[논문리뷰] LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
Microsoft Corporation, 16 Oct 2021
github: https://github.com/microsoft/LoRA
reference: https://arxiv.org/abs/2106.09685
LoRA(Low-Rank Adaptation)는 pretrained model의 모든 weight를 finetuning하는 방법 대신 pretrained model weight를 모두 freeze하고 downstream task를 수행하기 위해 훈련 가능한 rank decomposition matrice를 추가 함으로써 parameter 효율적으로 훈련하는 방법을 제안합니다.
sequential한 방식으로 external module에 추가되었던 adapter 방식과 달리 parallel한 방식으로 추가되어 추가적인 inference latency 없이, 또한 input sequence length를 줄이지 않고 훈련이 가능합니다.
이로써, Adam으로 finetuning한 GPT-3 대비 약 10000배 가량의 파라미터 수를 줄였으며, 3배 가까이 메모리를 줄였으며, RoBERTa, DeBERTa, GPT-2, GPT-3에 finetuning한 것보다 훨씬 더 적은 수의 파라미터로, 더 높은 throughput을 내며, 추가적인 inference latency 없이 훨씬 더 좋은 성능을 내고 있습니다.
Introduction
pretrained language model은 모델의 모든 파라미터를 업데이트 하는 finetuning 방법을 통해 다양한 task에 적용되어 왔습니다. 하지만, 정작 업데이트에 사용되는 파라미터는 극히 일부이기 때문에 비효율적으로 자원을 사용하게 됩니다.
이에 downstream task를 위해 external module을 학습하거나 몇몇 파라미터만 adapt하는 방식이 제안되어 왔으며, 각각의 task를 수행하기 위한 pretrained model에 적은 양의 task-specific parameter를 저장하고 로드하는 것을 제안되어 왔습니다.
하지만, 기존의 방식으로는 model depth를 늘림으로써 inference latency가 유도되거나, 모델의 입력 가능한 문장 길이를 줄여야 하여 효율성과 model quality간의 trade off를 고려해야 하며, finetuning 베이스라인에 맞지 않습니다.
따라서, 본 논문의 저자는 over-parametrized model이 실제로 낮은 고유 차원에 있음을 보여주는 Li et al. (2018a); Aghajanyan et al. (2020)의 논문에 영감을 받아 모델 adaptation하는데 가중치의 변화 또한 low "intrinsic rank"를 가지고 있다고 가정하고 LoRA를 제안합니다.
LoRA는 사전 훈련된 가중치를 고정시키는 대신, adaptation 동안 dense layer 변화의 rank 분해 행렬을 최적화 하여 신경망에서 dense layer를 간접적으로 학습시킵니다. GPT-3 175B를 예로 들면, 전체 rank(d=12888)가 매우 낮은 rank(r=1 or 2)로 충분하며, 이로써 스토리지와 컴퓨팅 자원의 효율성 또한 높일 수 있음을 보여줍니다.
Benefits
-
replace LoRA for each downstream task, not finetuning all parameters
사전 학습된 모델은 LoRA 모듈이 서로 다른 task에 빌드하도록 공유되고 사용될 수 있습니다. 사전 학습 모델의 매개변수를 동결시키고 이를 행렬 A와 B로 대체함으로써 스토리지 요구 사항과 작업 전환 오버헤드를 크게 줄일 수 있습니다. -
no store gradient & just optimize low rank decomposition matrice
LoRA는 adaptation 옵티마이저를 사용해서 대부분의 매개변수에 대한 옵티마이저 상태를 유지하거나 그래디언트를 계산할 필요가 없기 때문에 학습을 보다 효율적으로 만들고 진입에 대한 하드웨어 장벽을 최대 3배까지 낮춥니다. 대신 추가된 low-rank 행렬을 최적화시킵니다. -
no inference latency
간단한 선형 구조로 추가적인 inference latency (input이 들어가서 모델이 예측을 하기까지 걸리는 시간)없이 훈련 가능한 행렬을 동결시킨 가중치와 병합할 수 있습니다. -
Combining LoRA with prefix tuning
LoRA는 기존에 존재하는 많은 방식들과 직교하기 때문에 prefix 기반 접근과 함께 사용될 수 있습니다.
