Clustering
데이터에 label이 붙어 있다면 데이터와 label을 기반으로 예측이나 분류를 수행하는 모델을 만들 수 있고 이를 지도학습이라고 한다. 그러나 실제로는 label이 없는 경우가 더 많다. 비지도 학습은 label이 없는 데이터 안에서 패턴과 구조를 발견하는 머신러닝의 방법 중 하나이다. 그 중 가장 대표적인 비지도 학습 방법이 Clustering이다.
Clustering과 Classification의 차이
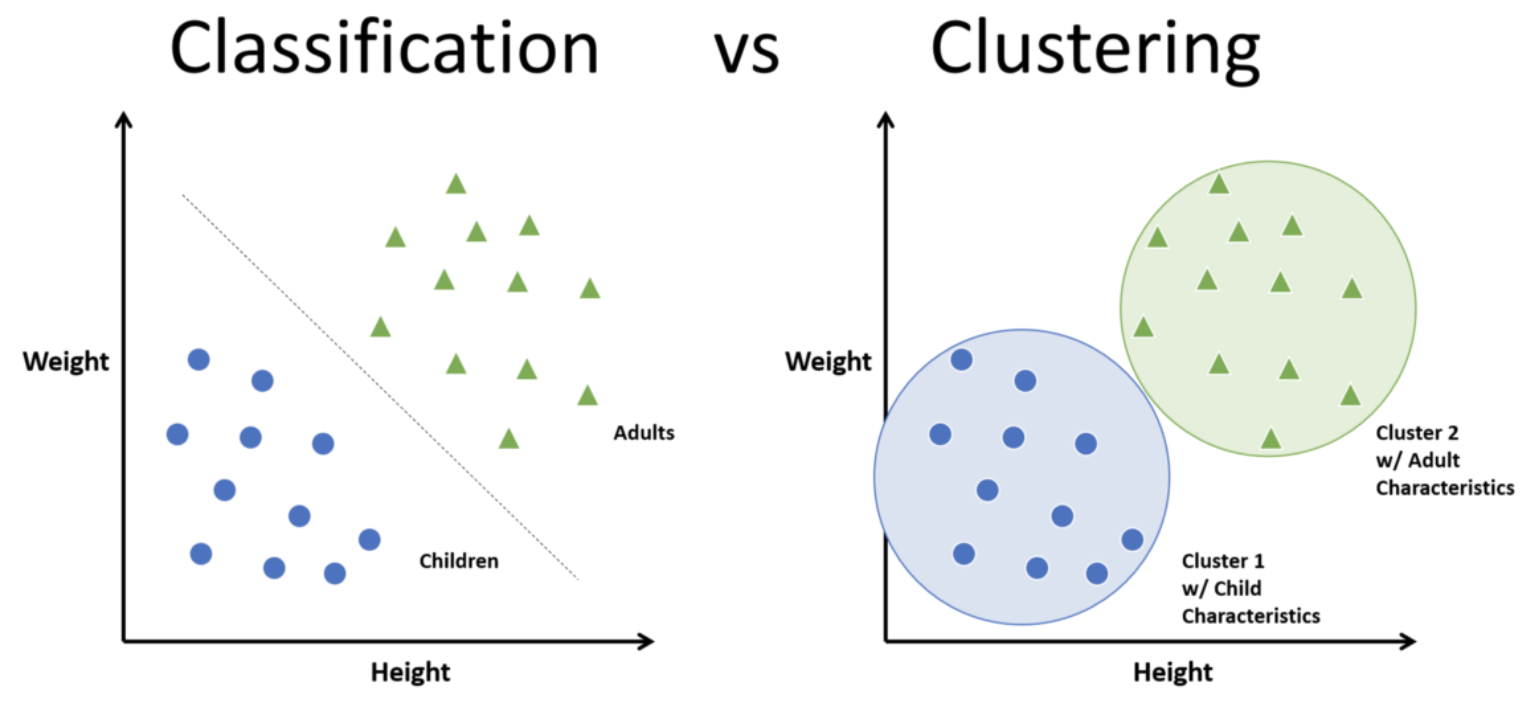
Clustering은 지도학습 모델인 Classification과 다르다. Classification은 미리 label이 있는 데이터들을 학습해서 그걸 바탕으로 새로운 데이터에 대해 분류를 수행하지만, Clustering은 label을 모르더라도 비슷한 속성을 가진 데이터들끼리 묶어주는 역할을 한다는 차이점이 있다.
