[논문리뷰] QLORA: Efficient Finetuning of Quantized LLMs
- QLoRA(Quantized Low Rank Adapters)는 메모리 사용량을 크게 줄이는 효율적인 파인튜인 접근법으로, 전체 16비트 파인튜닝 성능을 유지하면서 단일 48GB GPU에서 650억 매개 변수 모델을 파인튜닝할 수 있다.
- 이는 frozen된 4비트 양자화 사전 훈련된 언어 모델을 통해 그레이디언트를 낮은 순위 어댑터(LoRA)로 역전파함으로써 가능해진다.
- QLoRA는 성능 저하 없이 메모리를 절약할 수 있는 몇 가지 혁신적인 기능
(a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights
(b) Double Quantization to reduce the average memory footprint by quantizing the quantization constants
(c) Paged Optimizers to manage memory spikes.
QLORA는 성능 하락 없이 메모리를 절약한다.
(1) 4-bit NormalFloat, an information theoretically optimal quantization data type for
normally distributed data that yields better empirical results than 4-bit Integers and 4-bit Floats.
(2) Double Quantization, a method that quantizes the quantization constants, saving an average
of about 0.37 bits per parameter (approximately 3 GB for a 65B model).
(3) Paged Optimizers,
using NVIDIA unified memory to avoid the gradient checkpointing memory spikes that occur when
processing a mini-batch with a long sequence length. We combine these contributions into a better
tuned LoRA approach that includes adapters at every network layer and thereby avoids almost all of
the accuracy tradeoffs seen in prior work.
1.Introduction
1.1 Block-wise k-bit Quantization


1.2 Low-rank Adapters
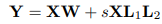
1.3 Memory Requirement of Parameter-Efficient Finetuning
2.Related Work
2.1 Quantization of Large Language Models
추론하는 동안 양자화
많은 LLM은 16 bit LLM 품질을 보존하기 위해 SmoothQuant, LLM.int8()와 같은 아웃라이어 특성을 관리하는데 초점을 둔다.
2.2 Finetuning with Adapters
2.3 Instruction Finetuning
사전학습된 LLM이 프롬프트에 제공된 인스트럭션을 따르도록 하기 위해서 instruction finetuning은 사전학습 된 LLM을 파인튜닝하기 위해 다양한 데이터의 input-output쌍을 사용해서 input으로 프롬프트가 주어지면 아웃풋을 생성한다.
2.4 Chatbots
Instruction을 따르는 모델은 대게 RLHF를 사용하거나 AI모델 피드백으로 학습하기 위해 기존 모델에서 데이터를 생성하는(RLAIF) 대화기반 챗봇이다.
3.Mechanism
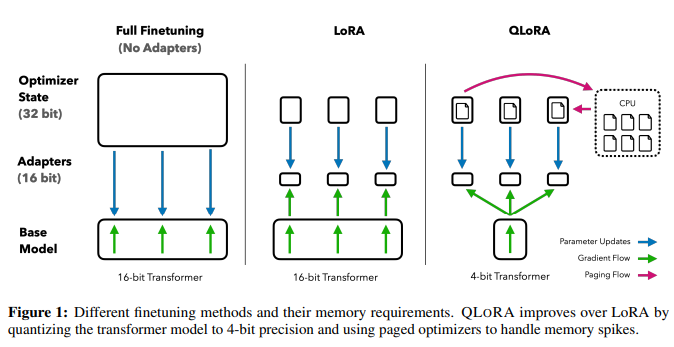
- 4bit finetuning : 정규 분포 가중치에 대해 이론적으로 최적인 새로운 데이터 유형으로, 정규 분포 데이터에 대한 양자화 데이터 유형으로 4비트 정수 및 4비트 부동 소수점보다 경험적 결과가 더 좋다.