Method
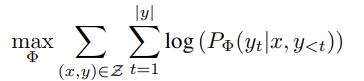
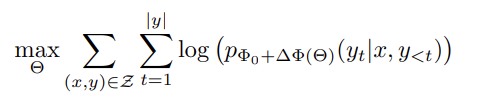
- ∆Φ = ∆Φ(Θ) (|Θ| << |Φ0|)
- ∆Φ를 찾는 태스크는 결국 Θ에 대한 최적화가 됩니다.
- ∆Φ를 인코딩 하기 위해서 compute, memory 효율적인 low-rank representation을 제안합니다.
기존에 효율적인 adaptation으로는 1. adapter layer를 external module에 추가하는 것과 2. input layer activation의 몇몇 form을 최적화 시키는 것이 있었는데 두 가지 전략 모두 large scale language model에서는 1. adapter layer는 inference latency를 유도하고 2. 활성화함수 최적화는 prompt를 직접적으로 최적화하는데 어렵다는 한계를 가지고 있습니다.
이에 본 논문의 저자들은 다음과 같은 기법들을 제안합니다.
- Low-Rank-Parametrized update matrices
학습시 low rank행렬 A와 B를 업데이트하고, pretrained model의 initialized weight인 W0는 동결시키고 gradient update를 하지 않습니다.
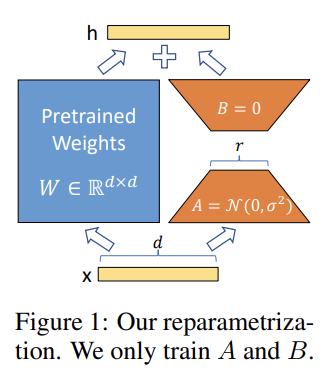
- h = W0x + ∆W x = W0x + BAx
- A는 랜덤 가우시안 초기화, B는 0으로 초기화 되서 ∆W는 학습 초기에는 0입니다. ∆W는 α/r로 스케일링 합니다. (α는 r에서의 constant) Adam으로 최적화할 때 초기화를 적절히 스케일링 했다면, α를 튜닝하는 것은 lr을 튜닝하는 것과 같습니다. 결과적으로 단순히 α를 우리가 시도한 첫 번째 r로 설정하고 조정하지 않습니다.
- Applying LoRA to Transformer
LoRA는 학습 가능한 매개변수의 수를 줄이기 위해 신경망에서 어떤 가중치 행렬의 부분집합에 적용이 가능할지 고민하다 저자는 parameter-efficiency를 위해 downstream task에 대해서 attention weight만 adapting하고 MLP에서는 동결시킵니다.
Limitation
추가 추론 대기 시간을 제거하기 위해 A와 B를 W로 흡수하기로 선택한 경우 단일 순방향 패스에서 A와 B가 다른 여러 작업에 대한 입력을 배치 처리하는 것은 간단하지 않습니다. 가중치를 병합하지 않고 대기 시간이 중요하지 않은 시나리오의 경우 배치에서 샘플에 사용할 LoRA 모듈을 동적으로 선택할 수 있습니다.
Experiment
Baseline
-
Prefix-embedding tuning (PreEmbed)
input token에 special 토큰 lp(prefix 토큰의 개수)와 li(infix 토큰의 개수)를 주입시킵니다. 학습 가능한 word embedding을 가지고 있고 model vocab에는 포함되어 있지 않습니다. "prefixing"에 초점을 맞춰서 prompt에 그런 토큰을 배치하고 infixing을 해서 prompt에 추가합니다. 학습가능한 매개변수의 개수는 다음과 같이 계산합니다.
|Θ| = d_model × (lp + li) -
Prefix-layer tuning (PreLayer)
prefix-embedding tuning의 확장버전으로 word embedding이나 embedding layer 다음 activation만 학습하는게 아니라 모든 트랜스포머 레이어 이후 actication을 학습합니다. 학습가능한 매개변수의 개수는 다음과 같이 계산합니다.
|Θ| = L × dmodel × (lp + li) -
Adapter tuning
self attention module과 residual connection사이에 adapter layer를 추가하는 것입니다.