K-means clustering
K-means에서 K는 cluster의 개수를 의미하고 means는 평균을 뜻하는데 이는 각 cluster의 중심과 데이터들의 평균 거리를 말한다. 즉 mean을 활용하여 K개의 cluster로 묶는다는 의미이다. 이때 K는 우리가 직접 설정해주어야하는 hyper parameter이다.
K-means clustering 은 다음과 같은 과정을 통해 수행된다.
- 데이터셋에서 K개의 centroids(중심)를 임의로 지정한다.
- 각 데이터들을 가장 가까운 centroid가 속한 cluster에 할당한다.
- 2번 과정에서 할당된 결과를 바탕으로 centroid를 새롭게 지정한다.
- 2~3번 과정을 centroid가 더 이상 변하지 않을 때 까지 반복한다.
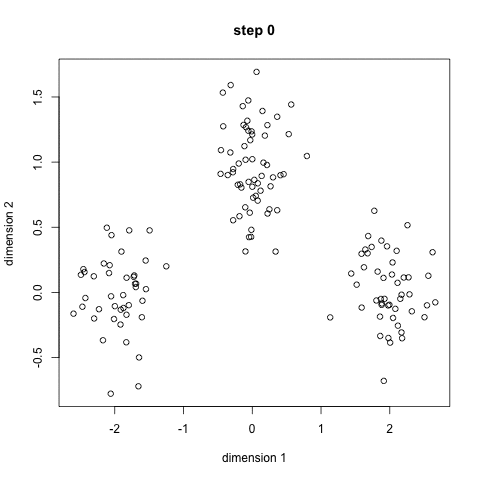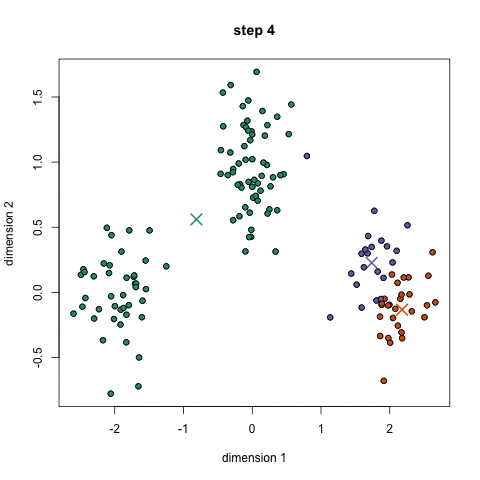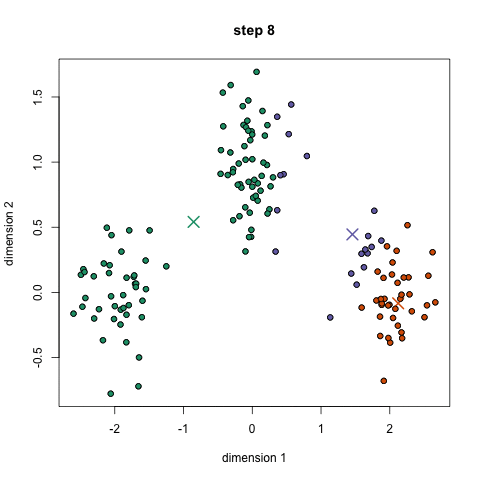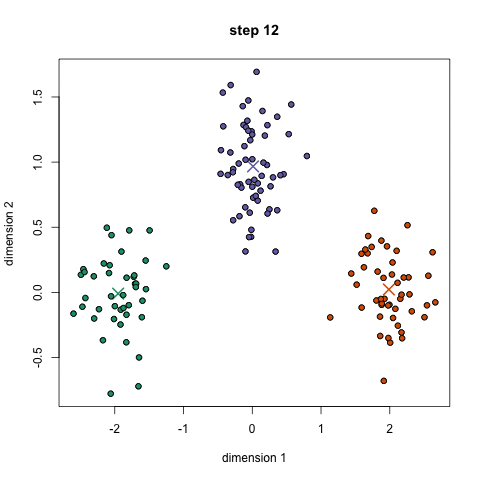
cluster centroid 설정
k-means 알고리즘은 cluster의 초기 centroid를 어떻게 설정하는지에 따라 매번 결과가 달라지기 때문에 centroid를 랜덤하게 설정한다면 optimal한 결과에 converge하는 것을 보장할 수 없다. 따라서 적절한 centroid를 처음에 설정해주는 것이 중요하다.