- Double Quantization : 양자화 상수를 양자화하여 평균 메모리 설치 공간을 줄인다. 첫 번째 양자화의 양자화 상수를 두 번째 양자화에 대한 입력으로 처리한다. 이 두 번째 단계는 양자화 상수와 두 번째 수준의 양자화 상수를 산출합니다. 이 방법은 매개 변수당 메모리 설치 공간을 0.625비트에서 0.252비트로 줄여 매개 변수당 0.373비트를 줄인다.
- Paged Optimizers : 그래디언트 체크포인팅 도중에 메모리 spike가 oom을 야기시키는 것을 방지하는데 사용된다. NVIDIA 통합 메모리 기능을 사용하여 CPU와 GPU 간에 자동 페이지 간 전송을 수행하여 GPU 메모리가 가끔 부족해지는 시나리오에서 오류 없는 GPU 처리를 수행한다.
- QLORA 낮은 precision 저장 데이터 타입을 가지고 (논문의 경우에는 4bit) 보통 연산 데이터 타입으로는 BFloat16를 가진다. QLoRA 가중치 텐서가 사용될 때마다 텐서는 BFloat16으로 역양자화되서 16 bit레서 행렬 곱이 이루어진다.
3.1 4-bit NormalFloat Quantization
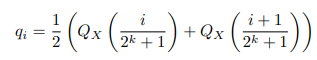
NormalFloat(NF)는 정규분포 가중치를 보다 효율적으로 처리하도록 특별히 설계된 정보 이론적으로 최적의 데이터 유형이다. NormalFloat은 bin에 걸쳐 값의 불균일한 분포를 초래하는 전통적인 양자화 방법과는 다르게, 각 양자화 bin이 입력 텐서에서 할당된 동일한 수의 값을 갖도록 보장하는 분위수 양자화로 한 단계 더 발전한 버전이다. NF4 데이터 유형은 표준 정규 분포의 분위수를 추정하여 정규 분포를 위한 4비트 분위수 양자화 데이터 유형을 생성한다. 그 다음 이 데이터 유형의 값이 특정 범위로 정규화된다. 이 방식은 사전 훈련된 모델을 4비트로 양자화하여 큰 매개 변수 모델을 파인튜닝하는 데 필요한 메모리 요구 사항을 크게 줄일 수 있으면서 중요한 정보를 잃지 않고 모델을 압축할 수 있기 때문에 유용하다.
사전학습된 신경망 가중치는 일반적으로 0 중심, 표준 편차 σ 정규 분포를 갖기 때문에 모든 가중치를 분포가 데이터 유형의 범위에 정확히 맞도록 σ를 조정함으로써 단일 고정 분포로 변환할 수 있습니다. 저자는 [-1, 1] 사이 임의의 범위에 맞췄고, 그렇기 때문에 데이터 유형과 신경망 가중치에 대한 분위수를 이 범위로 정규화되어야 합니다.
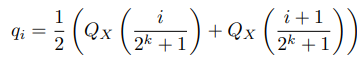
(1) k-bit 분위수 양자화 데이터 유형을 얻기 위해 이론적으로 N(0, 1) 분포를 띤 2^k + 1 분위수를 측정
(2) 이 데이터 유형을 가지고 그 값을 [-1, 1] 범위로 정규화
(3) 입력 가중치 텐서를 absolute 최대 크기 리스케일링을 통해 가중치 텐서를 [-1, 1] 범위로 정규화함으로써 양자화(k-bit 데이터 타입의 표준편차에 맞추기 위해 가중치 텐서의 표준편차를 리스케일링하는 것과 같은 의미이다)
가중치 범위와 데이터 타입 유형의 범위가 맞으면, 우리는 일반적으로 양자화 할 수 있다.
여기서, QX(·)는 표준정규분포의 분위수 함수이다. 대칭적인 k-bit 양자화는 0의 정확한 representation을 갖지 않는다. 그래서 패딩과 다른 0인 요소를 오류 없이 양자화하는 중요한 속성입니다.