AdapterH : 중간에 비선형성이 있는 어댑터 레이어에는 bias를 가진 2개의 fully connected layer가 있다. (original)
AdapterL : MLP 모듈과 LayerNorm 후에만 적용되는 adapter layer로 되어 조금 더 효율적
AdapterP : AdapterDrop 포함 -
LoRA
LoRA는 기존 가중치 행렬과 pararrell하게 훈련 가능한 rank decomposition 행렬 쌍을 추가합니다. 단순하게 LoRA를 Wq 및 Wv에만 적용합니다. 학습 가능한 매개변수의 수는 rank r과 원래 가중치의 모양에 따라 결정됩니다.
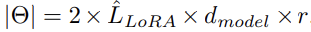
LˆLoRA : LoRA를 적용하는 가중치 행렬의 개수
학습된 weight는 추론 중 main weight로 merge함으로써 어떠한 latency도 일으키지 않습니다.
- LoRA+PrefixEmbed (LoRA+PE)
prefix-embedding tuning과 결합한 형태로, special토큰 l_p + l_i를 넣어줍니다. 이러한 embedding은 훈련 가능한 매개변수로 취급됩니다.
6.LoRA+PrefixLayer (LoRA+PL)
prefix-layer tuning과 결합한 형태로, special 토큰 l_p + l_i를 넣어줍니다. 그러나 토큰의 hidden representation을 모든 Transformer 블록 후에 input-agnostic vector로 대체합니다. 따라서, 임베딩과 활성화함수는 훈련 가능한 매개변수로 취급됩니다.
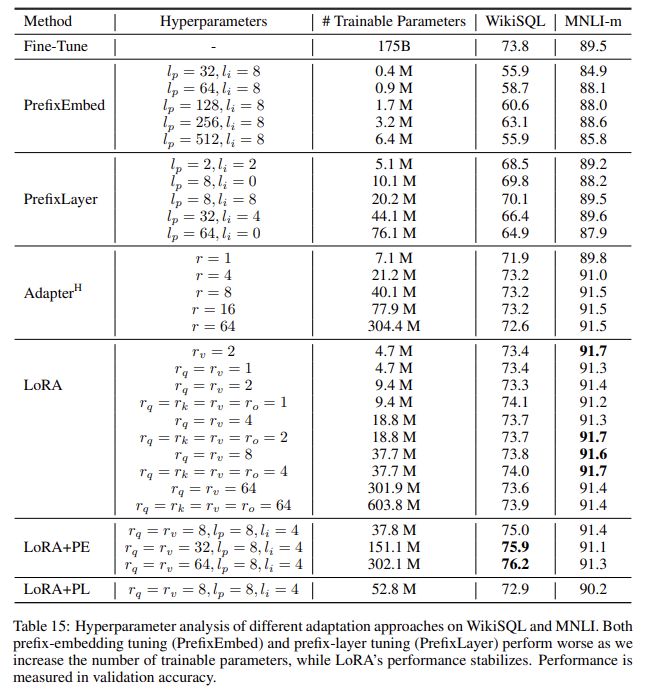
- 훈련가능한 매개변수의 수를 늘리면 PrefixEmbed 와 PrefixLayer 모두 성능이 안좋지는 반면 LoRA는 안정적입니다.
- LoRA+PrefixEmbed (LoRA+PE)가 LoRA와 LoRA+PrefixLayer (LoRA+PL)보다 성능이 좋은데 LoRA가 prefix-embedding tuning에 다소 orthgonal하기 때문입니다.
- LoRA+PrefixLayer (LoRA+PL)는 LoRA보다 더 많은 매개변수로 훈련했음에도 불구하고 성능이 좋지 않은데 prefix-layer tuning은 lr 선택에 민감해서 LoRA+PL에서 LoRA 가중치를 최적화 시키는데 어렵기 때문입니다.
Low-Rank Update란?
downstream task로 부터 학습된 low-rank adaptation은 parallel하게 훈련 가능하여 하드웨어의 장벽을 낮출 뿐만 아니라, 업데이트된 가중치가 어떻게 사전학습된 가중치와 상관관계가 있는지 더 잘 설명해 줄 수 있습니다.
어떤 가중치 행렬에 LoRA를 적용해야 하는가?
