7장 릴레이션 정규화
부주의한 데이터베이스 설계 ➡ 제어할 수 없는 데이터 중복 야기 + 갱신 이상 유발
7.1 정규화
릴레이션 스키마를 함수적 종속성과 기본 키를 기반으로 분석해 원래의 릴레이션을 분해해 중복과 세 가지 갱신 이상을 최소화한다.
좋은 DB 스키마 설계 목적
- 정보의 중복과 갱신 이상 방지
- 정보의 손실 방지
- 실세계 표현
- 애트리뷰트들 간의 관계 잘 표현
- 무결성 제약조건 시행 간단하게
- 갱신 이상 발생하지 않도록 노력이 우선, 그 후 효율성 고려
갱신 이상
-
수정 이상
- 반복된 데이터 중 일부만 수정시 데이터의 불일치 발생
-
삽입 이상
- 불필요한 정보를 함께 저장하지 않고 원하는 정보 저장 불가능
-
삭제 이상
- 유용한 정보 함께 삭제하지 않고는 어떤 정보 삭제 불가능
결국 일부만 하는 것으로는 갱신 이상 피할 수 없다.
나쁜 설계 예시들
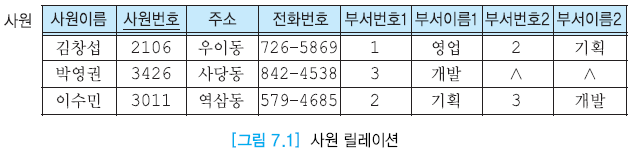
- NULL값 존재
- 부서 수 제한이 필요 없다.
- 첫번째 레코드 삭제 시 1번 영업부의 정보가 삭제 된다
- 삭제 이상
- 부서 이름 변경시 일부 사원의 투플만 부서이름 변경하는 경우 데이터 불일치가 발생한다.
- 수정 이상 : 데이터 불일치 발생
- 4번 홍보부 추가 시 나머지 애트리뷰트가 전부 NULL을 가지게 된다.(사원이 없기 때문)
- 사원번호가 NULL이기에 무결성 제약조건으로 인해 삽입불가
- 삽입 이상
- 정보의 중복 발생
- 사원번호, 사원이름, 주소, 전화번호 등의 애트리뷰트들이 중복되어 저장공간이 낭비된다.
갱신이상
아래의 세 이상들을 총칭하여 갱신이상이라고 부른다.
- 수정 이상
- 삽입 이상
- 삭제 이상
릴레이션 분해
📄 하나의 릴레이션 두 개 이상의 릴레이션으로 나누어 갱신이상 해결!!
- 분해하여도 원래의 릴레이션을 다시 구할 수 있음을 보장해야 한다.
- 분해 실패시 얻을 수 있는 정보가 원래 릴레이션 정보보다 적거나 많음
- 함수적 종석성에 관한 지식을 기반으로 분해한다.
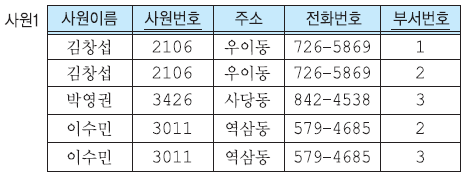
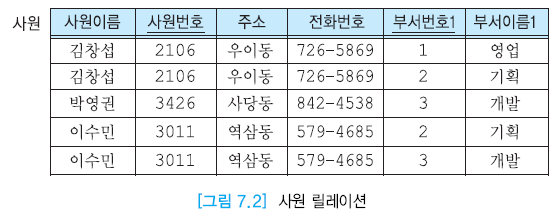
나쁜 예시를 이렇게 2개(사원1, 부서)의 릴레이션으로 분해하여 발생하는 갱신이상을 해결할 수 있다.
- 수정 이상
- 사원1 릴레이션에 부서 이름이 포함되지 않기에 수정 이상이 발생하지 않는다.
- 삽입 이상
- 사원 배정이 없어도 부서 릴레이션에만 추가하여 해결!
- 삭제 이상
- 유일한 사원의 투플을 삭제하여도 부서 릴레이션에 부서정보 남아있기에 해결!
정규형의 종류
- 제 1정규형
- 제 2정규형
- 제 3정규형
- BCNF
- 제 4정규형
- 제 5정규형
관계 데이터베이스 설계의 비공식적인 지침
- 이해하기 쉽고 명확한 스키마 생성
- 여러 곳에 속한 애트리뷰트들을 하나의 릴레이션에 포함시키지 않는다.
