9장 트랜잭션
9.1 트랜잭션
- 하나의 논리적 단위를 수행하는 데이터베이스 연산들의 모인
- 객체들을 접근하고 갱신하는 프로그램 수행 단위
특성
ACID
- 원자성 (Atomicity)
- 1 또는 0. 모든 연산들이 완전히 수행되거나 전혀 수행되지 않음을 의미한다.
- 시스템이 다운되는 경우 DBMS의 회복모듈이 트랜잭션의 영향을 취소함으로써 트랜잭션의 원자성을 보장한다.
-
일관성 (Consistency)
-
수행되기전에 데이터베이스가 일관된 상태였다면 수정 후에도 일관된 상태를 유지한다.
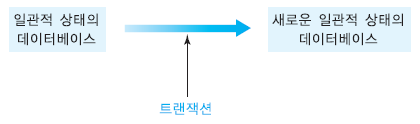
-
트랜잭션 수행 중에는 일시적으로 일관되지 않을 수도 있다.
-
-
고립성 (Isolation)
- 트랜잭션 완료전까지는 갱신 중인 데이터를 다른 트랜잭션들이 접근하지 못하도록 한다.
- 다수의 트랜잭션이 동시 수행되더라도 결과는 트랜잭션들이 차례대로 수행한 결과와 같아야함.
- DBMS의 동시성 제어 모듈이 고립성 보장
- 다양한 고립 수준 제공
-
지속성 (Durability)
- 한 트랜잭션 완료(commit) 시 그 이후에는 손실되지 않는다.
- DBMS의 회복 모듈이 지속성 보장
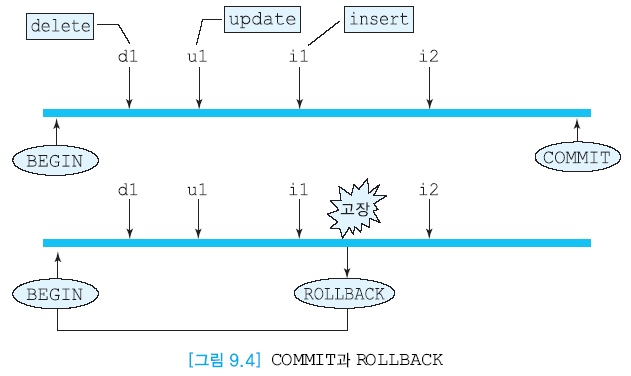
트랜잭션 완료
- 변경 내용 데이터베이스에 완전하게 반영
- COMMIT WORK
트랜잭션 철회
-
일부만 반영된 경우네는 원자성 보호를 위해서 수행전의 상태로 되돌린다.
-
ROLLBACK WORK
트랜잭션 실패 요인
- 시스템 고장
- 트랜잭션 고장
- 매체 고장
- 통신 고장
- 자연재해
- 부주의 OR 고의 고장
9.2 동시성 제어
- 다수 사용자들 동시에 동일 테이블 접근
- DBMS 성능 높이기 위해 필수적
- 트랜잭션들 간의 간섭 발생 방지해야한다.
스케줄
트랜잭션의 수행순서
-
직렬 스케줄
- 한 트랜잭션씩 차례대로 수행
T1 : 011, 012
T2 : 021, 022, 023
S1 : T1, T2 (011, 012, 021, 022, 023)
S2 : T2, T1 (021, 022, 023, 011, 012)
트랜잭션 내의 순서 변경 X
- 한 트랜잭션씩 차례대로 수행
-
비직렬 스케줄
- 여러 트랜잭션 동시 수행
S3 : 011, 021, 022, 012, 023
- 트랜잭션 내부 연산의 순서는 유지되어야 한다.
-
직렬가능
- 비직렬 스케줄의 결과가 직렬 스케줄의 수행 결과와 동등
- S3의 수행 결과가 S1의 결과와 동일시 직렬가능으로 올바른 비직렬 스케줄이다.
