딥러닝에서 최적화(Optimization)란 학습 모델의 손실함수(loss function)의 최소값을 찾아가는 과정을 말한다.
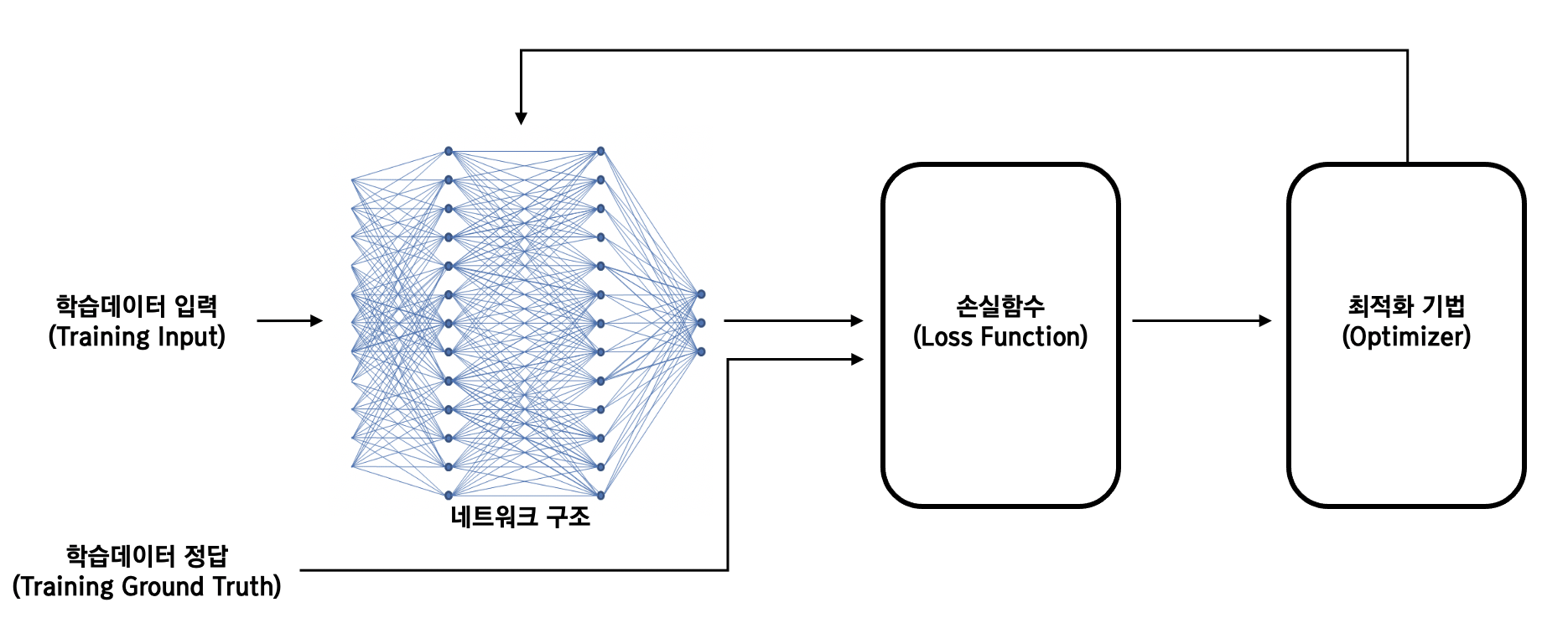
손실함수란?
딥러닝에서는 학습 데이터를 입력하면 hidden layer를 거쳐 예측값을 얻게된다. 이 예측값과 실제 정답과의 차이를 비교하는 함수가 손실 함수이다.
아래 이미지는 다양한 optimizer들이 최적의 loss를 찾아가는 과정을 시각화한 것이다.