- NULL값 피하기
- 가짜 투플 생성 방지
- 스키마 정제
7.2 함수적 종속성
- 릴레이션의 애트리뷰트들의 의미로부터 결정된다.
- 스키마에 대한 주장 (NOT 인스턴스)
- 가능한 모든 인스턴스들이 만족
- 제 2정규형부터 BCNF 적용
결정자
- 어떤 애트리뷰트의 값은 다른 애트리뷰트의 값 고유하게 결정 가능
- 사원번호는 사원이름을 고유하게 결정
- 주소는 사원이름 결정 X
다른 애트리뷰트를 고유하게 결정하는 하나 이상의 애트리뷰트
A->B
A가 B를 결정한다.
- 사원번호 -> 사원이름
- 사원번호 -> 주소
- 사원번호 -> 전화번호
- 부서번호 -> 부서이름
함수적 종속성
- A->B이면 B가 A에 함수적으로 종속한다,
- 각 A 값에 대해 반드시 한 개의 B값이 대응된다.
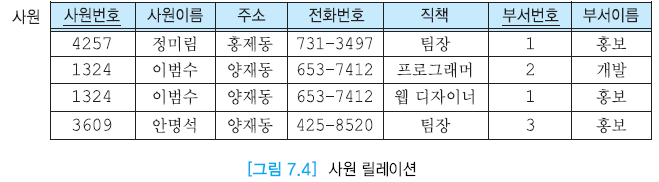
🔎 사원번호 -> 사원이름, 주소, 전화번호이므로 사원이름, 주소, 전화번호는 사원번호에 함수적으로 종속
🔎 (사원번호, 부서번호) -> 직책이지 사원번호에 함수적으로 종속하지 않음.
💡 직책은 사원번호 + 부서번호 집합에 고유하게 결정되지 사원번호에 의해 결정되지 않는다.
완전 함수적 종속성 (FFD)
릴레이션 R에서 애트리뷰트 B가 애트리뷰트 A[복합 애트리뷰트]에 함수적으로 종속(A->B)이면서 A의 어떠한 진부분 집합에도 함수적 종속이 안될 시.
A 그대로에 함수적 종속 (부분에 종속 x)
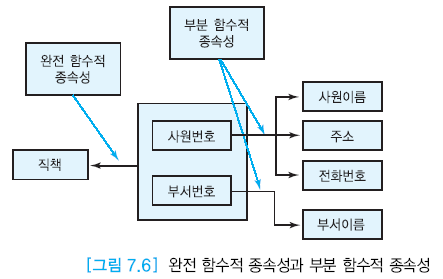
- (사원번호, 부서번호) -> 직책
- 사원번호 -> 직책 : 불가 => 완전 함수적 종속성
- 부분 함수적 종석성
- (사원번호, 부서번호) -> 부서이름 가능!
- 부서 번호 -> 부서 이름 : 부분 함수적 종속성 ⭕
- 사원 번호 -> 부서 이름 : 부분 함수적 종속성 ❌
이행적 함수적 종속성 (transitive FD)
A, B, C 애트리뷰트가 있을 때 애트리뷰트 C가 이행적으로 A에 종속한다는 것
A→B ∧ B→C (동시성립)
A→B ∧ A→C
- A가 릴레이션의 기본 키 라면 키의 정의에 따라 성립
- C가 B에도 함수적으로 종속(B→C)한다면 C는 A에 직접 함수적으로 종속하면서 B를 거쳐서 A에 이행적으로 종속한다.
- A→B ∧ B→C 성립함을 의미
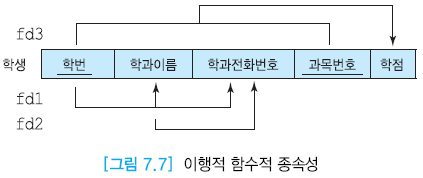
- 학번 → 학과이름 ∧ 학과이름 -> 전화번호
- 학번 → 전화번호 : 이행적으로 종속.
7.3 릴레이션 분해
하나의 릴레이션을 두 개 이상으로 나누는 것
- 함수적 중복성 이용
- 분해 시 중복이 감소되고 갱신 이상이 줄어든다.