- 비직렬 스케줄의 결과가 직렬 스케줄의 수행 결과와 동등
데이터 베이스 연산
- Input(X)
- Output(X)
- read_item(X)
- write_item(X)
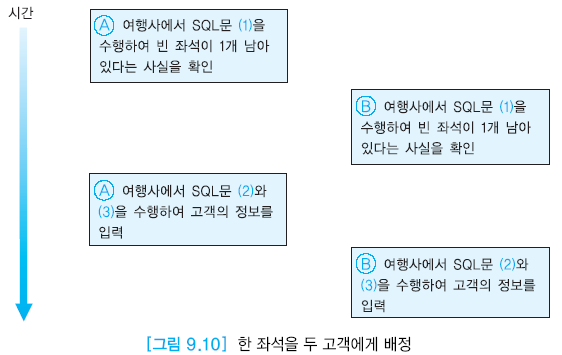
동시성 제어하지 않을 때 발생 가능한 문제
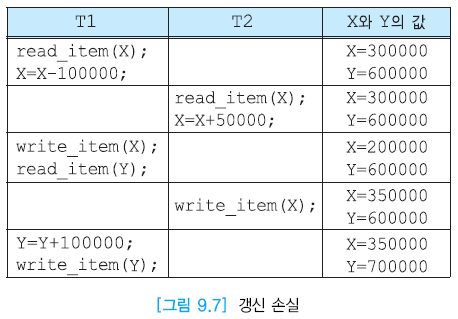
- 갱신손실 : 갱신한 내용을 다른 트랜잭션이 덮어 써 갱신이 무효가 되는 경우
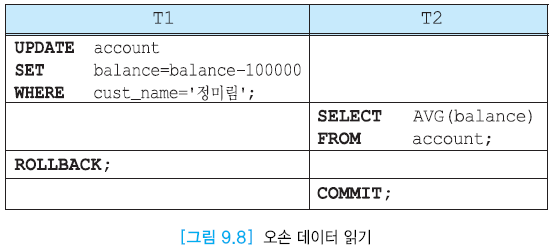
- 오손 데이터 읽기 : 완료되지 않은 트랜잭션이 갱신된 데이터를 읽는 것
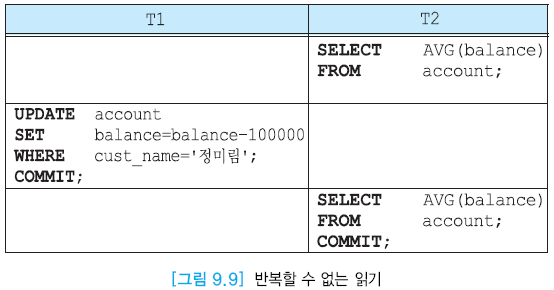
- 반복할 수 없는 읽기 : 동일한 데이터 두번 읽을 때 서로 다른 값을 읽는 경우
로킹
데이터 항목과 연관된 하나의 변수
-
동시성 제어위해 가장 널리 사용되는 기법
-
요청한 로크에 관한 정보는 로크 테이블 등에 유지된다.
-
접근할 때 로크 요청, 접근을 끝낸 후에 로크 해제
- 갱신 목적 접근 : 독점 로크
- 읽기 목적 접근 : 공유 로크
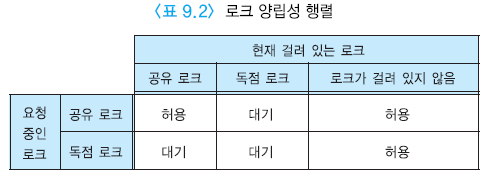
로크를 일찍 해제하는 경우

- A=B로 시작
- A 값
- 첫번째 unlock(A)에서 A+1이 된다.
- 두번째 unlock(A)에서 2A+2
- B 값
- 첫번째 unlock(B)에서 2B
- 두번째 unlock(B)에서 2B + 1
- A, B 는 같은 수행을 했음에도 불구하고 값ㄹ이 다르게 된다.
