[논문리뷰] Code LLMs
SQL-PALM: IMPROVED LARGE LANGUAGE MODEL ADAPTATION FOR TEXT-TO-SQL
- Few-shot SQL-PALM은 execution 기반 self-consistency prompting 접근
Introduction
- Seq-to-seq 구조
- SQL 특화된 디자인과 도메인 지식을 가지고 T5와 같은 중간 사이즈 모델을 파인튜닝해서 놀라운 성과를 보였다.
- PICARD는 auto-regressive decoding을 제한하기 위해 incremental parsing 사용
- RASAT는 db schema를 relation-aware self-attention과 통합하고 auto-regressive decoder 제한하는 트랜스포머 모델
- RESDSQL는 ranking-enhanced encoding과 skeleton-aware decoding 프레임워크를 사용해서 db schema linking과 skeleton parsing과 분리
- in-context learning 접근
- CodeX, GPT-3
- DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction
- least-to-most prompting을 사용해서 task를 schema linking, query, classification, decomposition, SQL generation, self-correction의 서브 태스크로 분해 후 GPT-4로 few-shot prompting - self-debugging
- 에러 메시지를 prompt에 추가. LLM이 multiple following rounds of promping 으로 생성된 SQL 아웃풋의 에러를 correct 하도록- CodeX와 GPT-4와 달리 PaLM-2에서는 에러메시지를 프롬프트에 추가해서 성능향상을 보이지 않았습니다. 이에 LLM은 RLHF처럼 피드백을 이용하는 방법을 학습해서 추가적인 여러 턴의 피드백에서 이점을 얻는 파인튜닝이 필요하다고 추측합니다.
2.Related work
LLM은 in-context learning이라고 알려져 있는 prompting을 통해 few-shot, zero-shot learning 능력을 가지고 있다고 알려져 있다. context 개념으로 instruction을 따르는 몇개의 demonstration을 프롬프트에 통합시켜 추가적인 모델 adaptation 없이 같은 포맷으로 새로운 example과 task에 일반화 할 수 있는 것을 보여준다.
prompting 능력은 100B 이상의 사이즈의 모델에 더 좋다고 알려져 있다. in-context learning의 괄목할만한 성공은 CoT, least-to-most prompting, self-consistency-prompting과 같은 진보된 프롬프팅 전략의 디자인에 영감을 받았다. 효과적인 large-shot adaptation 방법으로 FLAN-instruction fine-tuning은 taks를 instruction으로 변환하고 multi-tasks instruction datasets mixture에 파인튜닝 한다. (FLAN은 자연어 instruction과 one-shot example을 데이터셋으로 구성하여 fine-tuning 시켜(Instruction Tuning) unseen task에 대한 zero-shot 성능을 높인 연구이다.) 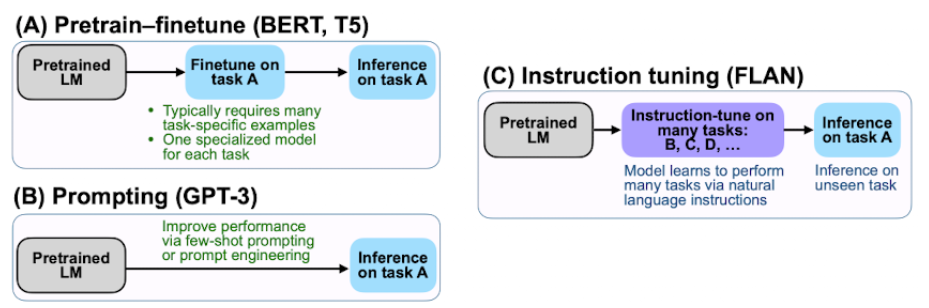

3.Architecture
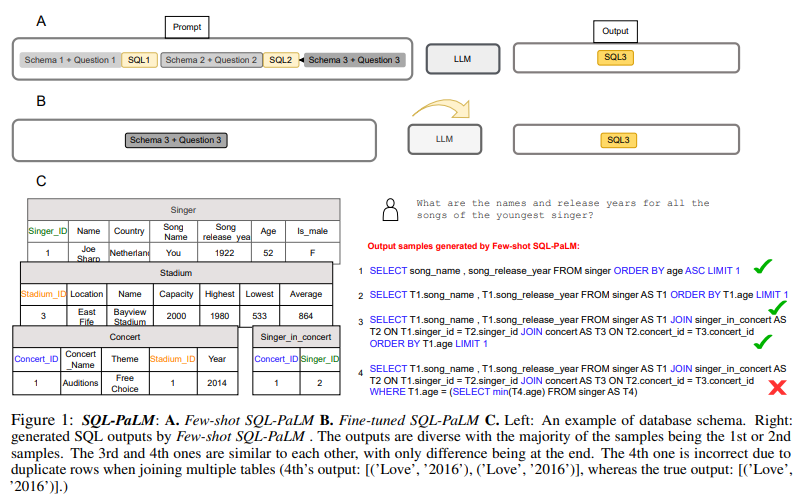
-
PaLM-2 기반 few-shot promping과 finetuning 모두 적용
1) few-shot SQL-PaLM -
execution-based self-consistency-decoding few-shot prompting
execution-based appraches는 코드 생성에서 높은 성능을 보여주고, -