- 잠재적인 문제 발생 가능
- 조인이 필요 없는 질의가 분해 후에는 조인을 필요로 하기도 한다.
- 원래 릴레이션으로 재구성하지 못할 수도 있다.
무손실 분해
분해된 릴레이션 조인 시 완전하게 얻을 수 있다.
- 손실 : 정보의 손실
- 조인 시 원래 정보보다 적거나 많은 것을 정보의 손실이라고 한다.
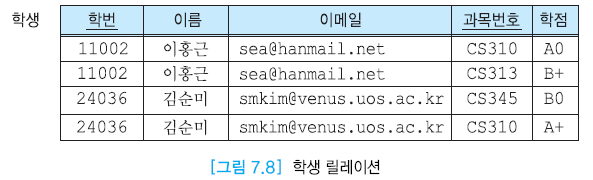
- 학번 → 이름, 이메일
- 이메일 → 학번, 이름
- (학번, 과목번호) → 학점
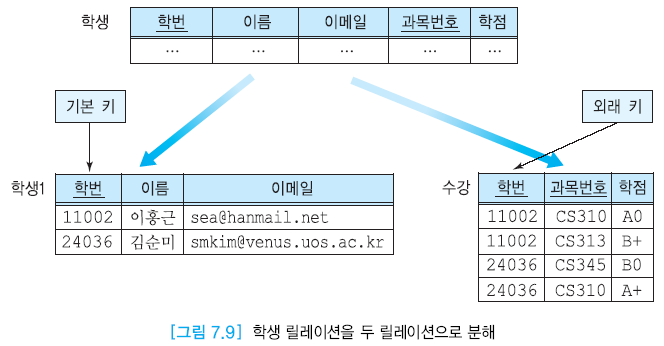
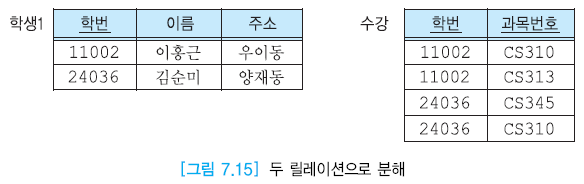
여기서 학생1 릴레이션 분해
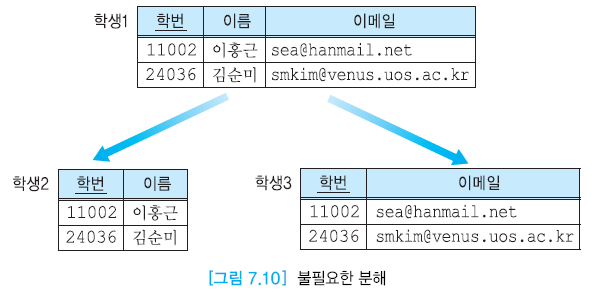
-
학번이 중복된다.
- 손실 분해
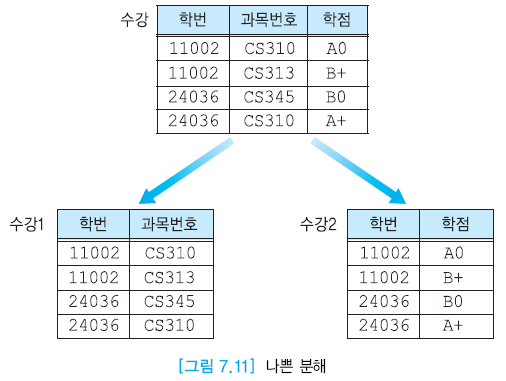
-
학번이 중복된다.
- 손실 분해
-
과목번호, 학점간의 연관성이 표현되지 않는다.
- 나쁜 분해
위의 예시는 원래 릴레이션에 존재하지 않는 투플들이므로 가짜 투플 (손실 분해) 이다.
