 아웃풋 행렬로 token-to-expert 할당을 생성합니다. 행렬 I는 인덱스 행렬입니다. I[i , j]는 i번째 전문가의 j번째 선택된 토큰을 규정합니다. 게이팅 행렬 G는 선택된 토큰에 대한 전문가의 가중치를 나타내고 P는 각각의 전문가에 대한 토큰을 수집하는 데 사용될 I의 원-핫 행렬을 나타냅니다. 이러한 행렬은 게이팅 함수를 사용하여 계산됩니다.
S는 token-to-expert 선호도 점수, Wg는 전문가 임베딩을 나타냅니다. Switch Transformer, GShard와 유사하게 Transformer 기반 네트워크에서 계산 비용이 가장 많이 드는 부분인 FFN(dense feed-forward) 레이어에 전문가와 게이팅 기능을 혼합하여 적용합니다. 게이트된 FFN에 대한 입력(?Xin)은 순열 행렬 P를 사용하여 생성됩니다. 여기서 Xin[i]는 i번째 전문가의 input을 나타냅니다.
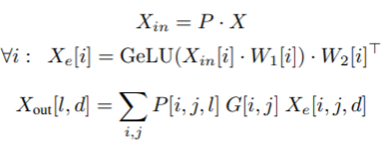
Xe와 Xout은 모두 Einstein 합산(einsum) 연산을 사용하여 효율적으로 계산할 수 있습니다.
또한 각 토큰에 대한 최대 전문가 수를 제한하여 전문가 선택 라우팅을 정규화하는 것을 고려합니다. 이 제약 조건을 추가하면 사전 훈련 및 미세 조정 결과가 개선되는지 여부에 관심이 있습니다. 더 중요한 것은 토큰당 다양한 수의 전문가를 사용하는 것이 모델 성능에 어느 정도 영향을 미치는지 분석하는 데 도움이 된다는 것입니다. A ∈ R e×n을 A[i, j]가 i번째 전문가가 j번째 토큰을 선택했는지 여부를 나타내는 양의 행렬이라고 합니다. 다음 엔트로피 정규화 선형 계획법 문제를 해결합니다.
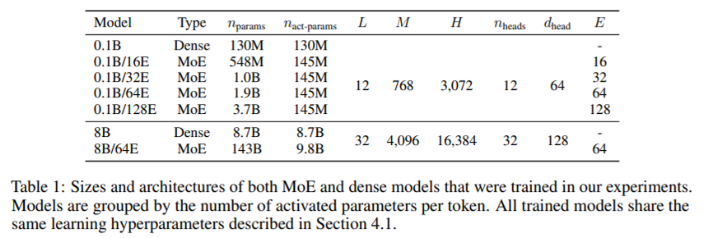
이 방법은 균등한 로드 밸런싱을 보장하고 각 토큰에 대해 다양한 수의 전문가를 허용하며 training efficiency 및 다운스트림 성능에서 상당한 이득을 얻습니다. EC 라우팅은 Switch Transformer, GShard 및 GLaM의 상위 1 및 상위 2 게이팅에 비해 8B/64E(8B parameters, 64 experts) 모델에서 training 수렴을 2배 이상 가속화합니다.
EC routing에서 expert capacity k를 capacity factor가 곱해진 입력 시퀀스 배치에서 expert당 평균 토큰으로 설정하는데, 이는 각 토큰이 받을 수 있는 평균 전문가 수를 결정합니다. token-to-expert 친화도를 배우기 위해 routing결정을 내리는 데 사용되는 token-to-expert score matrix를 생성합니다. 점수 매트릭스는 주어진 전문가에게 라우팅되는 입력 시퀀스 배치에서 주어진 토큰의 가능성을 나타냅니다.