self-consistency : 성능을 높이는 가장 간단한 방법은 LLM을 여러번 샘플링하고 majority (plurality) vote와 같은 발생빈도가 가장 높은 대답을 선택하는 것이다. 그 근거는 여러 추론 경로가 동일한 정답으로 이어질 수 있기 때문에 solution에 대한 추론 경로를 marginalize out함으로써 가장 일관된 대답이 참일 가능성이 높습니다. self-consistency는 샘플의 다양성이 매우 중요합니다. 그러나 본 연구에서 파인튜닝 후 LLM의 샘플링 아웃풋은 높은 sampling temperature를 적용했음에도 불구하고 하나의 답으로 수렴하는 것을 보여주고 있습니다. 이것은 파인튜닝 후에 모델이 선택에 있어 오히려 더 확신이 있다는 것을 의미합니다. 그래서 self-consistency decoding은 그렇게 많이 도움이 된 것으로 보이진 않습니다.
-
예를 들면 같은 질문에 여러개의 다른 SQL로 작성되어있기 때문에 execution-based self-consistency근거는 가장 일관된 execution이 다른 SQL에 의해 생성된 것을 능가해 true execution outcome이 될거 같다는 것이다.
-
그래서 우리는 일관된 execution outcome에 따라 SQL output을 선택한다. 실제로 여러번 샘플링해서 sql output을 db에서 실행시켜 각각의 sql output이 execution outcome을 산출하는지 에러를 산출하는지 확인한다. 모든 execution outcome에서 에러를 제거한 후에 majority vote를 통해 majority execution outcome을 선택한다.
-
prompt는 demonstrations (inputs, SQL) 쌍의 리스트로 질문 앞에 붙이도록 디자인되었다. 여기서, input은 db와 질문을 묘사하는 text로 db 정보는 table, columns, data type과 같은 data schema와 primary key, foreign key를 포함하고 있다.
-
multiple-rounds composite prompt 보다 높은 성능
2) fine-tuned SQL-PaLM
- FLAN-fine-tuning과 같이 multi-diverse tasks로 instruction finetuning해서 large-scale 사전학습으로 부터 전이된 지식으로 초거대 언어모델은 놀랄만한 성과를 보여주고 있다. 하지만 llm을 도메인 스페시픽한 text-to-sql data에 적용하는 것이 필요하며 llm은 prompt형식으로 더 잘 이해할 수 있더 훨씬 더 좋은 결과를 보인다.
- in-context learning과 비슷하게 PaLM-2를 Spider 데이터셋에 db의 description과 natural question을 포함시켜 인풋으로 넣어서 파인튜닝
- finetuning은 overfitting될 가능성도 있기 때문에 robustness를 평가하기 위해 Spider variant에 테스트하지만 EX와 TS에서 few-shot이 더 갭이 적음
4.Experiment
- 평가
- Execution accuracy(EX) : sql 실행문이 gounrd truth와 일치하는지
- Test-suite accuracy(TS) : db 증강으로 생성된 여러 테스트에서 sql이 모두 ex 평가를 통과하는지, EX는 false positives도 포함하기 때문에 TS가 더 믿을만한 metric이다.
Reference
https://arxiv.org/abs/2306.00739
STARCODER: MAY THE SOURCE BE WITH YOU!
Architecture
- 코드와 텍스트 관련 task를 효과적으로 파인튜닝할 수 있는 encoder-only model 학습
- BERT의 Masked Language Modeling(MLM)과 Nex Sentence Prediction(NSP) 목적식을 활용해서 input sentence로 부터 masked-out token 예측, sentence 쌍이 document 내에 이웃으로 존재하는지 예측
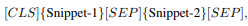
- 두개의 코드 snippet은 랜덤으로 선택되고 두 개의 코드 조각은 동일한 소스 파일의 이웃이거나 두 개의 서로 다른 코드에서 선택됩니다.