K-means++
1. centroid를 한 번에 k개 모두 생성하는 것이 아니라, 데이터 포인터 중에서 무작위로 '1개'를 선택하여, 이 데이터를 첫 번째 centroid로 지정한다.
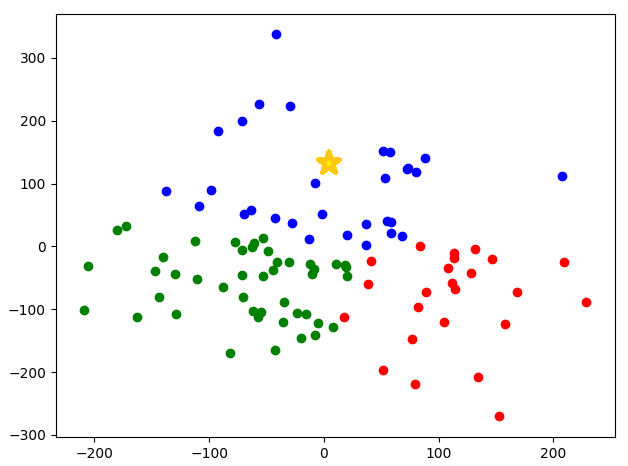 '☆ 모양'의 데이터가 첫번째로 무작위 선정된 센트로이드(Centroid)이다.
'☆ 모양'의 데이터가 첫번째로 무작위 선정된 센트로이드(Centroid)이다.
2. 나머지 데이터 포인터들과 centroid 사이의 거리를 계산한다.
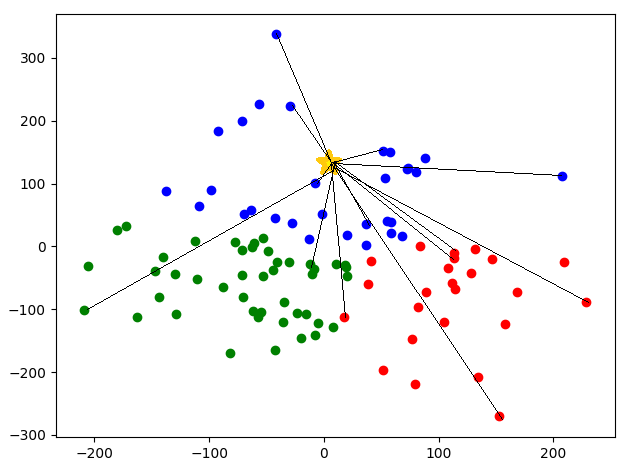 첫번째로 생성한 센트로이드와 나머지 데이터 포인트 사이의 거리를 구한다.
첫번째로 생성한 센트로이드와 나머지 데이터 포인트 사이의 거리를 구한다.
3. 그 다음 생성할 centroid들의 위치는, 데이터 포인터들과 2번 과정에서 계산한 centroid 사이의 거리비례 확률에 따라 선정된다. 즉 데이터 사이의 거리에서 최대한 먼 곳에 다음 센트로이드를 생성한다.