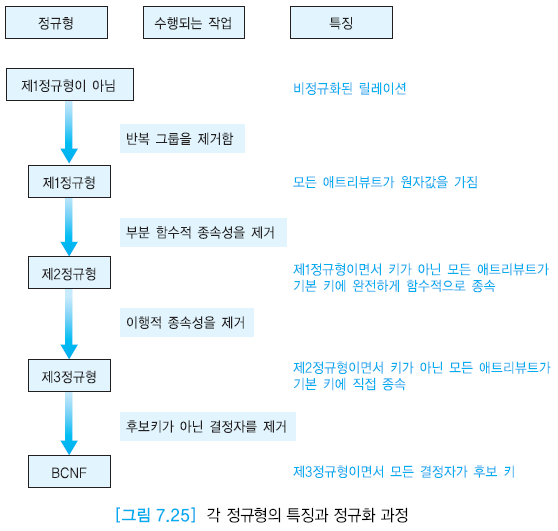
7.4 정규형
제 1 정규형
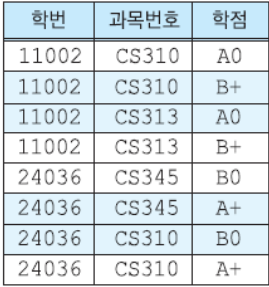
- 릴레이션 R의 모든 애트리뷰트가 원자값만을 갖는다.
관계 데이터베이스의 요구사항
- 반복 그룹이 나타나지 않으면 제 1 정규형이 만족한다.
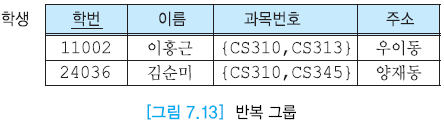
위의 그림은 반복 그룹이 애트리뷰트에 존재하므로 제 1 정규형을 만족하지 않는다.
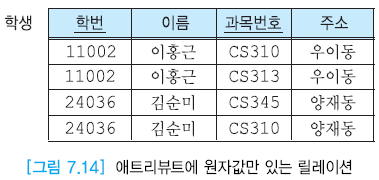
위의 그림은 반복 그룹을 제거시켰지만 데이터가 중복되어 있기에 이를 없애기 위해 분해시켜줘야 한다.
갱신 이상
제 1정규형에도 갱신이상이 존재한다.
아래의 그림은 제1정규형을 만족하는 릴레이션이다.
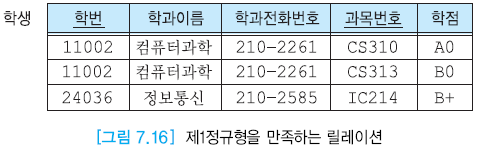
- 삽입 이상
- 인공지능학과가 생겼을 때 이를 삽입할 수 없다.
- 기본키인 학번이 NULL이기에 학생 릴레이션에 추가할 수 없다.
- 인공지능학과가 생겼을 때 이를 삽입할 수 없다.
- 수정 이상
- 같은 학번 전호번호 변경 어려움
- CS310 듣는 11002 투플의 전화번호를 수정하면 CS313을 듣는 투플의 전화번호에서 데이터 불일치가 발생한다.
- 같은 학번 전호번호 변경 어려움
- 삭제 이상
- 마지막 24036학번 투플 삭제하면 24036 학생이 없어지는 것으로 삭제가 어렵다.
갱신 이상 발생 이유
부분 함수적 종속성이 학생 릴레이션에 존재하기때문이다.
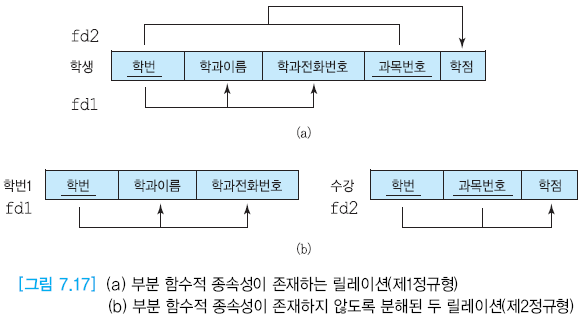
- A 에서 FD1이 존재하기에 어렵다.
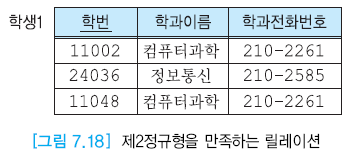
제 2 정규형
-
제 1정규형을 만족하면서, 어떤 후보 키에도 속하지 않는 모든 애트리뷰트들이 릴레이션의 기본 키에 완전하게 함수적으로 종속해야한다.
-
기본 키가 두 개 이상의 애트리뷰트로 구성되었을 때 고려
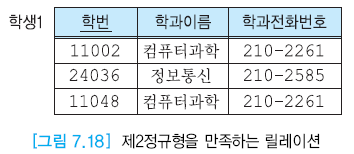
갱신 이상
- 삽입 이상
- 학과 신설할 시 소속 학생이 없기에 학과 정보를 기입할 수 없다.
