Abstract
- 이 논문은 단어 사용의 복잡한 특성(문법, 의미)과 이들이 언어적 context에서 어떻게 사용되는지를 모델링한 새로운 종류의 deep contextualized word representations (문맥과 깊게 연관된 단어 임베딩)를 소개한다.
- 거대한 단어 말뭉치로 pre-trained된 deep bidirectional language model (biLM)의 내부 state로부터 단어 임베딩 생성.
- 위 임베딩은 기존 모델에 쉽게 추가할 수 있고, 여러 NLP task에서 SOTA 달성
1. Introduction
- 기존 pre-trained 단어 임베딩(Word2Vec, Glove)은 문법, 의미, 다의성을 포함하여 학습하기 어려웠다. (단어를 독립적인 요소로 취급)
- 우리의 임베딩은 이전의 기법처럼 LSTM의 최상위 layer만 사용하는 것이 아닌, LSTM의 모든 layer의 출력값을 활용해 만든다. → ELMO라고 부른다.(Embeddings from Language Models)
- LSTM의 낮은 layer(입력에 가까운)는 문법 정보를, 높은 layer(출력에 가까운)는 의미, 문맥정보를 학습한다.
2. Related Work
- 기존 방식(Word2Vec, Glove)은 한 단어에 하나의 vector만 생성하는 단점이 있다. 이를 극복하기 위해 보조 단어 정보를 활용해서 다양한 뜻을 표현할 수 있도록 하거나, 단어의 의미별로 vector를 생성하는 방법을 고려했다.
- ELMO는 보조 단어 정보의 이점을 character convolution 방법을 통해 학습한다. 또한 여러 벡터를 만들 필요도 없다.
- 기존 Context-dependent representation 방법도 있다.
- 양방향 LSTM을 사용하는 context2vec (중심이 되는 특정한 단어 주변의 문맥을 임베딩)
- 표현 안에 pivot word 자체를 포함하는 CoVe (문맥에 중심이 되는 단어까지 포함해서 문맥을 임베딩)
- 과거의 연구들도 deep biRNN의 서로 다른 층은 서로 다른 특성을 임베딩한다는 것을 발견했다.
- 높은 LSTM층(higher-level)은 문맥에서 단어의 의미를 학습하게 되고, 낮은 층(lowe-level)은 단어의 문법적인 측면(POS 등)을 학습하게 된다
- ELMO도 유사한 방식으로 학습하고, 기존의 task에 함께 적용해서 사용하면 더 좋은 성능을 제공한다.
💡 character convolution
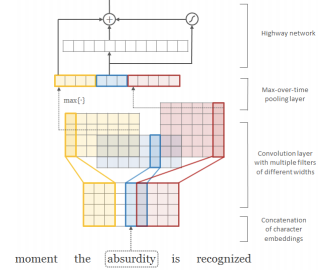
각 단어를 character-level로 표현. 각 문자를 벡터로 바꾸고, 문자 벡터들을 concat. concat 후에 CNN 1D를 사용해서, h=2,3,4등이 다양한 크기의 필터를 사용해 subword feature 추출. 이후 이를 concat해서 단어를 나타내는 초기 벡터로 사용.
3. ELMO: Embedding from Language Models
- 전체 문장을 input으로 받고, 그에 대한 각 단어들의 representation 생성한다.
- 해당 representation은 2 개의 biLM 층과 character convolution 입력을 이용해서 생성하게 된다.
- 큰 사이즈로 biLM pre-train 시켰을 때 semi-supervised learning 가능하다.
- 기존의 NLP 구조와 쉽게 합쳐져서 사용될 수 있다.
3.1 Bidirectional language models
- BiLM ⇒ forward language model + backward language model
- N개의 토큰 (t1,t2,…,tN)이 있다고 가정
-
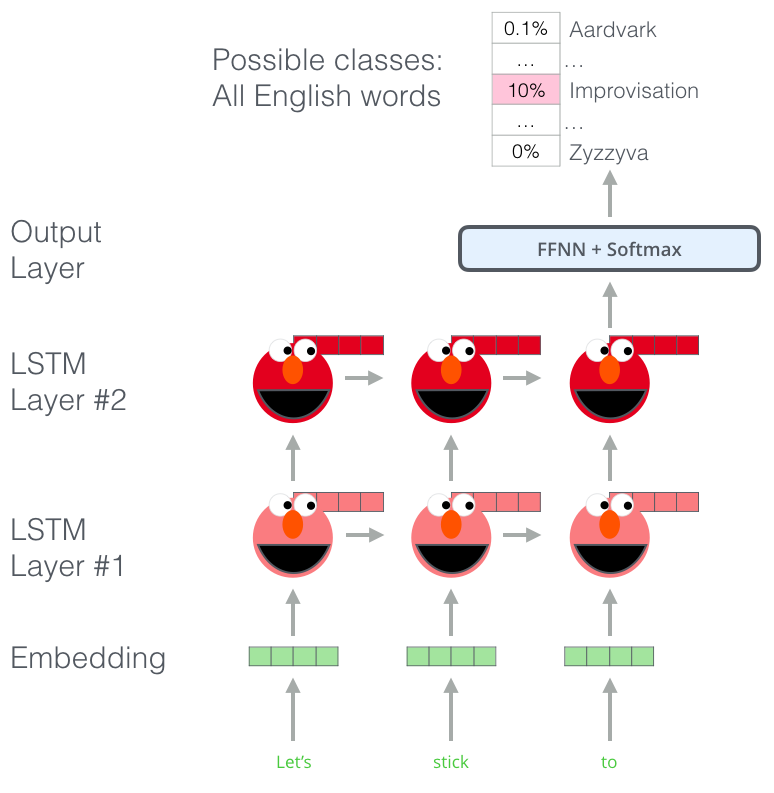
forward language model