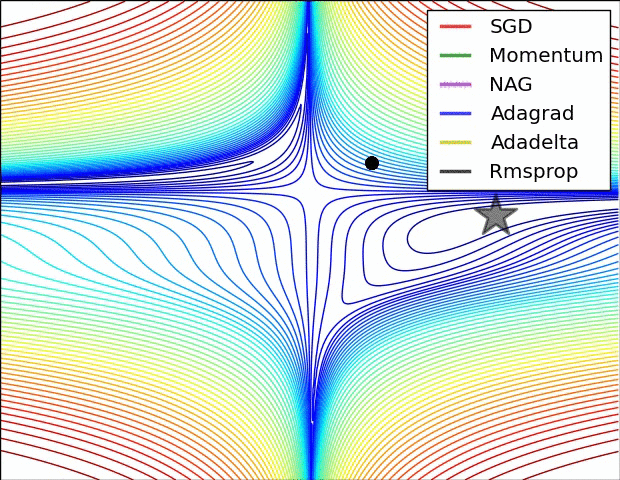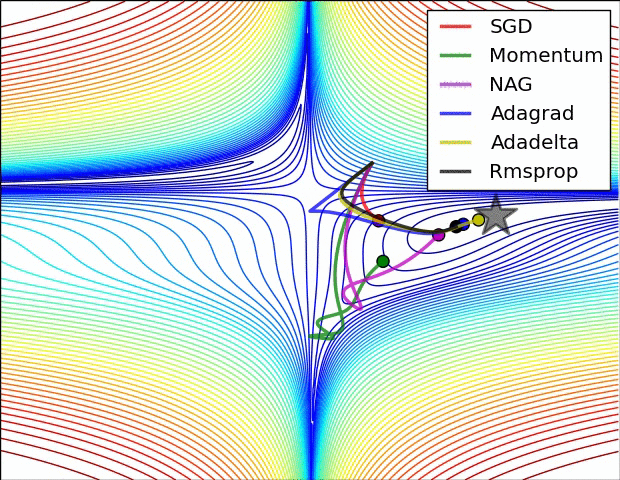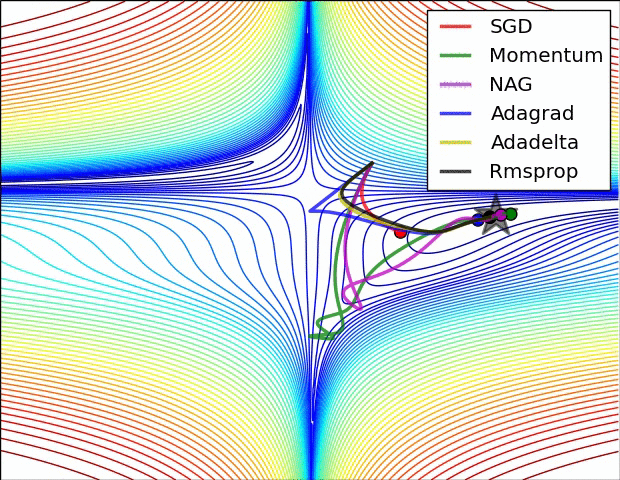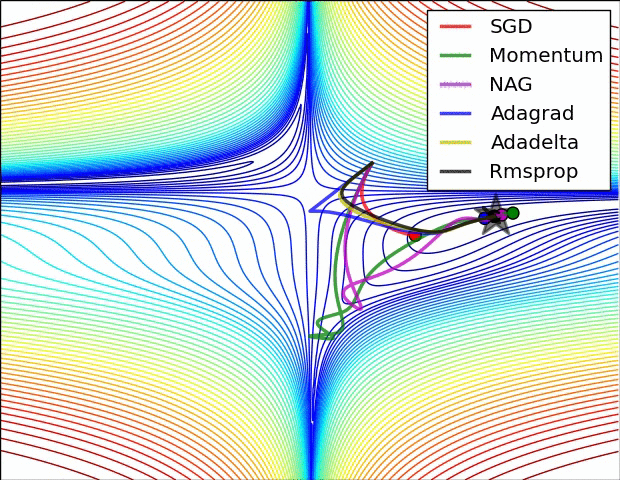
Gradient Desecent
경사하강법(Gradient Descent)은 머신러닝 모델의 Optimizer의 한 종류로 가장 기본적인 Optimizer이다.