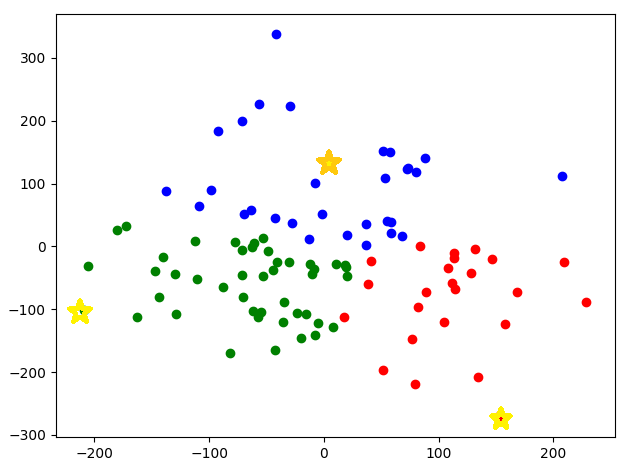 거리 비례 확률에 따라 생선된 k개의 센트로이드
거리 비례 확률에 따라 생선된 k개의 센트로이드
4. 위 과정을 k번 반복하여 총 k개의 centroid를 생성한다.
위 내용을 정리해보자면, 한 번에 k개의 centroid를 생성하는 것이 아니라, centroid 사이의 거리를 최대한 멀리 위치시키는 방향으로 1개씩 총 k번 반복하여 k개의 cluster를 만들어낸다는 뜻이다.
K-means++ 알고리즘은 초기 centroid를 더욱 전략적으로 배치하기 때문에 전통적인 K-Means보다 더 최적의 군집화를 할 수 있다.
또한 K-Means보다 알고리즘이 수렴하는 속도가 빠르다. 전통적인 K-Means를 사용하면 초기 centroid가 잘못 지정되는 경우 알고리즘이 수렴하는 데 시간이 오래 걸릴 수 있기 때문이다.
적절한 K 찾기
1. rule of thumb
가장 간단한 방법으로, 데이터의 수가 n이라 할 때, 필요한 클러스터의 수를 로 설정한다.
2. Elbow Method
cluster centroid와 cluster에 속한 샘플 사이의 거리를 잴 수 있는데, 이 거리의 제곱 합을 inertia라고 한다.
inertia는 cluster에 속한 데이터들이 얼마나 가깝게 모여 있는지를 나타내는 값이다.
일반적으로 클러스터의 개수가 늘어나면 클러스터 개개의 크기는 줄어들기 때문에, intertia 또한 함께 줄어든다.
elbow 방법은 cluster 개수를 늘려가면서 inertia의 변화를 관찰하여 최적의 클러스터 개수를 찾는 방법이다.
K-means 알고리즘에서는 centroid를 기준으로 cluster를 정하기 때문에 cluster 내의 데이터가 centroid로부터 얼마나 떨어져 있냐가 밀집도를 나타낸다. 따라서 inertia가 최소라면 cluster 내의 데이터들이 서로 가깝게 모여 있다는 의미로 볼 수 있고 이는 optimal한 cluster가 만들어 졌다는 것을 의미한다. 따라서 이때가 가장 이상적인 k라고 할 수 있다.