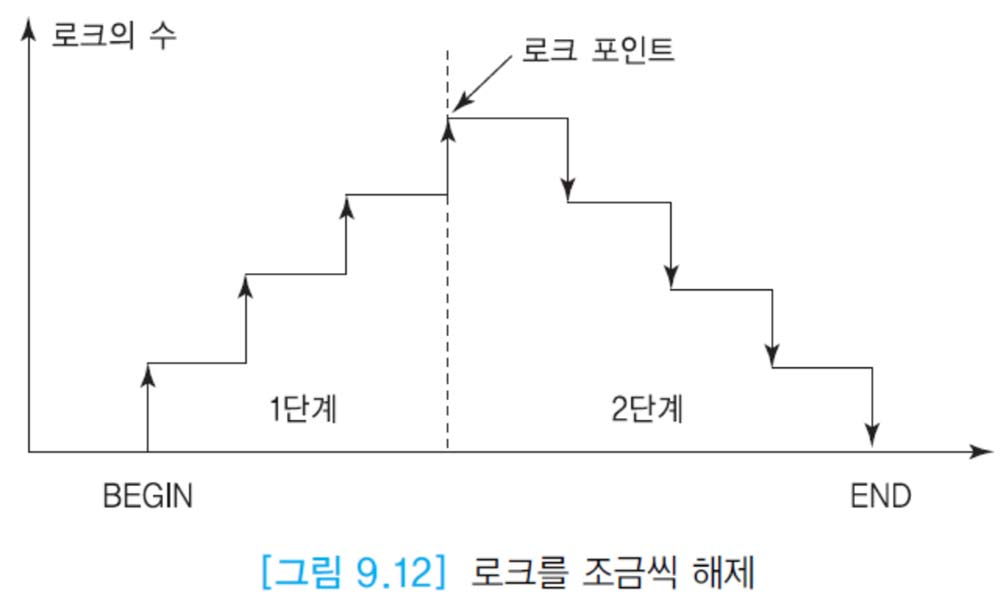
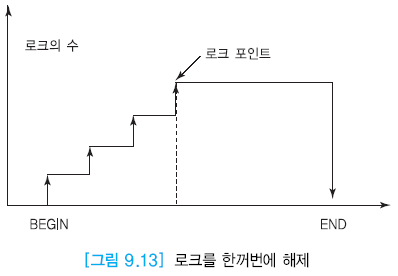
2단계 로킹 프로토콜
-
로크를 요청하는 단계 + 로크를 해제하는 단계로 총 2단계로 이루어짐
-
로크 확장 단계 후 로크 수축 단계
-
로크를 한 개라도 해제하면 로크 수축 단계가 된다.
로크 확장 단계(1단계)
- 트랜잭션이 데이터 항목에 대해 새로운 로크 요청가능
- 보유하고 있던 로크 해제 불가
로크 수축 단계(2단계)
- 보유하고 있던 로크 해제가능
- 새로운 로크 요청 불가
- 트랜잭션 완료 시점에 이르렀을 때 한꺼번에 모든 로크 해제 가능
로크 포인트
필요로 하는 모든 로크를 걸어놓은 시점
데드록
- 2단계 로킹 프로토콜에서 발생 가능
- 두 개 이상의 트랜잭션들이 상대방이 보유하고 있는 로크를 요청하며 기다리는 상태 (무한정 대기)
- 희생자 선정하여 데드록 풀기도 한다.
순서
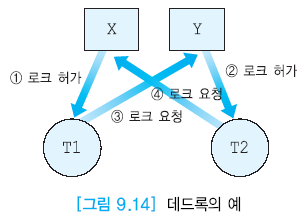
- T1이 X에 대해 독점 로크 요청
- T2가 Y에 대해 독점 로크 요청
- T1이 Y에 대해 독점 OR 공유 로크 요청 시 로크 해제까지 대기
- T2가 X에 대해 독점 OR 공유 로크 요청 시 로크 해제까지 대기
다중 로크 단위
투플 수에 따라 로크를 하는 데이터 항목의 단위 구분이 필요하다
로크할 수 있는 데이터 항목이 두가지 이상 있으면 다중 로크 단위라고 부른다.