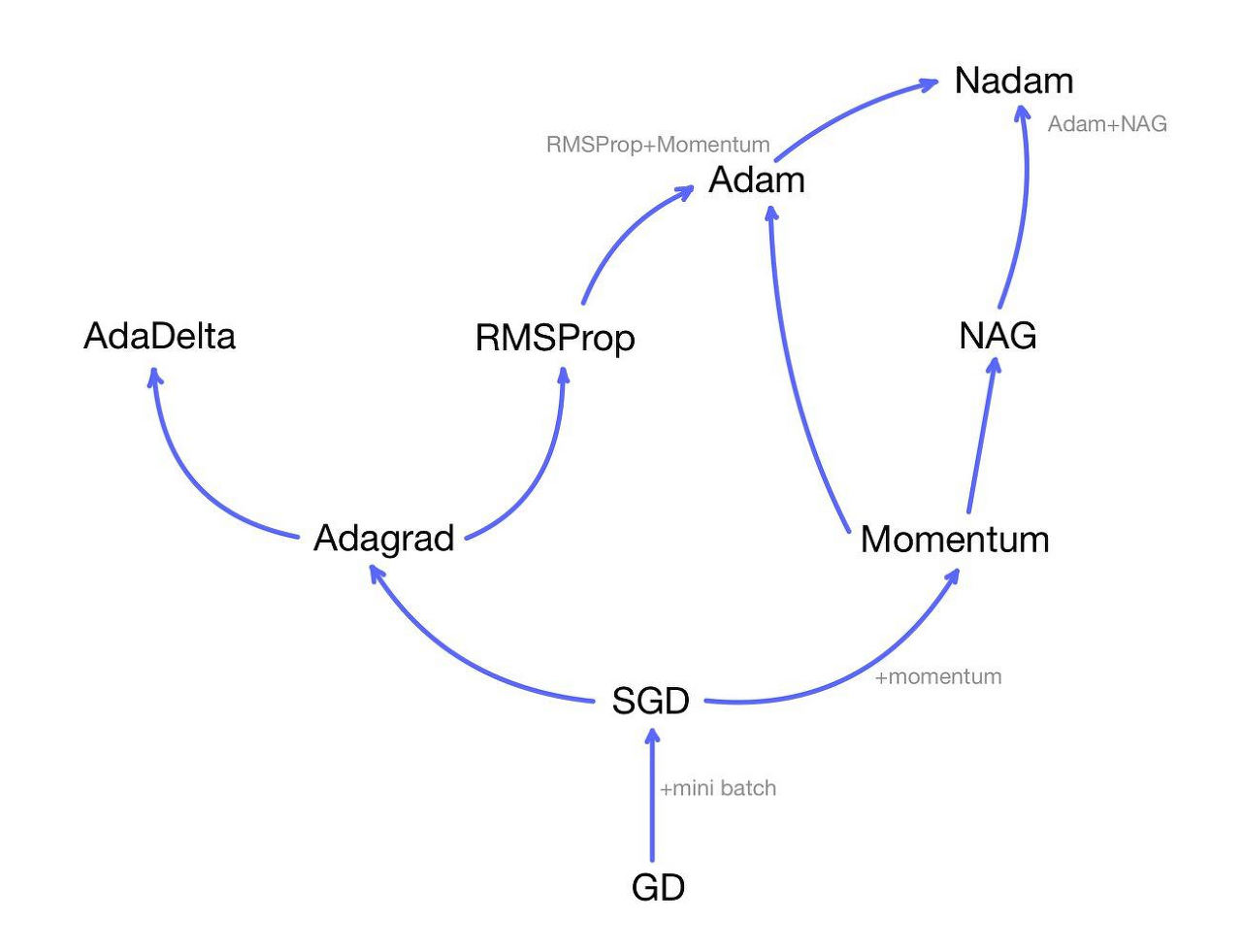
Gradient Descent 외에도 다양한 Optimizer들이 존재하지만 위 그림에서 알 수 있듯이 다른 옵티마이저들도 Gradient Descent에서 새로운 개념을 추가하거나 단점을 보완해나가면서 만들어진 것이다.
경사하강법은 이름에서 유추할 수 있듯이 기울기(Gradient)를 이용하여 손실 함수의 값을 최소화하는 방법이다. Gradient를 이용해 함수가 최소값을 가질때의 x값을 찾는다.
아래와 같은 함수가 있다고 하자.