Switch Transformer 및 GShard와 유사하게 Transformer 기반 네트워크에서 계산 비용이 가장 많이 드는 FFN(dense feedforward) 계층에 MoE 및 게이팅 기능을 적용합니다. token-to-expert score matrix를 생성한 후, 토큰 차원에 따라 top-k 함수가 적용되어 각각의 expert가 가장 관련성이 높은 토큰을 선택합니다. 그런 다음 토큰의 생성된 인덱스를 기반으로 순열 함수를 적용하여 additional 전문가 차원에 맞게 hidden value를 생성합니다. 데이터는 여러 전문가에게 분할되어, 모든 전문가들은 토큰의 하위 집합에 동시에 동일한 계산 커널을 실행할 수 있습니다. 고정된 전문가 capacity를 결정할 수 있기 때문에 더 이상 load imbalancing으로 전문가 용량을 overprovision하지 않으므로 GLaM에 비해 훈련 및 추론 단계 시간이 약 20% 크게 단축됩니다.
A REVIEW OF SPARSE EXPERT MODELS IN
DEEP LEARNING
William Fedus∗, Jeff Dean, Barret Zoph∗
4 Sep 2022
Sparse expert models은 딥 러닝에서 인기 있는 아키텍처로 다시 등장한 30년 된 개념입니다. 이 아키텍처 클래스는 Mixture-of Experts, Switch Transformers, Routing Networks, BASE 계층 등을 모두 포함하며, 매개변수의 하위 집합에 의해 작동됩니다. 그렇게 함으로써 희소성의 정도는 매우 크지만 효율적인 모델을 허용하는 example당 계산에서 매개 변수 수를 분리합니다. 결과 모델은 자연어 처리, 컴퓨터 비전 및 음성 인식과 같은 다양한 영역에서 상당한 개선을 보여주었습니다.
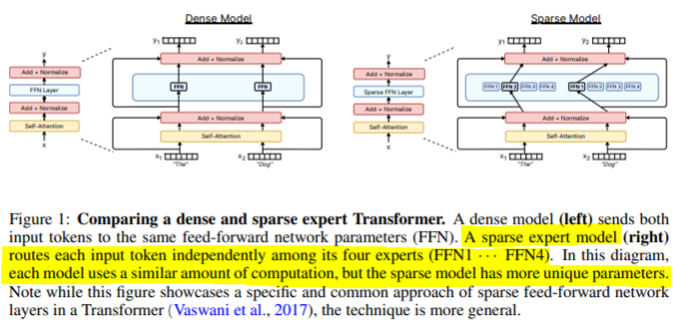
Sparse expert models 중 MoE(Mixture-of-Experts)는 가장 인기 있는 변형으로 parameters 집합이 각각 고유한 가중치를 가진 "“experts”로 분할되는 신경망입니다. 학습 및 추론 중에 모델은 input을 특정 전문가 가중치로 라우팅합니다. 결과적으로 각 example은 전체 네트워크가 각 입력에 사용되는 일반적인 접근 방식과 달리 네트워크 매개 변수의 하위 집합과만 상호 작용합니다. 또한, 전체 모델 크기에 비해 계산량이 적을 수 있습니다.
From Sparse to Soft Mixtures of Experts
Sparse Mixture of Experts
Divide the problem such that different parts are handled by different experts
- 하나의 router에 여러 expert가 있으며, router는 input token들을 받아 이를 처리할 하나 이상의 expert를 결정하고 해당 전문가가 처리할 토큰을 routing합니다. 이러한 전문가는 하나의 큰 모델을 사용하여 모든 토큰을 처리하는 것보다 작을 수 있으며, 병렬로 실행할수 있어 계산비용이 감소합니다. 하지만 routing logic이 discrete optimization으로 이루어 지기 때문에 전문가의 수를 늘리는데 training issue가 있다.
Soft Mixture of Experts
각 전문가에 대한 가중치가 있으며 각 전문가 가중치를 통해 모든 입력 토큰을 전달하여 전문가에 대한 입력(슬롯)을 산출합니다. 프로세스는 각 전문가에 대해 반복되어 모든 input tokens에 대해 도든 weights per slot per expert를 계산하여 linear combinations of input tokens, 즉 slot을 얻고 이를 experts에 input으로 사용한다.