-
데이터베이스, 릴레이션, 디스크 블록, 투플
-
로크 단위가 작을수록 로킹에 따른 오버헤드가 증가 + 동시성의 정도 증가
-
Intention Lock : 상위 level에 lock
- 하위단위에 대해서도 모두 lock => 오버헤드가 증가한다
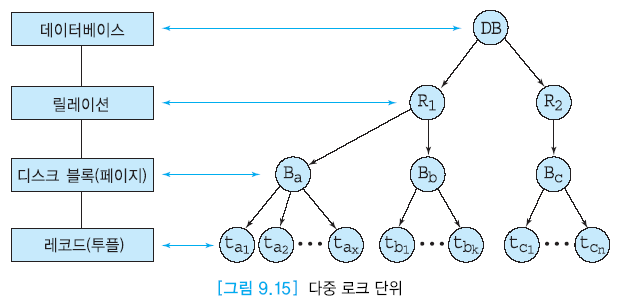
보충필요
팬텀 문제
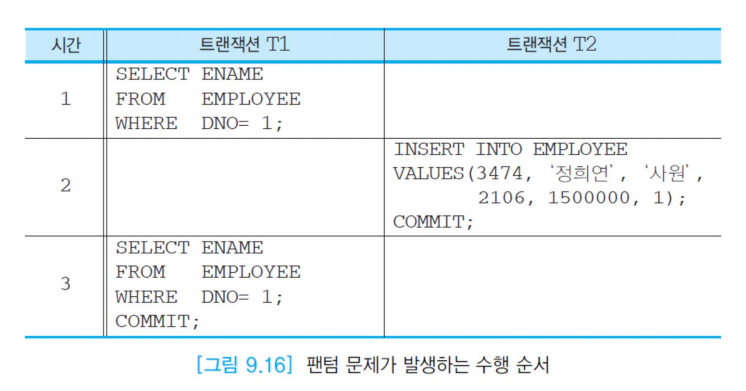
- 1시간에서 1번부서에 성이 김, 박 이있다고 가정
- 2시간에서 정씨가 추가 된다.
- 3시간에서 김, 박 , 정(phantom 등장) 한 채로 완료된다.
원래 트랜잭션 T1에서 시행하려던 결과는 김, 박 이 두번 나와야했지만
두번째 SELECT문에서 김, 박, 정이 나오게 되어 결과가 다르게 나타난다.
➡ 팬텀 문제
9.3 회복
- 시스템이 다운되었을 때, 트랜잭션의 수행이 일부만 반영
➡ 어떻게 T의 수행을 취소하여 원자성 보장 - 모든 갱신 효과가 주기억 장치로부터 디스크에 기록되지 않았을 수 있다.
➡ 어떻게 완전하게 반영되도록 하여 지속성을 보장할것인가?
트랜잭션 수행동안 위와 같은 문제들에 맞닥뜨리게 된다.
그렇기에 회복 기능이 필요하다
회복
- 버퍼의 내용을 디스크에 기록하는 것을 가능한 줄여야한다.
- 버퍼에 갱신사항 반영했지만 디스크 기록전에 고장 가능
- 고장 발생 전에 트랜잭션이 COMMIT시 회복 모듈은 이 트랜잭션의 갱신 사항을 재수행(REDO) 하여 갱신이 지속성을 지녀야한다.
- 고장 발생 전 COMMIT 실패 시 원자성 보장위해 데이터에 반영했을 가능성이 있는 모든 갱신 사항을 취소(UNDO) 해야한다.
저장 장치의 유형
- 주기억장치
- 휘발성 저장 장치
- 시스템이 다운된 후에 모두 사라진다.
- 디스크
- 비휘발성 저장 장치
- 다운되어도 유지 (디스크 헤드 고장 X 일 때만)
- 안전 저장 장치
- 모든 유형의 고장을 견딜 수 있는 저장 장치
- 두 개 이상의 비휘발성 저장 장치가 동시 고장 가능성이 낮다.
- 비휘발성 저장 장치에 두 개 이상의 사본 중복 저장하여 안전저장장치 구현
- 1개 고장확률 1%라고 가정
- 0.01 X 0.01 = 0.00001 로 고장 가능성 0.01%
재해적 고장과 비재해적 고장
- 재해적 고장
- 디스크가 손상을 입어 데이터베이스를 읽을 수 없는 경우
- 데이터베이스를 백업해 놓은 자기테이프를 기반으로 회복한다.
- 비재해적 고장
- 대부분의 회복 알고리즘들 적용
- 로그를 기반으로 한 즉시 갱신 (대부분 이용)
- 로그를 기반으로 한 지연 갱신
- 그림자 페이징
- 대부분의 회복 알고리즘들 적용
로그를 사용한 즉시 갱신
즉시 갱신
갱신 사항이 주기억 장치의 버퍼에 유지되다가 트랜잭션이 완료되기 전에도 디스크의 데이터베이스에 기록이 가능하다.
-
데이터베이스에는 철회된 수행결과도 반영된다.
-
원자성과 지속성 보장을 위해 로그라고 불리는 파일 유지
-
모든 트랜잭션의 연산들에 대해 로그 레코드를 기록한다.