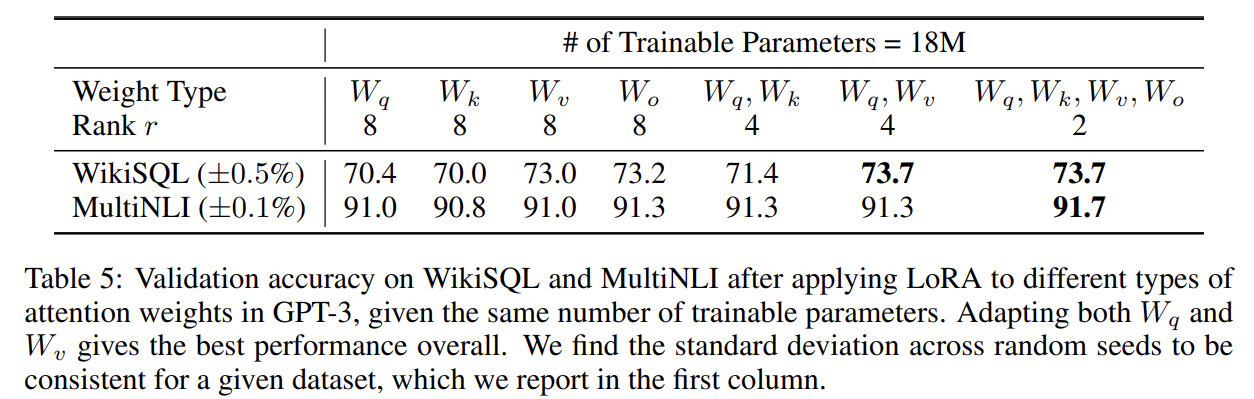
- 모든 파라미터에 적용하는 것 보다 W_q와 W_v에만 적용하는 것이 가장 좋은 성능을 보임을 확인할 수 있다.
- rank가 4인 경우에도 ∆W에서 충분한 정보를 캡처하므로 rank가 더 큰 단일 유형의 가중치를 적용하는 것보다 더 많은 가중치 매트릭스를 적용하는 것이 바람직하다는 것을 의미합니다.
LoRA를 위한 최적의 rank는 무엇인가?
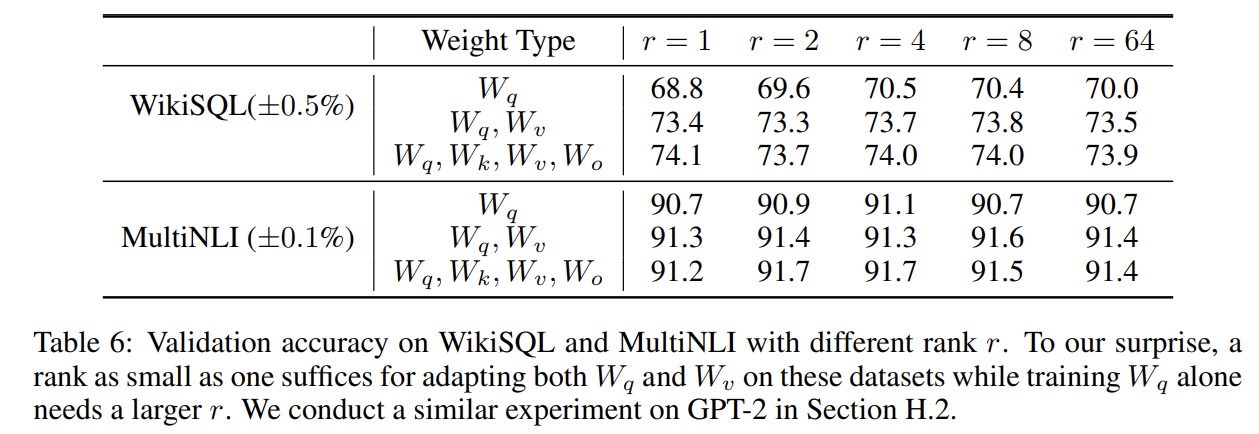
- update matrice rank는 작은 intrinsic rank를 가지고 있으며, r이 증가한다고 더 의미있는 subspace를 커버하지 않아 low-rank adpatataion 행렬로도 충분함을 제안합니다.