0의 개별 영점을 보장하고 k-bit 데이터 유형에 대한 2^k 비트를 모두 사용하려면, 범위 qi의 분위수 qi를 추정하여 비대칭을 생성합니다: negative part: 2^(k−1) & positive part: 2^(k−1) + 1
그리고 우리는 이러한 qi 세트를 통합하고 둘 다에서 발생하는 두 개의 0 중 하나를 제거합니다.
설정합니다. 각 양자화 빈에서 동일한 예상 값 수를 갖는 결과 데이터 유형을 용어
k비트 NormalFloat(NFk), 데이터 유형이 정보 이론적으로 제로 중심에 최적이기 때문입니다.
정상적으로 분포된 데이터. 이 데이터 유형의 정확한 값은 부록 E에서 찾을 수 있습니다.3.2 Double Quantization
- 양자화하는 과정에서 추가 메모리 절약을 위한 양자화 상수를 양자화하여 메모리 설치 공간을 더욱 줄인다.
- 정확한 4비트 양자화를 위해서는 작은 블록 크기가 필요하지만 상당한 메모리 오버헤드가 있음
- 예를 들어 32bit 상수와 가중치에 대한 64 blocksize를 사용하면, 양자화 상수는 파라미터당 평균 32/64=0.5bit를 더한다. Double Quantization는 양자화 상수에 메모리를 줄인다.
1) 모델의 가중치는 더 낮은 비트 표현으로 양자화
메모리 사용량을 줄이는 데 효과적이지만 고유한 메모리 풋프린트를 갖는 양자화 상수도 생성
2) 양자화 상수를 두 번째 양자화에 대한 입력으로 받아 양자화 상수와 두 번째 수준의 양자화 상수를 산출
결과적으로, 매개 변수당 메모리 설치 공간이 크게 감소하여 더 큰 모델을 메모리에 올릴 수 있으며, 부가적인 하드웨어 리소스 없이 더 크고 복잡한 모델을 처리할 수 있다.
3.3 Paged Optimizers
- GPU에서 oom이 발생하더라도 CPU와 GPU 간에 에러업싱 자동으로 page-to-page 전이를 하는 NVIDIA unified memory feature 사용
- 옵티마이저 상태에 페이징된 메모리를 할당한 다음 GPU가 메모리가 부족할 때 자동으로 CPU RAM으로 제거되고 옵티마이저 업데이트 단계에서 메모리가 필요할 때 GPU 메모리로 다시 page되어 제한된 리소스로도 처리할 수 있도록 빅모델을 단순화하고 관리하는데 도움을 준다.
3.4 QLORA
양자화된 베이스 모델 내 single linear layer에 단일 LoRA 어댑터로 QLoRA를 구현할 수 있다. 낮은 순위 어댑터는 4비트 양자화 사전 훈련된 언어 모델에 추가되고 그레이디언트는 파인튜닝동안 이 냉동된 양자화 모델을 통해 LoRA로 역전파된다. 파인튜닝 시 메모리 요구 사항을 크게 줄여 단일 GPU에서 대형 모델을 미세 조정할 수 있게 한다.

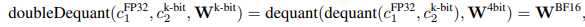
- 가중치에는 NF4, c2에는 FP8 사용
- 가중치는 양자화 정확성을 높이기 위해서 64 blocksize, c2에는 메모리 보존을 위해 256 blocksize
- 파라미터 업데이트는 4-bit 가중치에 대한 업데이트가 아니라

어댑터 가중치에 대한 에러로만 파라미터 업데이트
-> QLoRA는 보통 4-bit NormalFloat로 하나의 storage data type, 16-bit BrainFloat로 computation data type을 갖는다. 저자는 forward, backward pass를 하기 위해 storage data type을 the computation data type로 dequantize 하지만 16-bit BrainFloat.를 사용하는 the LoRA parameters에 대한 weight gradients만 연산한다.
Reference
https://arxiv.org/abs/2305.14314
https://arca.live/b/alpaca/77268012?p=1