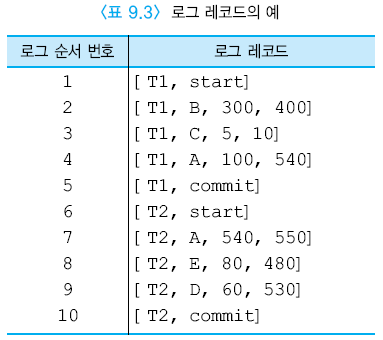
- 각 로그 레코드는 로그 순서 번호(LSN) 로 식별
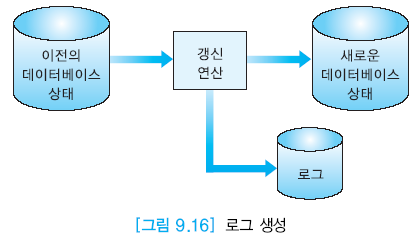
-
로그 생성 시에 로그 버퍼에 로그 레코드를 기록
- 로그 버퍼가 꽉찰 때 디스크에 기록
-
로그는 필수적이기에 안전 저장 장치에 저장된다.
-
이중 로그 : 로그를 두 개의 디스크에 중복해서 저장
-
로그 레코드가 어떤 트랜잭션 소속인지 식별하기 위해 각 로그 레코드마다 트랜잭션 ID를 포함한다.
-
동일 트랜잭션에 존재하는 로그레코드들은 이전 레코드에 대한 LSN을 포함하여 연결리스트로 유지한다.
로그 레코드 유형
- [Trans-ID, start]
- 한 트랜잭션이 생성될 때 기록되는 로그 레코드
- [Trans-ID, X, old_value, new_value]
- 수정했음을 나타내는 로그레코드
- [Trans-ID, commit]
- 성공적으로 완료하였음을 나타내는 로그 레코드
- [Trans-ID, abort]
- 철회되었음을 알리는 로그 레코드
트랜잭션의 완료점
- 데이터 베이스 갱신사항이 로그에 기록되었을 때
- [Trans-ID, commit] 로그 레코드 존재 트랜잭션 REDO
- [Trans-ID, commit] 없으면 UNDO
로그 먼저 쓰기(WAL)
- 주기억 장치의 데이터베이스 버퍼에 갱신 사항 기록, 로그버퍼에는 이에 대응되는 로그 레코드 기록
- 로그버퍼보다 데이터베이스 버퍼가 먼저 디스크에 기록 되면 시스템 다운 되었을 때 로그 레코드가 존재하지 않아 이전값을 알 수 없다.
- 트랜잭션의 취소 불가능
- 데이터베이스 버퍼보다 로그 버퍼를 먼저 디스크에 기록해야한다.
체크 포인트
DBMS가 회복시 재수행할 트랜잭션의 수를 줄이기 위해서 주기적으로 체크포인트를 수행한다.
- 오래 전에 완료된 트랜잭션은 이미 디스크에 반영되었을 가능성 농후
- 갱신 사항이 주기억 장치 버퍼로부터 디스크에 기록되었는지 확인 불가
- 체크포인트 시점에는 주기억 장치의 버퍼 내용이 디스크에 강제로 기록
- 체크포인트를 수행하면 디스크 상에서 로그와 데이터베이스의 내용 일치
- 체크포인트 작업이 끝나면 로그에 [checkpoint] 로그 레코드가 기록
작업
- 수행 중인 트랜잭션 일시적으로 중지시킨다
- 퍼지 체크포인트 알고리즘에서는 이럴 필요 x
- 주기억 장치의 로그 버퍼를 다스크에 강제 출력
- 데이터 베이스 버퍼도 강제 출력
- [checkpoint] 로그 레코드를 로그 버퍼에 기록한 후 디스크에 강제 출력
- 수행중이던 트랜잭션들의 ID도 [checkpint] 로그 레코드에 함께 기록
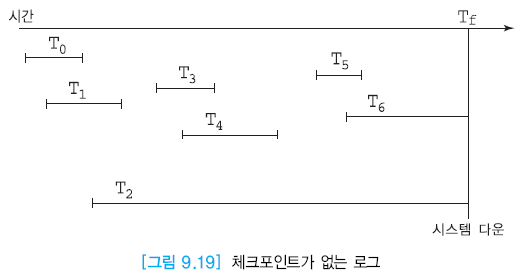
- T0, T1, T3, T4, T5, T6 는 COMMIT된 것으로 재수행
- T2, T6 취소
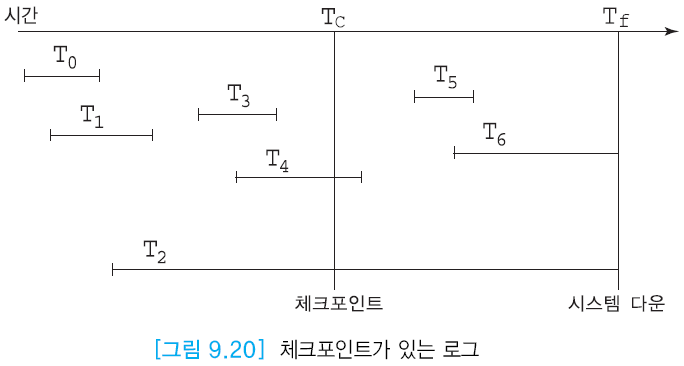
- T0, T1, T3
- 체크 포인트 이전 완료이기에 디스크레 반영 보장
- Unflushed : 디스크기록 x, 버퍼 o인 상태에서 checkpoint로 인해 모든 연산이 디스크에 반영
- T4, T5
- COMMIT된 상태로 재수행(REDO) 되어야한다.