~~각 전문가는 각 슬롯에 대한 출력을 생성한 다음 이를 결합하여 이 토큰이 첫번째 단계에서 얻은 상대적 가중치를 기반으로 최종 결과에서 각 전문가가 각 슬롯에 얼마나 기여해야 하는지 알 수 있습니다. 최종 출력은 다른 유사한 레이어에 연결될 수 있습니다. ~~
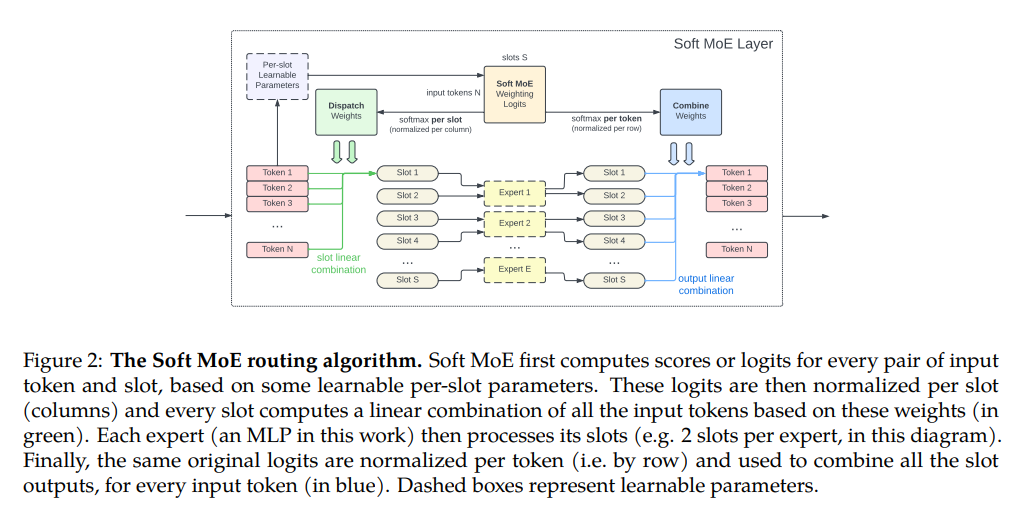 1. Soft MoE Weighting Logits: input token이 slot당 가중치를 통해 전달되어 N*S logit matrix 생성(N: input token 수, S: 모든 전문가의 slot 수)
1. Soft MoE Weighting Logits: input token이 slot당 가중치를 통해 전달되어 N*S logit matrix 생성(N: input token 수, S: 모든 전문가의 slot 수)
2. Dispatch Weights(normalized per column): slot당 softmax 수행. 각 슬롯에 대해 해당 슬롯이 토큰의 영향을 받는 정도의 가중치
3. expert input: slot에 대한 linear combination
4. expert output: expert는 각 slot에 대한 결과 산출
5. Combine Weights:(normalized per row) 원래 logit에 token당 softmax를 하여 토큰별로 전군가 결과를 결합하므로 각 토큰 당 슬롯당 얼마나 중요한지 고려하여 각 토큰에 대한 전문가 슬롯 결과를 적절하게 고려합니다.