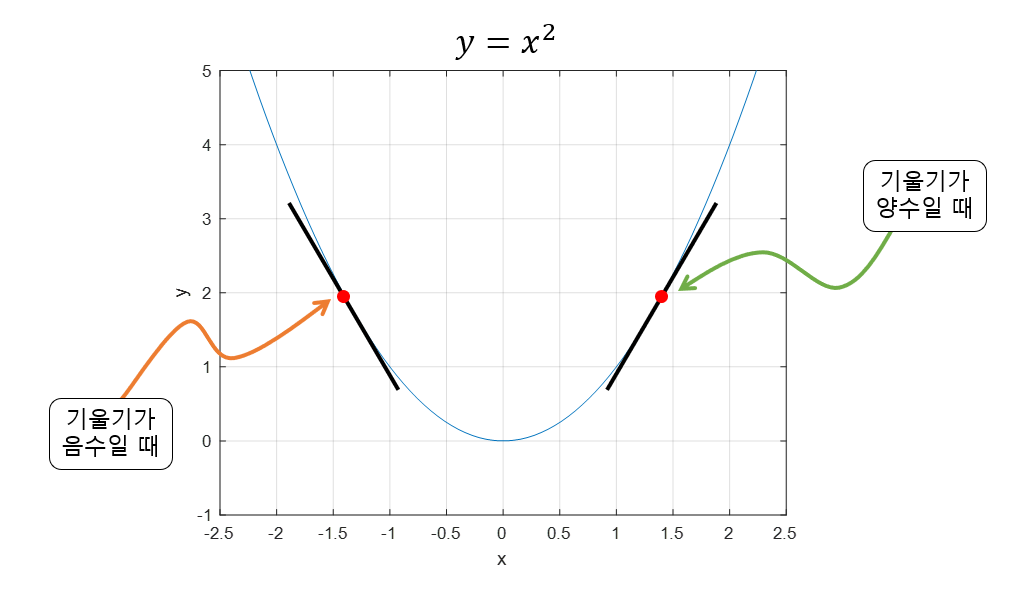
이 함수에서 기울기가 양수인 경우에는 값이 증가할수록 함수값도 증가하고, 반대로 음수인 경우에는 값이 증가할수록 함수값이 감소한다.
그리고 기울기 값이 크다는 것은 최소값으로부터 거리가 멀다는 뜻이다.
이러한 성질을 이용해서 기울기가 양수라면 음의 방향으로 를 옮기면 되고, 기울기가 음수라면 양의 방향으로 를 옮기는 것이 Gradient Desecent의 개념이다.
Gradient Desecent를 공식으로 표현하면 다음과 같다.
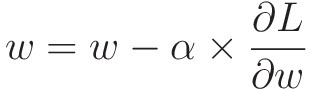
: weight (위 설명에서 x와 같은 역할)
: learning rate
기울기가 크다는 것은 현재 x의 위치가 손실 함수의 극솟값을 갖는 w의 값으로부터 멀리 떨어져 있다는 것을 의미합니다. 즉 x가 이동해야 할 거리와 x에서의 미분계수의 절댓값이 비례하기 때문에 위의 식을 이용하면 x가 멀 때는 빠르게, x가 가까울 때는 천천히 수렴하도록 설정할 수 있다.
Learning Rate
그렇다면 위의 식에서 는 무엇일까?
는 Learning Rate라는 파라미터로 x값이 움직이는 거리를 조절해주기 위해 사용한다.
아래 그림을 통해 쉽게 이해할 수 있다.