- 체크포인트 이전의 것 엑세스하면서 이후의 것 REDO
- T2, T6
- 시스템 다운 이전에도 COMMIT이 되지 않았기에 취소(UNDO)되어야 한다.
- T2의 경우 체크포인트 이전의 레코드 엑세스하고나서 UNDO
Fuzzy checkpoint
- Tc 부분이 범위가 길다.
- 체크포인트가 명확히 어딘지 알기 힘들다
- 중요한 산업에서는 시스템을중단해서는 안되기에 중단 대신 하나씩 디스크의 버퍼를 로코를 걸어 swapping 해준다.
- Available 시간이 증가하고
- 성능 또한 증가
데이터베이스 백업과 재해적 고장으로부터의 회복
디스크 헤드 고장으로 인해 데이터베이스 읽지 못하는 경우
- 주기적으로 자기 테이프에 전체 데이터베이스와 로그를 백업 후 자기테이프를 안전하게 보관
- 데이터베이스 사용 허용하면서 지난 번 백업 이후의 갱신 내용만 백업하는 점진적인 백업
9.4 PL/SQL의 트랜잭션
트랜잭션의 시작과 끝
- 암시적으로 끝나거나 명시적(Commit)으로 끝날 수 있다.
- COMMIT
- 결과 데이터베이스에 반영 후 트랜잭션 완료
- ROLLBACK
- 데이터베이스에서 결과를 모두 되돌리고 트랜잭션 철회
- SAVEPOINT
- 저장점을 표시하여 트랜잭션을 더 작게 나눈다,
- ROLLBACK TO SAVEPOINT를 이용해 지정된 저장점 이후에 갱신된 내용만 되돌린다.
- SAVEPOINT가 없으면 처음으로
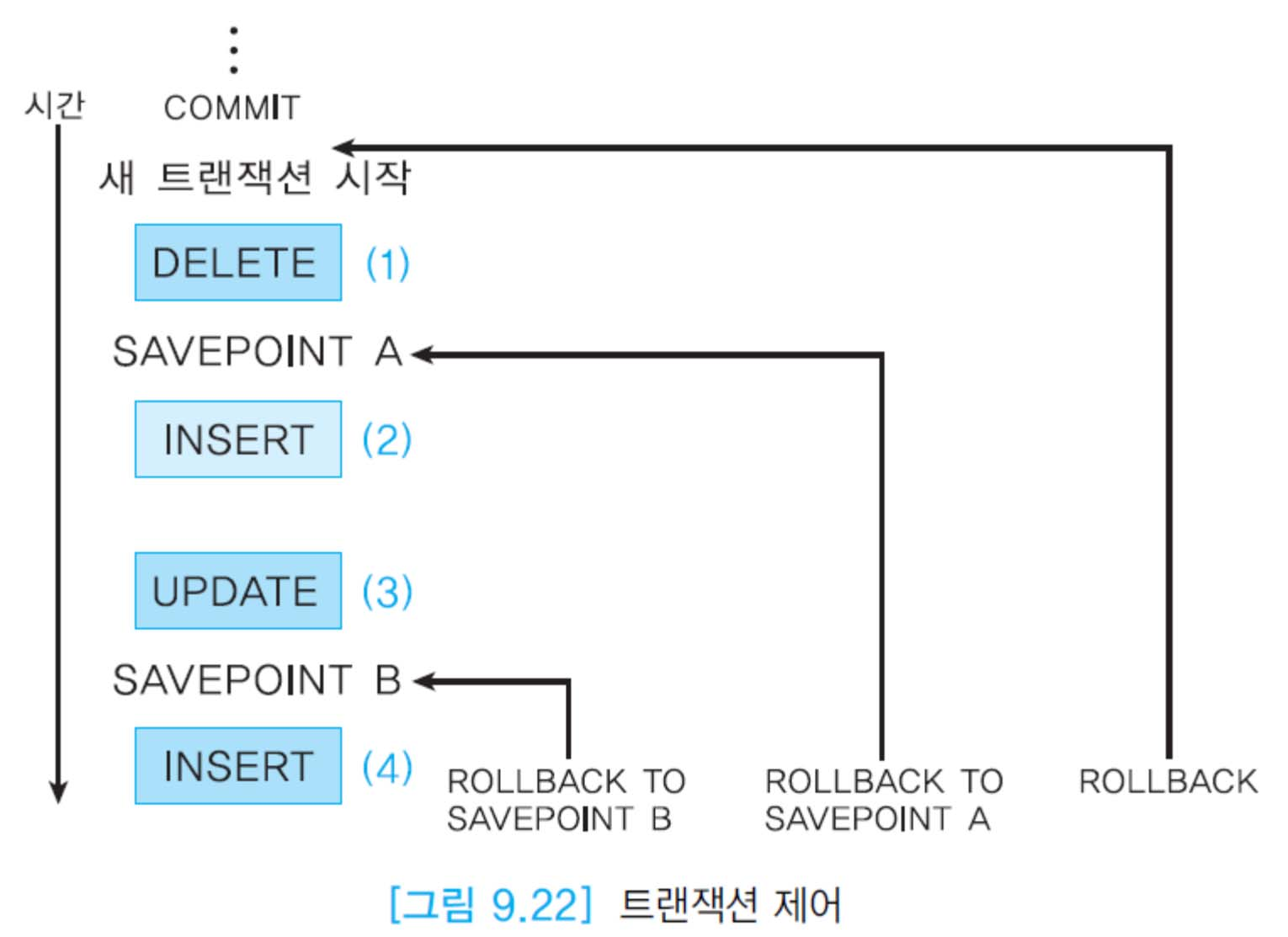
- SET 명령을 사용하여 여러 데이터 조작어 한 트랙잭션으로 처리 가능