Properties of Soft MoEs and connections with Sparse MoEs
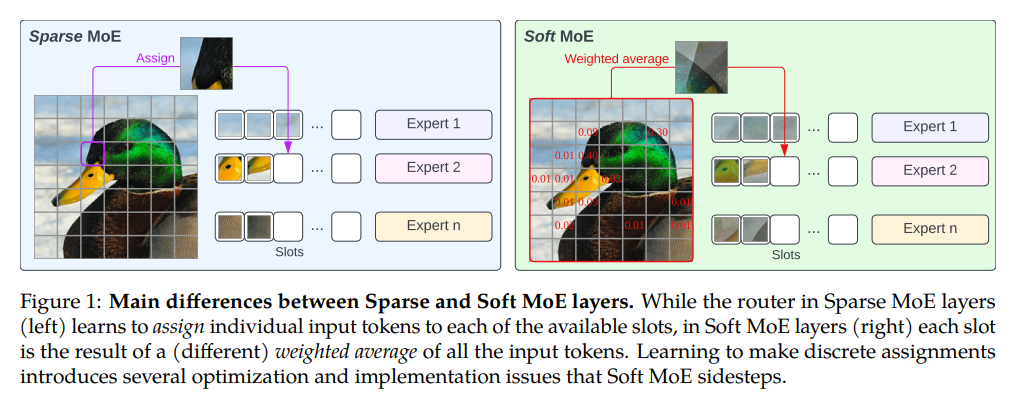 sparse MoE는 expert가 각기 다른 부분을 보고 있지만, soft MoE의 전문가는 입력 토큰의 가중평균으로 채워집니다.
sparse MoE는 expert가 각기 다른 부분을 보고 있지만, soft MoE의 전문가는 입력 토큰의 가중평균으로 채워집니다.
-
Fully differentiable : 모든 Sparse MoE 알고리즘의 핵심에는 토큰과 전문가 간의 할당 문제가 있으며, 이는 일반적으로 특정 용량 및 균형 제약 조건이 적용됩니다. "Expert Choice" 라우터는 각 전문가에 대해 최고 용량 점수 토큰을 선택합니다. 사실상 이러한 접근 방식은 모두 본질적으로 이산적이므로 미분할 수 없습니다. 대조적으로 Soft MoE 레이어의 모든 작업은 연속적이고 완전히 미분 가능하므로, Sparse MoE에서 발생하는 일부 training issue를 해결하는데 도움을 주며, ~~전문가의 수를 늘리는데 도움이 됩니다. ~~
-
No token dropping and expert unbalance :
Top-k 또는 "Token Choice" 라우터는 토큰 누락이나 expert unbalance 문제, "Expert Choice" 라우터는 토큰 누락 문제가 있는 반면, Soft MoE는 기본적으로 모든 슬롯이 모든 토큰의 가중 평균으로 채워지기 때문에 토큰 드롭 및 전문가 불균형에 영향을 받지 않습니다. 모든 가중치는 softmax를 하기 때문에 이론적으로는 양수입니다. -
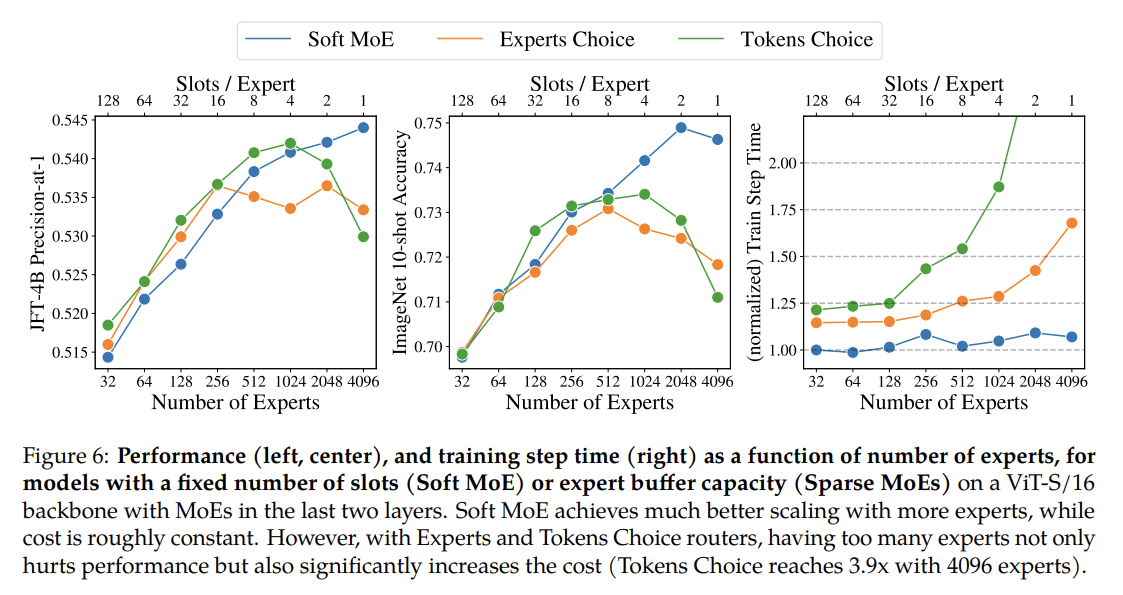
Fast : 총 슬롯 수는 Soft MoE 레이어의 비용을 결정하는 주요 하이퍼파라미터입니다. Soft MoE의 주요 장점은 느리고 일반적으로 하드웨어 가속기에 적합하지 않은 정렬 또는 top-k 작업을 완전히 방지한다는 것입니다. 결과적으로 Soft MoE는 대부분의 드문 MoE보다 훨씬 빠릅니다.