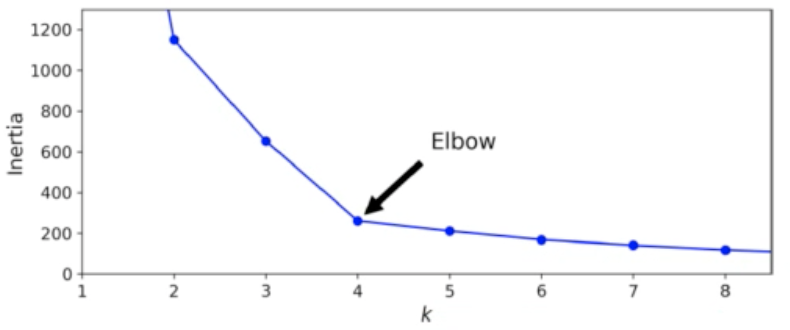
클러스터 개수를 증가 시켜서 intertia를 그래프로 그리면 감소하는 속도가 꺾이는 지점이 있다. 위 그래프에서는 k=4 이후로는 클러스터 개수를 늘려도 클러스터에 밀집된 정도가 크게 개선되지 않으며, 오히려 클러스터가 많으면 의미 없이 여러 개의 cluster로 분류되기 때문에 모델의 효율이 크게 떨어진다.
따라서 해당 그래프에서는 cluster의 개수가 4일 때 inertia가 크게 줄어들지 않기 때문에 모델의 k를 4로 설정하는 것이 가장 적절하다고 할 수 있다.
3. Silhouette Score
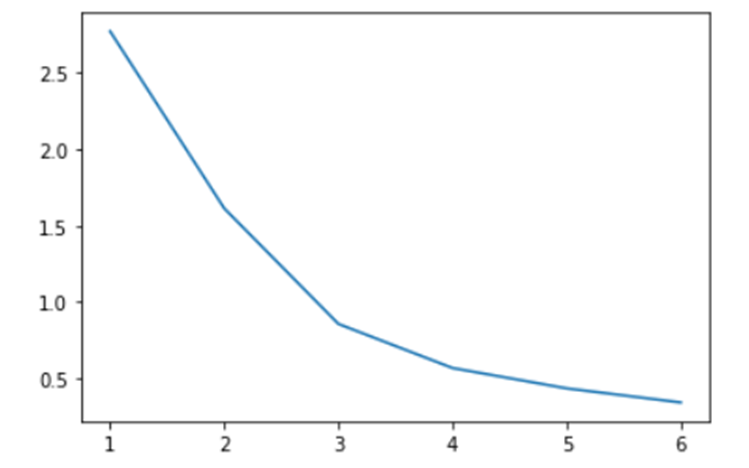
위의 그래프에서는 inertia가 줄어드는 지점을 명확하게 알 수 있었지만 아래와 같은 그래프에서는 적당한 k를 찾는것이 모호하다. 이를 보완하기 위한 방법이 Silhouette score 이다.
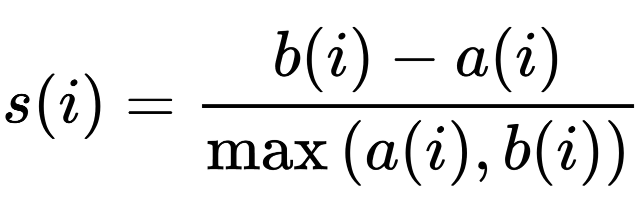
Silhouette score 은 다른 cluster에 비해 자신의 cluster와 얼마나 유사한 지 측정한다. Silhouette score의 범위는 -1에서 +1까지이며, 값이 1에 가까울수록 객체가 자체 cluster와 잘 일치하고 인접 cluster와 잘 일치하지 않음을 나타낸다. 대부분의 개체에 높은 값이 있으면 클러스터링 구성이 적합하다. 많은 포인트의 값이 낮거나 음수이면 클러스터링 구성에 클러스터가 너무 많거나 적을 수 있다.
하지만 Silhouette score가 절대적으로 가장 높은 것을 선택해야 되는 것은 아니다. 필요에 따라서 비교적 약간 낮은 값을 갖고 있지만 분석가의 판단에 따라서 k를 적절하게 선택할 수도 있다. 2개의 cluster가 가장 점수가 높다고 하더라도 4개로 분류하는 것이 좀더 풍부한 의미를 도출하는 것에 적합하다면 4개를 선택할 수도 있다. 이 지표는 참고적인 용도로 사용된다.