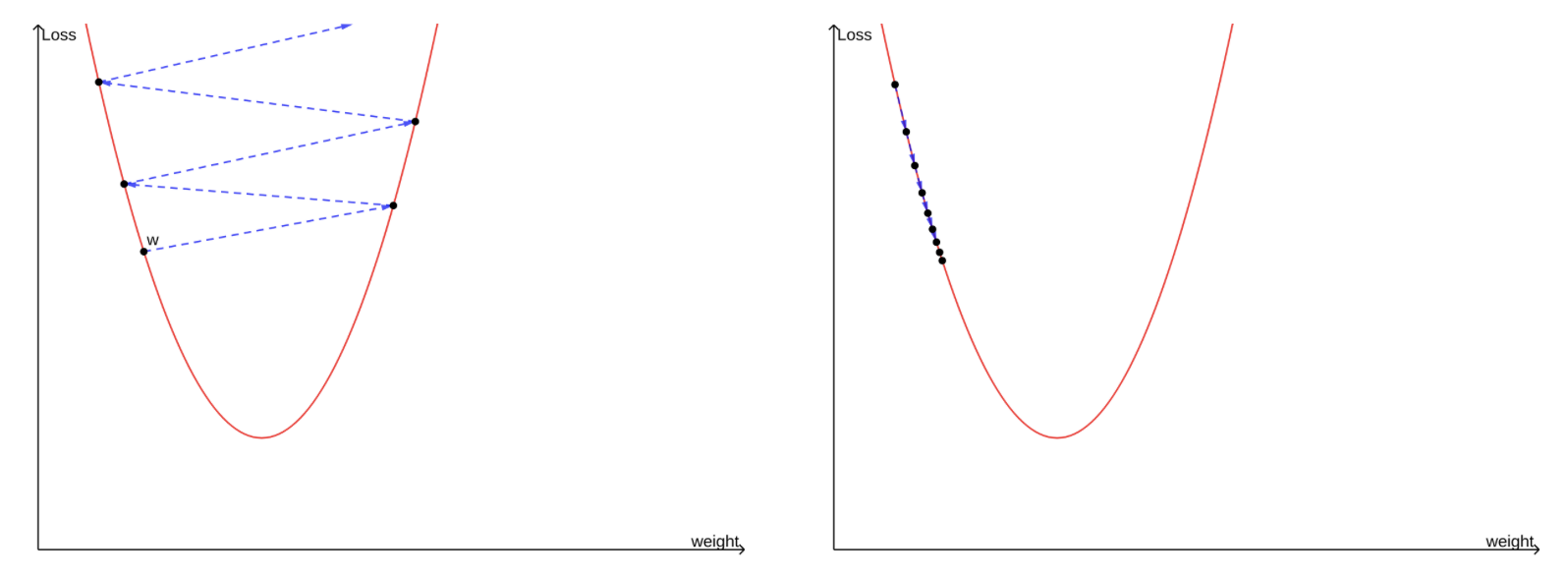
좌측의 그래프에서는 Learning rate가 큰 경우를 표현하고 있고 우측의 그래프에서는 Learning rate가 작은 경우를 표현하고 있다.
만약 x가 이동하는 거리가 너무 크다면(Learning rate가 크다면) loss 값이 커지는 방향으로 x가 조정될 가능성이 있고, 반대로 x가 이동하는 거리가 너무 작다면(Learning rate가 작다면) x가 적합한 값으로 수렴하는데에 너무 오랜 시간이 걸린다.
따라서 적절한 Learning rate를 설정하는 것 역시 중요한 요소중 하나이다.
Gradient Descent를 사용하는 이유
보통 함수의 최솟값을 찾고자 할 때, 사람은 미분계수를 구해 찾는다.
하지만 컴퓨터에서는 미분 계수를 사용하지 않고 Gradient Descent를 사용하는데 이유는 다음과 같다.
- 실제 분석에서(특히, 딥러닝 알고리즘을 활용하는 경우) 보게 되는 함수들은 형태가 굉장히 복잡해서 미분계수와 그 근을 계산하기 어려운 경우가 많다.
- 미분계수 계산 과정을 컴퓨터로 구현하는 것보다 경사하강법을 구현하는 것이 훨씬 쉽다.
- 데이터의 양이 매우 큰 경우, 경사하강법과 같은 순차적인 방법이 계산량 측면에서 훨씬 효율적이다.
Gradient Descent의 문제점
1. Local minima
경사하강법의 또 다른 문제는 local minima이다. 우리가 찾고 싶은 건 global minima(함수 전체에서의 최소값)이지만, 어떤 경우에는 local minima에 빠져 벗어나지 못 하는 상황이 발생한다.