속성
- 읽기 전용 명시하여 DBMS 동시성 정도 높일 수 있다.
- 읽기 전용이면 갱신 작업 트랜잭션 수행 불가능
- UPDATE, INSERT, DELETE
- 읽기 전용이면 갱신 작업 트랜잭션 수행 불가능
SET TRANSACTION READ ONLY- 쓰기 작업
- 모든 작업 수행 가능
- INSERT, UPDATE, DELETE, SELECT
- 모든 작업 수행 가능
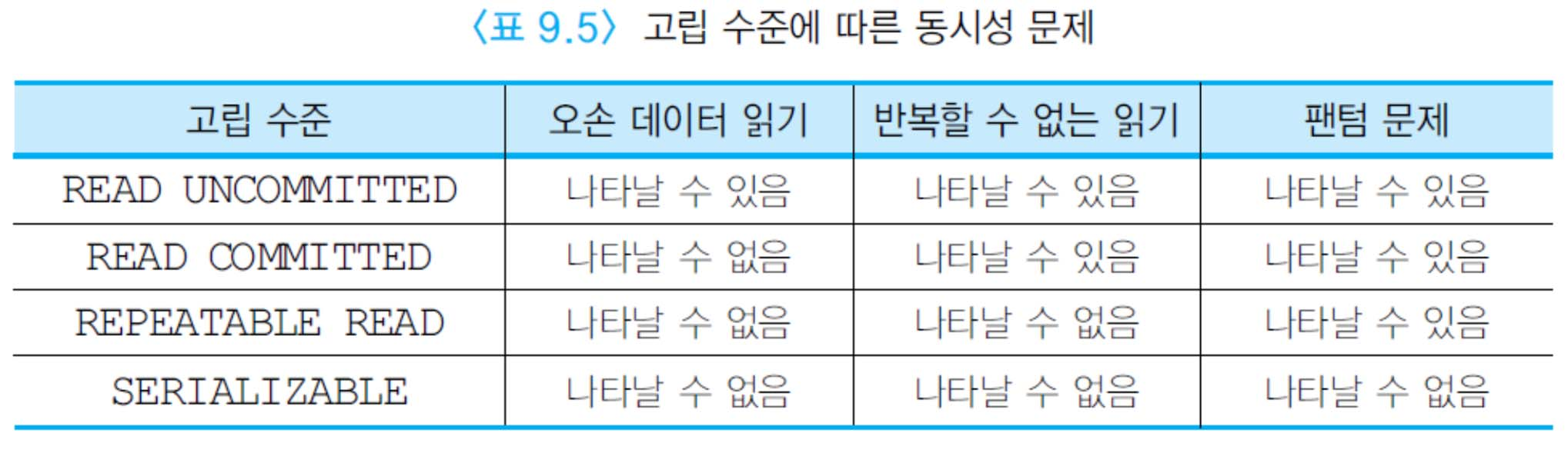
SET TRANSACTION READ WRITE고립 수준
한 트랜잭션이 다른 트랜잭션과 고림되어야 하는 정도
- 고립수준 낮으면 동시성은 높아지지만 정확성(일관성)은 저하
- 고립수준 높으면 데이터는 정확, 동시성은 저하
- 고립 수준 선택하여 성능 향상 가능
- 명시한 고립 수준에 따라 DBMS가 사용하는 로킹 동작이 달라진다.
READ UNCOMMITTED
- 가장 낮은 고립 수준
- 공유 로크 없이 데이터를 읽는다
- 다른 트랜잭션 기다릴 필요가 없기에 동시성이 높아진다.
- 오손 데이터 읽기 가능
- 갱신 데이터에 대해서는 독점 로크 걸고, 트랜잭션이 끝날 때 까지 보유한다.
- 갱신손실 허용 X
READ COMMITTED
- 읽으려는 데이터에 대해서 공유 로크 읽기가 끝나자마자 로크 해제
- 오손데이터 읽기 방지
- 2단계 로킹이 아니다.
- 일관성 저하 동시성 상승
- 다시 읽기 위해 공유 로크를 다시 걸면 이전 값과 다른 값을 읽을 수도 있다.
- 반복할 수 없는 읽기