r의 크기에 따라 학습된 subspace의 유사성
rank 8과 64로 학습한 adaptation 행렬을 singular value decomposition해서 얻은 right-singular unitary 행렬은에서 top i singular vector에 의해 얼마나 많은 subspace가 span되는지 Grassmann 거리기반 normalized subspace 유사도를 정량화 해보면,
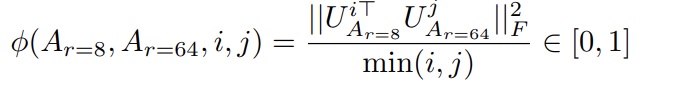
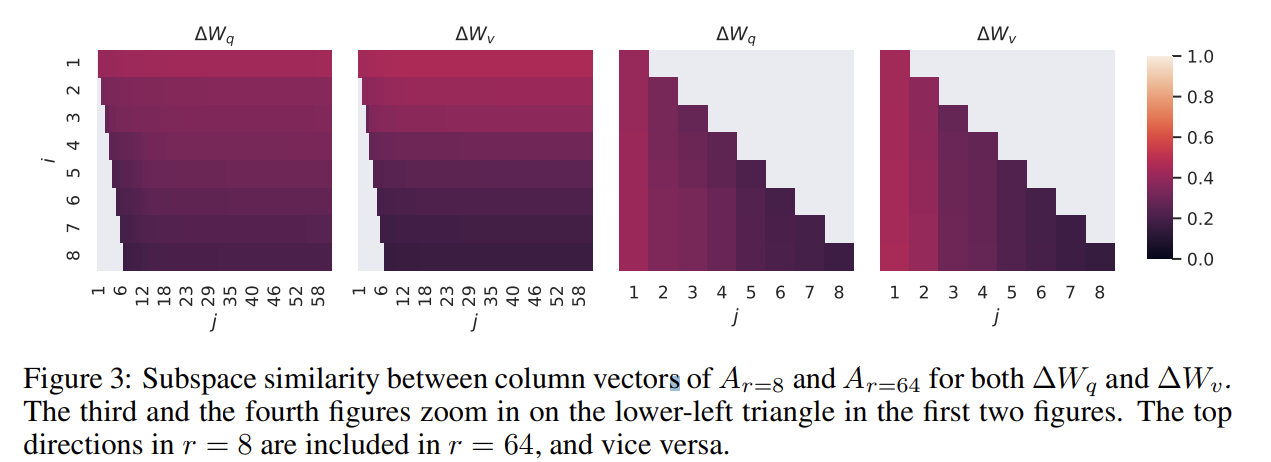
- top singular vector에서 overlap이 일어나며 유용한 반면, 다른 방면에서는 학습 과정중에 축적된 random noise가 있음
- 따라서, adptation 행렬은 실로 매우 low rank가 가능함.
SVD

- U는 AA.T를 고유값분해(eigendecomposition)해서 얻어진 직교행렬(orthogonal matrix)로 U의 열벡터들을 A의 left singular vector라 부른다.
- V는 A.TA를 고유값분해해서 얻어진 직교행렬로서 V의 열벡터들을 A의 right singular vector라 부른다. (UUT = VVT = E)
- Σ는 AA.T, A.TA를 고유값분해해서 나오는 고유값(eigenvalue)들의 square root를 대각원소로 하는 m x n 직사각 대각행렬로 그 대각원소들을 A의 특이값(singular value)이라 부른다.
adaptation행렬이 기존 가중치 행렬과의 관계

- low rank adaptation 행렬은 학습된 특정 downstream task에 대한 중요 피쳐를 강화하지만 일반적인 사전 학습 모델에서는 강화되지 않는다.
Future work
- 다른 효율적인 adaptation 방법과 결합하여 orthogonal 개선을 가져올 수 있다.
- pretraining 중에 학습된 피쳐가 downstream task에서 잘 수행되도록 어떻게 변환 되는지
- We mostly depend on heuristics to select the weight matrices to apply LoRA to. Are
there more principled ways to do it? - Finally, the rank-deficiency of ∆W suggests that W could
be rank-deficient as well, which can also be a source of inspiration for future works.