- 엔티티 무결성 제약조건
- 학과 신설할 시 소속 학생이 없기에 학과 정보를 기입할 수 없다.
- 수정 이상
- 소속 학과의 전화번호 변경시 모든 학과 투플 전화번호 수정하지 않으면 데이터 불일치 발생
- 삭제 이상
- 학과에 남은 단 하나의 학생 투플 삭제 시 학과의 전화번호 삭제
발생 이유
-
릴레이션에 이행적 종속성이 존재
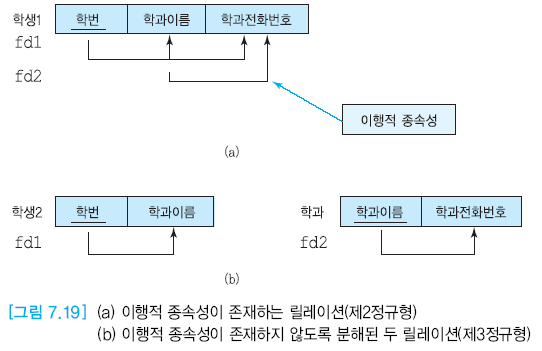
-
학과 이름이 KEY 애트리뷰트가 아님에도 다른 애트리뷰트를 결정한다.
-
학번 - 전화번호 : 직접 연관이 없음에도 이행적 종속성이 있기에 문제 발생
제 3 정규형
- 제 2정규형 만족하면서 키가 아닌 모든 애트리뷰트가 릴레이션의 기본키에 이행적으로 종속하지 않는 것
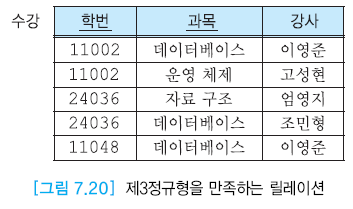
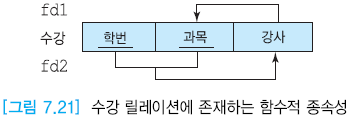
갱신 이상
- 수정 이상
- 강사 변경 시 모든 투플에서 수정하지 않으면 데이터 불일치 발생
- 삽입 이상
- 과목 신설 시 학생이 없으면 투플 추가 불가
- 학번이 기본키를 구성하는 것인데 엔티티 무결성 제약조건에 의해 NULL값을 추가할 수 없기 때문이다.
- 과목 신설 시 학생이 없으면 투플 추가 불가
- 삭제 이상
- 이수하는 인원 한 명뿐인데 이 투플 삭제 시 과목을 가르치는 강사에 대한 정보도 사라진다.
발생 이유
키가 아닌 애트리뷰트가 다른 애트리뷰트를 결정하기 때문이다.
-
FD1
-
7.21의 후보 키 (학번, 과목) , (학번, 강사)
- (학번, 강사) 과목 결정해서 애트리뷰트 구성
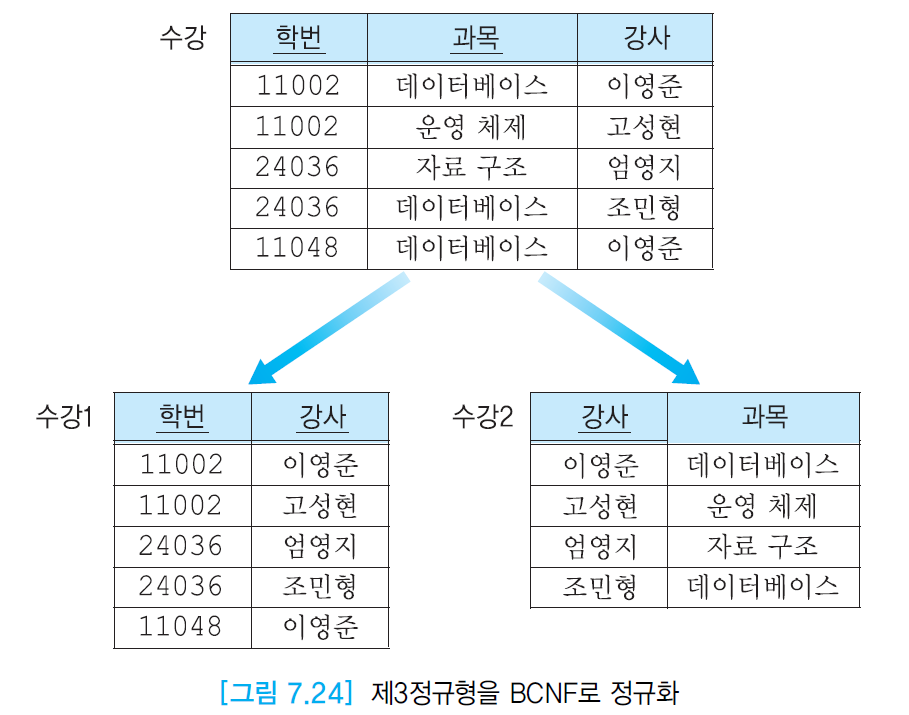
BCNF
- 제 3정규형을 만족하고, 모든 결정자가 후보 키가 되어야한다.