- 갱신 데이터에 독점 로크를 걸고 트랜잭션이 끝날 때 까지 보유
- 갱신손실 허용 X
- PL/SQL의 디폴트
REPEATALE READ
- 읽으려하는 데이터에 대해 공유 로크, 트랜잭션이 끝날 때 까지 보유
- 한 트랜잭션 내에서 동일 질의 두 번 수행해도 이전 값 그대로 유지
- 반복할 수 없는 읽기 발생하지 않음
- 갱신 데이터에 독점 로크를 걸고 트랜잭션이 끝날 때 까지 보유
- 갱신손실 허용 X
SERIALIZABLE
- 가장 높은 고립 수준
- 투플뿐만 아니라 인덱스에 대해서도 공유 로크를 걸고 트랜잭션이 끝날 때 까지 보유
- 동일 질의 두 번 수행해도 매번 같은 값
- 반복할 수 없는 읽기 발생하지 않음
- 갱신 데이터에 독점 로크를 걸고 트랜잭션이 끝날 때 까지 보유
- 갱신손실 허용 X
- 가장 TRANSACTION의 특징을 만족하여 SQL2의 디폴트 고립 수준
- 동시성은 저하
REPEATABLE READ VS SERIALIZABLE
SELEECT col1 FROM A WHERE col1 BETWEEN 1 AND 10범위에 해당하는 데이터 2건(col1 = 1 and 5)
7 데이터 값 삽입 시
- REPEATABLE READ
- 다른 사용자가 col1이 1이나 5인 ROW에 대해 UPDATE 불가
- 데이터 2건 이외의 범위에 해당하는 나머지 ROW에는 INSERT 가능
- 7 삽입하려하면 가능 => 결과는 1, 5, 7
- 팬텀문제 발생
- SERIALIZABLE
- 범위 전체에 해당하는 데이터 수정 및 입력 불가
- 팬텀문제 방지