-
Features of both sparse and dense : Sparse MoE의 희소성은 전문가 매개변수가 입력 토큰의 하위 집합에만 적용되는 반면, Soft MoE는 모든 슬롯이 모든 입력 토큰의 가중 평균이기 때문에 기술적으로 sparse하지 않습니다. 모든 입력 토큰은 모든 모델 매개변수를 부분적으로 활성화되어 모든 출력 토큰은 모든 슬롯(및 전문가)에 부분적으로 의존합니다. 따라서, Soft MoE는 모든 전문가가 슬롯의 하위 집합만 처리하기 때문에 모든 전문가가 모든 입력 토큰을 처리하는 Dense MoE가 아닙니다.
-
Per-sequence determinism : 용량 limit을 고려하여 Sparse MoE 은 고정된 크기의 그룹으로 토큰을 라우팅하고 그룹 내에서 balance를 권장합니다.
그룹에 서로 다른 시퀀스 또는 입력의 토큰이 포함된 경우에 토큰은 종종 전문가 버퍼에서 사용 가능한 자리를 놓고 서로 경쟁합니다.결과적으로 모델은 시퀀스 수준에서 더 이상 결정적이지 않고 일부 입력 시퀀스가 다른 입력에 대한 최종 예측에 영향을 미칠 수 있으므로 배치 수준에서만 가능합니다. 더 큰 그룹을 사용하는 모델은 라우팅 알고리즘에 더 많은 자유를 제공하는 경향이 있으며 일반적으로 더 잘 수행되지만 계산 비용도 더 높습니다.Soft MoE는 각 입력 시퀀스의 모든 토큰을 결합하므로 그룹 크기를 단일 시퀀스로 설정합니다. 모든 전문가는 모든 입력의 토큰을 처리하므로 높은 수준의 전문화 정도가 다소 제한될 수 있습니다. 이것은 또한 example마다 결정론적이고 빠르지만 Sparse MoE의 일반적인 인스턴스는 그렇지 않다는 것을 의미합니다.
-
Normalization :
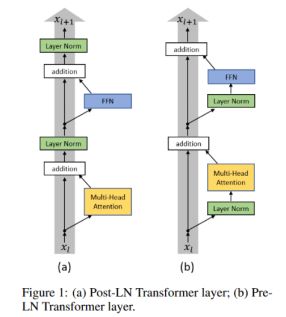
트랜스포머에서 MoE 레이어는 일반적으로 각 인코더 블록의 feedforward layer를 대체하는 데 사용됩니다. 따라서 대부분의 최신 트랜스포머 아키텍처로 pre-normalization를 사용할 때 MoE 레이어에 대한 입력은 "layer normalized"됩니다. 이것은 softmax가 d → ∞로 원-핫 벡터에 접근하기 때문에 모델 차원 d를 스케일링할 때 안정성 문제를 야기합니다(부록 E).