- 그림 7.21은 강사 애트리뷰트가 후보 키가 아님에도 과목 애트리뷰트를 결정하기에 BCNF가 되지 않는다.
- 하나의 후보키를 가진 릴레이션이 제 3정규형 만족 시 BCNF 만족
만드는 방법
- 키가 아니면서 결정자 역할을 하는 애트리뷰트와 그 결정자에 함수적으로 종속하는 애트리뷰트를 하나의 테이블에 넣는다.
- 이 릴레이션에서 결정자는 기본 키
- 기존 릴레이션에 결정자를 남겨서 기본 키의 구성요소가 되게 한다.
- 이 결정자는 새로운 릴레이션에 대한 외래키
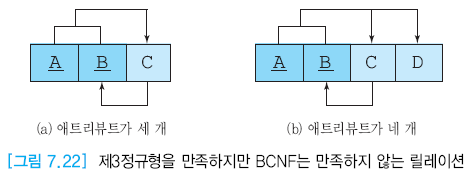
-
C가 후보 키가 아님에도 B 애트리뷰트를 결정한다.
- C -> B : C 결정자 역할 + B는 C에 함수적으로 종속
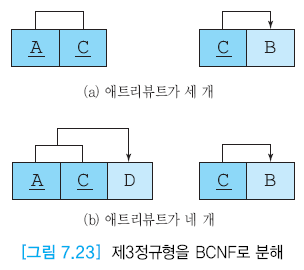
- C -> B : C 결정자 역할 + B는 C에 함수적으로 종속
-
C는 외래키의 역할을 하며 기본 키의 구성요소가 된다.
요약
- 주요 애트리뷰트 : 키에 속하는 애트리뷰트
- 비주요 애트리뷰트 : 키에 속하지 않는 애트리뷰트
7.5 역정규화
정규화
장점
- 중복 감소, 갱신 이상 감소
- 무결성 제약조건을 시행하기 위한 필요코드 감소
단점
- 성능상의 관점에서는 높은 정규형을 만족하는 릴레이션 스키마가 무조건 최적은 아니다.
- 분해 시 두개의 릴레이션
- 많은 릴레이션 접근하므로 조인의 필요성이 증가한다.
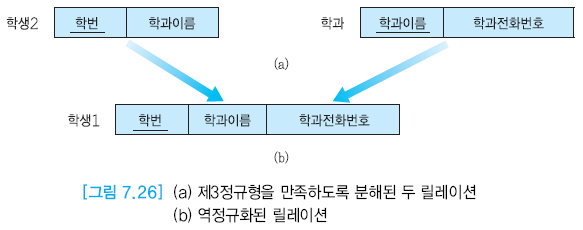
정규화 ⬇
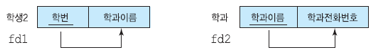
SELECT 학과이름, 학과전화번호 FROM 학생1 WHERE 학번 = '11002';에서 정규화 시
SELECT 학과이름, 학과전화번호 FROM 학생2, 학과 학번 = '11002' AND 학생2.학과이름 = 학과.학과이름;
역정규화
보다 낮은 정규형으로 되돌아 가는 것
-
일부분을 역정규화함으로써 데이터 중복 및 갱신 이상을 대가로 치르면서 성능상의 요구를 만족시키기도 한다.
-
검색 질의의 비율보다 갱신 질의의 비율이 높기에 분해된 릴레이션 합치기도 한다.