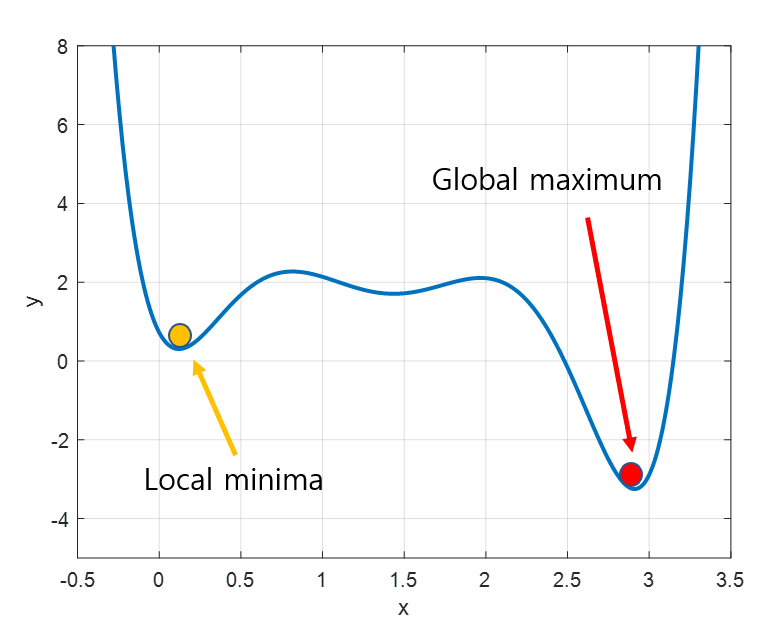
하지만 최근에는 실제로 딥러닝 모델이 학습을 할 때, local minima에 빠질 확률이 거의 없다고 한다.
위의 그래프는 가중치(w)가 1개인 모델이지만 실제 딥러닝 모델에서는 w가 수도 없이 많고, 그 수 많은 w가 모두 local minima에 빠져야 w 업데이트가 정지된다. 이는 이론적으로 거의 불가능에 가까운 일이므로, 사실상 local minima는 고려할 필요가 없다.
2. Saddle Point
Local Minima와 비슷하지만 다른 문제이다.
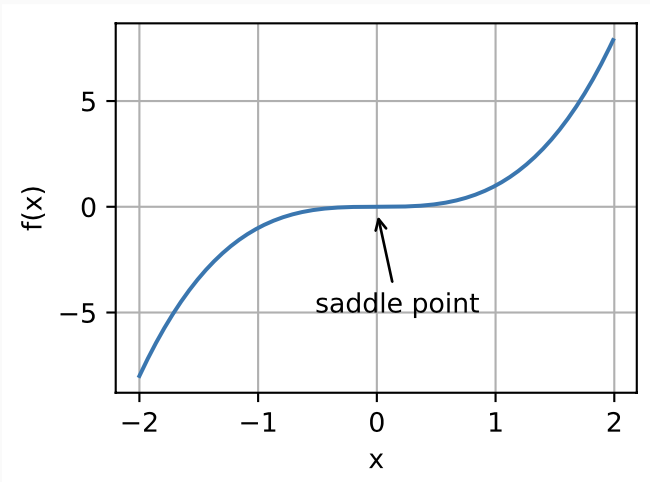
어떠한 평평한 점에 초기값이 놓이게 될경우 어느쪽으로도 이동하지 못하는(경사가 존재하지 않기 때문에) 상황이 발생한다.
이를 말안장 같다고 하여서 Saddle Point라고 부른다.
3. 학습시간
경사하강법은 한번 학습할 때마다 모든 데이터셋을 이용한다.
즉, 손실함수의 최솟값을 찾아 나가기 위해 한 칸 전진할 때마다 모든 데이터를 다 훑는다는 것이다. 따라서 학습이 굉장히 오래 걸린다. (최솟값을 찾는데 오래 걸린다)
이러한 문제를 해결하기 위해 모든 데이터를 사용하지 않고 데이터를 Mini-batch로 잘라서 학습시키는 확률적 경사하강법이 등장하게 되었다.
Stochastic Gradient Descent
확률적 경사하강법(Stochastic Gradient Descent)은 추출된 데이터 한 개에 대해서 gradient를 계산하고, 경사하강법을 적용하는 방법을 말한다.
전체 데이터를 사용하는 것이 아니라, 랜덤하게 추출한 일부 데이터를 사용하기 때문에 학습 중간 과정에서 결과의 진폭이 크고 불안정하며, 속도가 매우 빠르다. 또한, 데이터 하나씩 처리하기 때문에 오차율이 크고 GPU의 성능을 모두 활용하지 못하는 단점을 가진다.
이러한 단점들을 보완하기 위해 나온 방법들이 Mini batch를 이용한 방법이며 확률적 경사 하강법의 노이즈를 줄이면서도 전체 배치보다 더 효율적이다.
