본 글은 메타코드 M에서 제공하는 강좌의 내용이 포함되어 있습니다.
추천 시스템을 설계할 때에는 Collaborative Filtering, MF와 같은 베이스 라인의 모델을 구축하여 성능 테스트를 진행한 성능을 고도화 하기 위한 노력을 진행합니다.
이를 개선하는 방법은 주로 다음 두 방향의 방법이 존재합니다.
- DeepLearning
- Regression
이번 글에 정리할 내용은 Deep Learning 모델에 대해 설명하빈다.
Deep Learning
- 신경망은 사람의 뇌를 모방한 구조로 여러 레이어로 구성되어 있고 각 레이어를 통해 데이터 처리 및 복잡한 패턴을 찾아낼 수 있습니다.
- 중간 레이어에서 특징 추출을 자동으로 수행합니다.
- 이미지, 음성, NLP 등에서 복잡한 패턴을 인식하는 능력이 뛰어납니다.
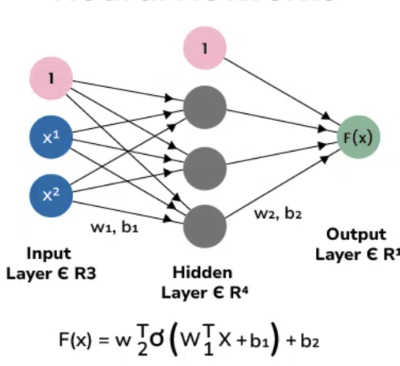
DNN (Deep Nueral Network)
딥러닝 기반 회귀모델로 해당 실습에서는 다음의 구성을 지닌다.
- ReLu 활성화 함수를 통해 3개의 은닉층에서의 값을 처리한다. 각 은닉층은 64, 32, 16개의 노드를 지닌다.
- Batch Normalization, Dropout 등의 정규화 기법을 사용한다.
- 입력층은 총 128개의 노드로 구성되어 있다.
from keras.models import Sequential
from keras.layers import Dense, Dropout, BatchNormalization
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
# Define the model
model = Sequential()
model.add(Dense(128, activation='relu', input_shape=(X_train.shape[1],))) # fully connected, 레이어 입력층 선언
model.add(BatchNormalization()) # 레이어의 출력을 정규화하여 학습을 안정적으로 만듦
model.add(Dropout(0.2)) # 랜덤하게 20% 가중치 삭제
model.add(Dense(64, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(32, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(16, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(1)) #출력층으로, 1개의 노드만 가짐. 출력값이 하나(연속형 값)로
# learning_rate=0.01 학습 속도, 학습이 진행될수록 decay=0.01를 통해 학습률이 점점 감소
optimizer = Adam(learning_rate=0.01, decay=0.01)
model.compile(optimizer=optimizer, loss='mean_squared_error')
early_stopping = EarlyStopping(monitor='val_loss', patience=5, min_delta=0.001) #reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=3, min_lr=0.0001)
model.fit(X_train, y_train, epochs=20, batch_size=256, validation_split=0.2,
callbacks=[early_stopping, reduce_lr])Neural Collaborative Filtering (NCF)
- Collaborative Filtering을 신경망 구조로 확장하여, 유저와 아이템 간의 비선형 관계를 모델링할 수 있도록 한다.
- 유저의 latent factor와 item의 latent factor를 찾아내 학습한다.
Tranditional Collborative Filtering vs NCF
- 기존의 Tranditional Collaborative Filtering은 선형 모델에 의존
- NCF는 MLP를 통해 비선형 구조를 처리하며 이러한 과정에서 유저와 아이템 간의 latent factor를 포착할 수 있다. 즉, 좀 더 좋은 표현공간으로 특징을 전이하여 처리한다고 볼 수 있다.
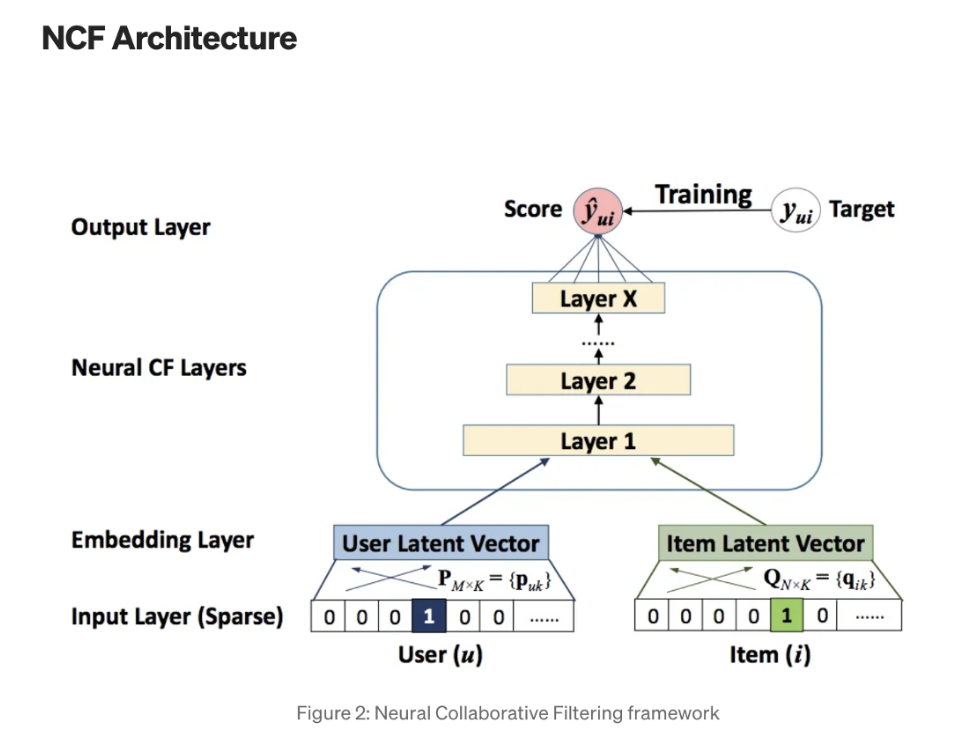
# Neural Collaborative Filtering model
n_latent_factors = 64
user_input = Input(shape=(1,))
item_input = Input(shape=(1,))
user_embedding = Embedding(n_users, n_latent_factors)(user_input)
user_vec = Flatten()(user_embedding)
item_embedding = Embedding(n_items, n_latent_factors)(item_input)
item_vec = Flatten()(item_embedding)
concat = Concatenate()([user_vec, item_vec])
dense = Dense(256, activation='relu')(concat)
dense = BatchNormalization()(dense)
dense = Dropout(0.2)(dense)
dense = Dense(128, activation='relu')(dense)
dense = BatchNormalization()(dense)
dense = Dropout(0.2)(dense)
output = Dense(1)(dense)
model = Model([user_input, item_input], output)
model.compile(optimizer='rmsprop', loss='mean_squared_error')
model.fit([X_train['user_id_mapped'], X_train['isbn_mapped']], y_train, epochs=2, batch_size=128, validation_split=0.2)
y_pred = model.predict([X_test['user_id_mapped'], X_test['isbn_mapped']])