[논문리뷰] Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
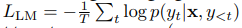
https://arxiv.org/abs/2205.05638
Abstract
- Few shot Incontext Learning은 input으로 training 예시를 넣어 줌으로써 pretrained 모델이 gradient 기반 학습없이 이전에 보지 않은 태스크를 수행할 수 있다.
- parameter-efficient finetuning (PEFT)는 새로운 task를 수행할 수 있도록 작은 양의 parameter로 학습되는 paradigm이다.
- Fewshot ICL과 PEFT를 비교해보며, 더 강력한 성능을 얻기 위해 상대적으로 작은 양의 새로운 파라미터를 도입함으로써 학습된 벡터로 activation을 스케일링한다.
Introduction
ICL
- prompted example을 넣어 task를 수행하는 것으로, few shot prompting은 small input-target pair를 인간이 이해할 수 있는 instruction-example로 변환하여 no-gradient 기반 학습을 한다.
단점 - 모든 prompted input-target pair를 처리하는데 computation cost 발생
- finetuning보다 열등한 성능
- 정확한 prompt의 format은 모델 성능에 중요
PEFT
-
pretrained 모델이 적은양의 추가된 혹은 선택된 파라미터만 업데이트함으로써 fine tuning하여 새로운 태스크를 수행할 수 있도록 하는 추가적인 paradigm이다
-
특정 PEFT 메서드는 mixed-task batches에 따라 하나의 배치 안에 다른 example들을 다르게 처리하여 PEFT와 ICL모두 multitask model에서 실행 가능하다.
이점
- 매우 적은양의 labeled data로 가능
- model, PEFP 메서드, 고정된 셋의 하이퍼파라미터를 제안한다.
- T5의 변형이면서 multitask의 혼합인 prompted dataset에 finetuned된 T0 모델 사용
- 분류와 multiple choice task에서 성능을 높이기 위해서, unliklihood과 length normalization기반 loss term을 추가하였다.
- 학습된 벡터에 의해 intermediate activation을 multiply하는 PEFT 메서드를 개발하였다.
Background
- Few0shot in-context learning(ICL)
- unlabeled query 예제에 따라 input-target prompt (shot)를 넣어줌으로써 task를 수행한다.
- context를 넣어줌으로써 autoregressive 언어 모델을 사용한다.
- 단일 모델로 fine tuning없이 많은 task를 즉시 수행할 수 있어, 배치 안에 다른 예제는 input에 다른 context를 사용함으로써 다른 task에 일치하는 mixed-task batches가 가능하다.
- fewshot learning 가능
- in-context labeled example로 수행하기 때문에 예측하는데 비용이 비싸다.
- transformer에서 self-attention의 quadratic 복잡함을 무시하기 때문에 k-shot ICL에 k training example을 처리하는 것은 unlabeled example을 처리하는 것과 비교해서 (k+1)배 계산 비용이 증가한다.
- 이에 decoder only transformer lm은 causal masking pattern을 가지고 있기 때문에 in-context example을 위한 key-value 벡터를 캐시 처리 할 수 있으며, 이에 따라 context에 대한 model activation은 unlabled example에 의존하지 않는다. - memory cost 또한 k에 선형적으로 비례하여 증가하는 반면, inference동안에는 모델 파라미터를 저장하는데에 의존적이다.
- in-context예제를 저장할 on-disk storage가 요구된다.
- context에서 example의 순서도 영향을 미친다.
- Parameter-efficient fine-tuning
- 학습하기 위해 sparse한 일부 파라미터를 선택하거나, low-rank update를 하거나, 낮은 차원의 suibspace에 최적화를 수행하거나, hypercomplex multiplication을 사용해서 low-rank adpter를 추가하거나 하는 방법 등이 있다.
- 관련하여 promp tuning, prefix tuning은 학습된 continuous embedding에 모델의 input 또는 activation를 concat한다.
- PEFT는 모델을 학습하고 저장하는데 필요한 memory와 storage를 극적으로 줄인다.
- mixed-task batch가 가능하다. 예를들면, prompt tuning은 다른 prompt embedding을 배치 안에 각각의 example에 concat하여 많은 task를 수행할 수 있다.
T-Few
- PEFT는 모델이 상대적으로 적은 양의 storage와 computational cost로 새로운 task에 적용될 수 있다.
Model - 대량의 unlabeled text data로 masked language modeling objective에 따라 사전학습 된 encoder-decoder Transformer model T5의 변형인T0를 기반으로 하였다.
- T0은 zero-shot generalization이 가능하도록 multitask mixture 데이터셋으로 T5를 finetuning시켜 추가적인 gradient기반 학습없이 task를 수행할 수 있다.
- 데이터셋의 예제는 prompt template를 적용하여 prompt된 것을 사용하였다.
- 평가하기 위해 rank classification을 사용하였는데, 모든 가능한 label에 대한 모델의 로그 확률을 rank매겨 가장 높은 rank가 정답이라고 가정하는 것이다.
- 모델의 성능이 사용된 prompt template에 의존성이 높기 때문에, 모든 prompt tamplate에 대해, 그리고 few-shot data subset에 대해 median accuracy로 측정한다.
- Unlikelihood Training and length normalization
- few-shot finetuning의 성능을 높이기 위해 unlikelihood loss term과 length normalization을 추가하였고, sum하여 계산한다.
1) cross-entropy loss
2) unlikelihood loss
평가하기 위해 rank classification을 사용하는데, 이는 모델이 올바른 선택을 하는 확률 뿐만 아니라 부정확한 선택을 할 확률에 따라 달라진다. 학습하는 동안 unlikelihood loss를 추가하여 이를 고려한다.
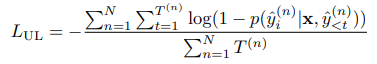
- 부정확한 target sequence로부터 token을 예측하는 것을 막아주어 부정확한 선택에 낮은 확률을 할당함으로써 맞는 선택에 높은 rank를 매기게 되어 성능을 향상시킬 거라고 가정한다.
3) length normalization - rank classification을 수행할 때, 토큰의 수에 따라 각각의 가능한 답변 선택에 대한 모델의 점수를 나눈다.
- length-normalized 평가를 하도록 학습하는 동안 loss term을 추가한다.
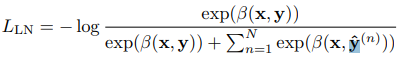
- 주로 multitask choice task에서 학습 예제에 대한 target sequence가 상대적으로 다른 길이를 가지고 있을 수 있다. 확률에 기반하여 각각의 선택을 ranking함으로써 더 짧은 선택을 선호하도록 만든다.
- 주어진 output sequence릐 length-normalized log probability를 계산하고, softmax cross entropy loss를 최소화함으로써 올바른 답변을 선택하는 length-normalziaed로그 확률을 최대화 시킨다.
- Parameter-efficient fine-tuning with (IA)
IA(Infused Adapter by Inhibiting and Amplifying Inner Activations)

Deep learning