- PII detection model
- StarCoderBase : 80+ 프로그래밍 언어, 깃허브 이슈, 커밋, 주피터 노트북 등 1 trillion tokens에 학습
- StarCoder : StarCoderBase 파인튜닝 버전으로 35B 파이썬 토큰에 학습, 15.5B encoder-only model, The Stack 데이터 학습, Fill-in-the-Middle(FIM)을 통해 infilling 능력, multi-query attention를 통해 빠른 large-batch 추론 가능, 8K context length
- 15.5B decoder-only Transformer
- Fill-In-The-Middle(FIM), Multi-Query-Attention(MQA)
- learned absolute positional embedding
- FlashAttention을 사용해서 어탠션 연산 속도를 높이고 메모리 footprint를 줄여 8K context length까지 스케일업 했다.
- 학습동안 FalshAttention이 MQA에 작동하게 하기 위해 attention kernal을 호출하기 전에 간단히 key와 value를 expand
- PII redaction pipeline과 novel attribution tracing tool 추가
Reference
https://arxiv.org/abs/2305.06161
WizardCoder: Empowering Code Large Language Models with Evol-Instruct
- Code Evol-Instruct으로 Code LLM 학습
- 기존의 Code LLMs들은 fine tuning을 하지 않는 반면, WizardCoder는 1. Evol-Instuct 방법을 self-instruct으로 데이터 생성 2. 사전학습된 starcoder를 evolved data로 파인튜닝
- opensource: CodeGen, CodeT5, CodeT5+, CodeGeeX, StarCoder
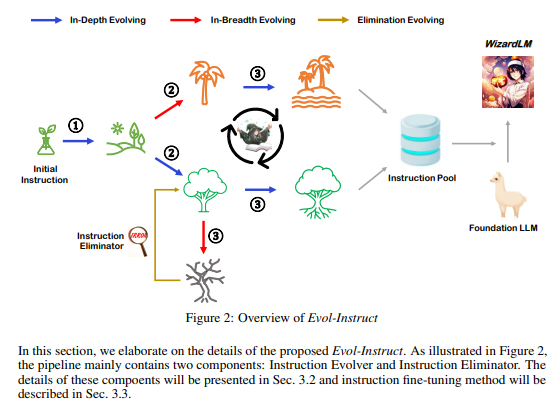
3.Architecture
- WizardLM에 따라 Evol-Instruct 방법을 접목시켜 self-instruct로 생성된 Code Alpaca를 evlove 시키고 evolved data로 사전 학습된 Code LLM StarCoder를 파인튜닝
3.1 Evol-Instruct Prompts for Code
- WizardLM에서 제안된 Evol-Instruct 방법은 코드 instructions을 더 복잡하게 만들어 주어 사전학습된 코드 거대 모델의 파인튜닝 효과를 향상시킨다.
- Evol-Instruct를 코드에 적용하기 위해 evolutaionary prompt에 다음과 같은 수정을 하였다.
- 심화되고 복잡한 인풋과 In-Breadth Evolving를 제거하여 evolutionary instructions 간소화
- evolutionary prompt template을 통합하여 evolutionary prompts 포맷 단순화
- 코드 도메인에 특화된 특성을 해결하기 위해 두 가지 evolutionary
instructions추가 : 코드 디버깅, 코드 시공간 복잡성 제약.
- unified code evolutionary prompt template

{question}은 evolution 될 현재 code instruction, {method}는 evolution 유형을 의미한다.
저자들이 사용했던 5가지 유형은 아래와 같다.

3.2 Training WizardCoder
아래와 같은 과정으로 WizardCoder 학습. 우선 StarCoder 15B를 파운데이션 모델로 사용. Evol-Instruct로 evolve된 code instruction-following training set을 사용해서 파인튜닝. 파인튜닝 prompt format은 아래와 같다. 
학습 데이터셋으로는 20K instruction-following Code Alpaca 데이터를 사용했으며, 20,000개 샘플로 구성된 데이터셋에 반복적으로 Evol-Instruct technique을 실행시켜서 evolved된 데이터 생성
data evolution 매 턴 후에 이전 모든 round의 evolved data와 the original dataset 머징하여 StarCoder 파인튜닝하고 HumanEval에 pass@1 metric 평가. pass@1 metric에서 감소를 보이면 Evol-Instruct 중단하고 최종 모델은 가장 높은 pass@1를 가진 모델로 선택.