 그래서 알고리즘 1의 라인 3에서 X와 Phi를 각각 l2_normalize(X, axis=1)와 scale * l2_normalize(Phi, axis=0)로 바꿉니다. 여기서 scale은 학습 가능한 스칼라이고, l2_normalize는 알고리즘 2와 같이 L2 norm을 갖도록 해당 축을 정규화합니다.
그래서 알고리즘 1의 라인 3에서 X와 Phi를 각각 l2_normalize(X, axis=1)와 scale * l2_normalize(Phi, axis=0)로 바꿉니다. 여기서 scale은 학습 가능한 스칼라이고, l2_normalize는 알고리즘 2와 같이 L2 norm을 갖도록 해당 축을 정규화합니다.
Connections with other methods
많은 기존 작업은 입력 시퀀스 길이를 줄이기 위해 입력 토큰을 병합, 혼합 또는 융합합니다. 고정된 key가 있는 가중 평균과 같이 시퀀스 길이와 관련하여 self-attention의 quadratic cost을 완화하려고 시도합니다. Dispatch 및 Combine 가중치는 이러한 접근 방식과 유사한 방식으로 계산되지만, 우리의 목표는 시퀀스 길이를 줄이는 것이 아니며 실제로 각 Soft MoE 레이어의 끝에 있는 가중치를 전문가의 출력에 결합한 후 원래 시퀀스 길이를 복구합니다.
Multi-headed Attention은 가중 평균에서 softmax를 사용하는 것 외에 Soft MoE와 몇 가지 유사점을 보여줍니다. h개의 서로 다른 헤드는 서로 다른(선형) 전문가로 해석될 수 있습니다. 차이점은 m이 시퀀스 길이이고 각 입력 토큰의 차원이 d인 경우 h개의 각 헤드가 d/h 크기의 m 벡터를 처리한다는 것입니다. m개의 결과 벡터는 m' 출력 토큰(즉, 어텐션 가중치) 각각에 대해 서로 다른 가중치를 사용하여 각 헤드에서 독립적으로 결합된 다음 각 헤드의 결과 (d/h)차원 벡터가 차원 중 하나로 연결됩니다. 디. 당사의 전문가는 비선형이며 이러한 전문가의 입력 및 출력에서 크기 d의 벡터를 결합합니다. 마지막으로, 예제의 희소 라우팅을 수행하는 대신 전문가 매개변수의 가중 조합을 사용하는 다른 MoE 작업과의 연결도 있습니다. 이러한 접근 방식은 비용이 훨씬 더 많이 들 수 있지만 완전히 차별화할 수 있습니다. 1) 전문가의 매개변수를 평균화해야 하므로 매개변수가 많은 전문가가 사용될 때 시간 및/또는 메모리 병목 현상이 발생할 수 있습니다. 2) 모든 입력이 매개변수의 서로 다른 가중 조합을 사용하기 때문에 Soft(및 Sparse) MoE만큼 광범위하게 벡터화된 작업을 활용할 수 없습니다.
Current limitations
-
Auto-regressive decoding : Soft MoE의 주요 측면 중 하나는 입력의 모든 토큰을 스마트하게 병합하는 것입니다. 이것은 자동 회귀 디코더에서 소프트 MoE를 사용하는 것을 어렵게 만듭니다. 과거와 미래 토큰 사이의 인과 관계가 학습 중에 보존되어야 하기 때문입니다. 어텐션 레이어에 사용되는 인과 마스크를 사용할 수 있지만 토큰과 슬롯 인덱스 사이에 상관관계를 도입하지 않도록 주의해야 합니다. 이는 각 전문가가 훈련받은 토큰 인덱스에 편향을 일으키기 때문입니다. 자동 회귀 디코더에서 Soft MoE를 사용하는 것은 향후 연구를 위해 남겨둔 유망한 연구 방법입니다.
-
Lazy experts & memory consumption


정보 감사합니다.