Resampling Methods는 모델 평가(model assessment), 모델 선택(model selection)을 위해 training data의 서로 다른 부분 집합을 사용하여 동일한 통계 모델을 여러번 fitting 하는 것을 의미한다.
Validation Set Approach
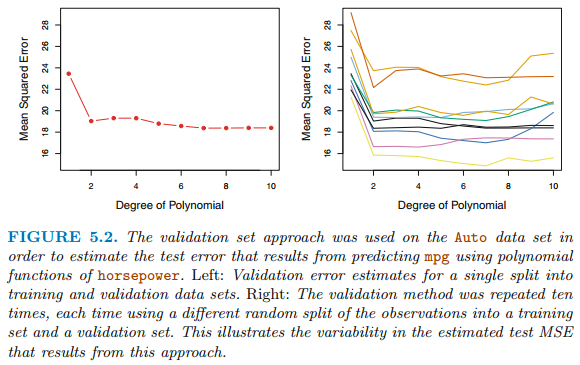
- 전체 데이터 셋을 동일한 크기를 가진 2개의 집합으로 분할하여 training set, validation set을 만든다.
- 영향력이 큰 관측지가 어느 set에 속하느냐에 따라 MSE가 달라진다.
- 관측치의 일부만 train에 속하여 높은 bias를 갖는다.

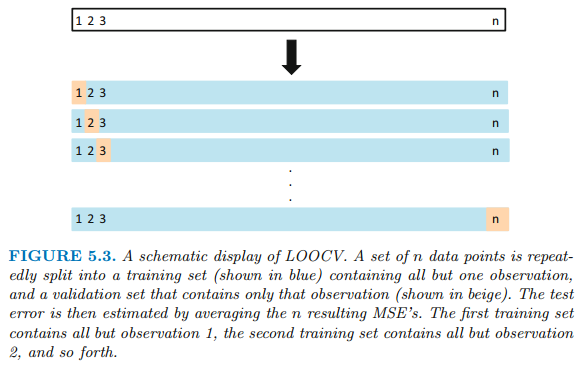
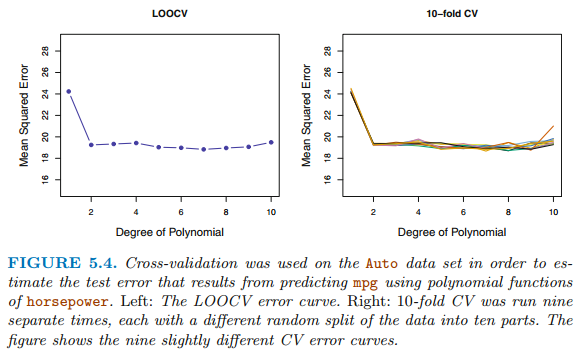
LOOCV(Leave-One-Out Cross-Validation)
- 단 하나의 관측값(x1, y1)만을 validation set으로 사용하고, 나머지 n-1개 관측값은 train set으로 사용한다.
- n번 fitting을 진행하고, n개의 MSE를 평균하여 최종 MSE를 계산한다.
- n-1개 관측값을 train에 사용하므로 bias가 낮다.
- overfitting 되어 높은 variance를 갖는다.
- n번 나누고 n번 fit 하므로 랜덤성이 없다.
- n번 fit을 진행하므로 expensive 하다.
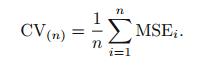
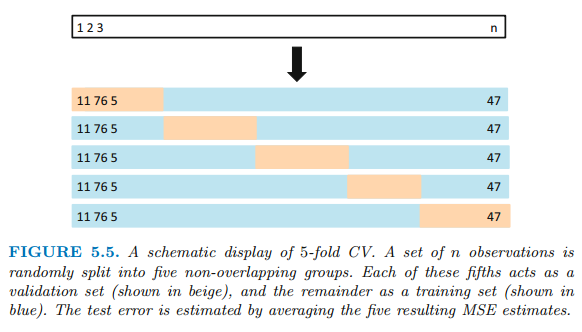
K-Fold Cross-Validation
- 전체 데이터 셋을 k개의 그룹으로 분할하여 한 그룹은 validation set, 나머지 그룹은 train set으로 사용한다.
- k번 fit을 진행하여 k개의 MSE를 평균내어 최종 MSE를 계산한다.
- LOOCV보다 연산량이 낮다.
- 중간 정도의 bias와 variance를 갖는다.
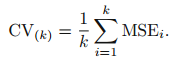

강승구