4.Experiment
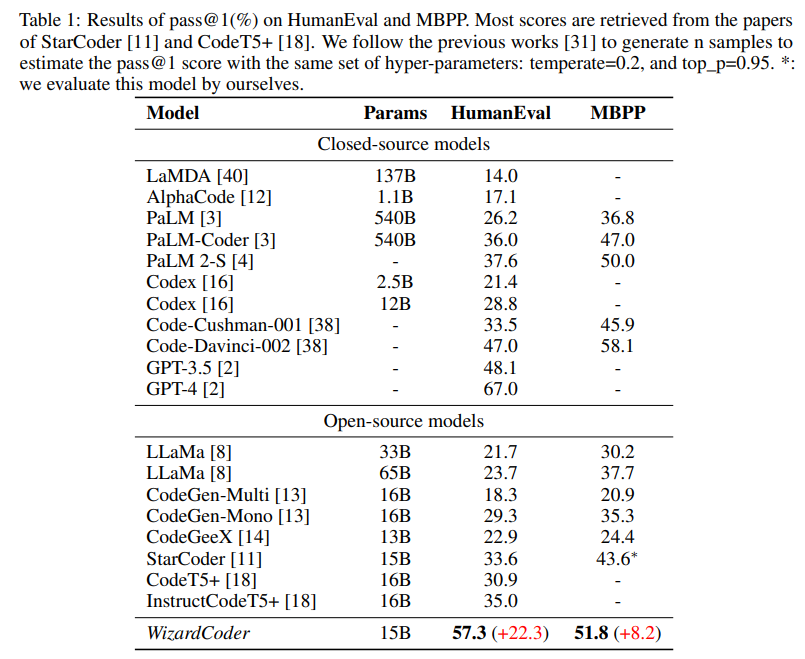
- 4개의 code generation benchmarks 사용: HumanEval, HumanEval+, MBPP, DS-1000
- StarCoder를 기본 파운데이션 모델로 사용.
- evolved dataset은 대략 78k samples
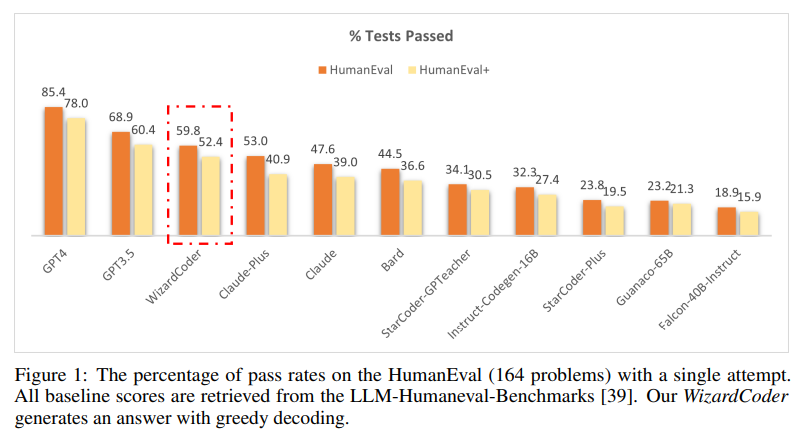
- WizardCoder가 closed-source LLMs, including Claude, Bard, PaLM,
PaLM-2, and LaMDA, despite being significantly smaller 능가 - WizardCoder outperforms all the open-source Code LLMs by a large margin (+22.3 on
HumanEval), including StarCoder, CodeGen, CodeGee, and CodeT5+. - WizardCoder significantly outperforms all the open-source Code LLMs with instructions
fine-tuning, including InstructCodeT5+, StarCoder-GPTeacher, and Instruct-Codegen-16B.
Textbooks Are All You Need
- phi-1 : 1.3B 트랜스포머 기반 모델로 6B token 교과서 퀄리티의 데이터로 학습해서 HumanEval에 pass@1 accuracy 50.6%, MBPP에 55.5% 달성, emergent ability 보임
- Code LLM에서 많이 쓰이는 The Stack 데이터셋은 모델에게 알고리즘적으로 어떻게 추론하고 계획해야 하는지 가르치는데 최적의 데이터가 아니다. 따라서 트랜스포머 기반 분류기를 사용해서 코드 데이터를 필터링하고, 교과서 퀄리티의 CodeTextbook, CodeExercises dataset을 만든다.
Architecture
- decoder-only Transformer 모델
- multi-head attention에 FlashAttention- CodeGen, PaLM, GPT-NeoX와 같이 MHA와 MLP 층은 병렬 구성
- Rotary position embedding (Rotary dimension: 32)
- codegen-350M-mono에 사용한 tokenizer 사용
- 성능을 부스팅하는 Fill-In-The-Middle(FIM)이나 Multi-Query-Attention(MQA)은 사용하지 않음
- pretraining, finetuning할 때 각각의 데이터셋을 파일을 분리하는데 사용되는 “⟨∣endoftext∣⟩” token을 사용하여 single dimensional array로 콘캣
- next-token prediction loss로 모델 학습 (2048 length)
- fp16 training with AdamW optimizer, linear-warmup-linear-decay lr scheduler, deepspeed