- (t1,t2,…,tk)을 이용해 토큰 tk+1를 예측하는 모델
- LSTM 사이에 residual connection 존재
- 과정
-
독립적인 토큰 계산 (token embedding 방식이나 character convolution 방식 이용)
-
계산한 토큰을 forward LSTM의 L개의 layer에 전달
-
각 위치 k에서, 각 LSTM 레이어는 문맥 의존적인 representation 산출
-
가장 상단의 LSTM 레이어의 ouput은 softmax layer에 태워 다음 토큰 tk+1 예측
-
-
backward language model

- forward LM과 같은 방법이되 방향은 반대
- 미래의 단어들로 이전 단어들 예측
- backward가 필요한 이유
- I read a book yesterday를 forward로 예측할 경우 i → read를 예측할 때 과저형이라는 정보가 없어 현재형 임베딩으로 출력할 가능성이 높다.
- backward LM 사용시 yesterday의 정보를 갖고 있어 read를 과거형으로 구분하기 쉬워진다.
-
두 방향 결합
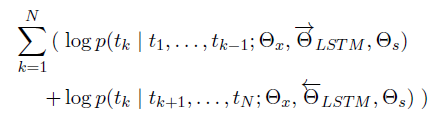
- 두 식을 곱한 후 log 취하고 tk가 위치할 Maximum Likelihood 계산
- Θx는 token representation, Θs는 Softmax layer
- ΘLSTM은 각 방향 LSTM layer에서 사용되는 파라미터로 방향마다 다른 파라미터 학습
3.2 ELMO
-
ELMO는 biLM에서 등장하는 중간 layer의 representation들을 task-specific하게 합친 것이다.
-
biLM의 L개의 layer는 각 토큰 tk당 2L+1개(forward, backward, input)의 representation을 계산
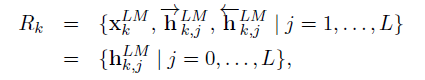
-
특정 task specific model로 포함을 위해, ELMo는 R의 모든 layer를 하나의 벡터로 압축
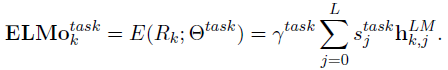
-
은 softamx-normalized weights로 task에 따라 가중치가 달라지고, 어떤 층에 집중할지 결정
-
는 최종 벡터의 크기를 결정 (해당 파라미터는 optimization 과정에서 중요한 역할수행)

-
3.3 Using biLMs for supervised NLP tasks
-
pre-train된 biLM과 NLP task에 대한 supervised 모델 구성이 주어질 때, 모델 성능을 향상시키기 위해 biLM을 사용하는 방법은 간단하다.
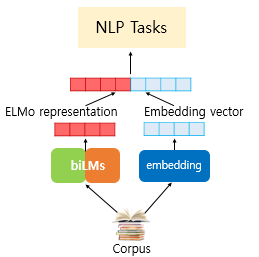
- biLM의 가중치는 고정
- NLP 모델의 input layer와 다음 layer 사이에 ELMO 추가
- 즉, input token과 ELMO embedding vector의 concat을 input으로 사용
-
특정 task에서는 output 단계에서 ELMO를 추가하는 방식이 효과적일 때도 있다.
-
마지막으로 EMLO에 적절한 dropout을 추가하는 것이 좋고, loss에 를 더해 ELMO weight를 정규화하는 것이 좋다. 이는 ELMO weight에 inductive bias를 유도하여 모든 biLM layer의 평균에 더 가까워지도록 하여 성능에 도움을 준다.
**Inductive Bias**
학습 시에는 만나보지 않았던 상황에 대하여 정확한 예측을 하기 위해 사용하는 추가적인 가정을 의미합니다.
데이터의 특성에 맞게 적절한 Inductive Bias를 가지는 모델을 사용해야 높은 성능을 기록할 수 있고 CNN의 경우 Locality(근접 픽셀끼리 종속성), Transitional Invariance(사물 위치가 바뀌어도 동일 사물 인식)등의 특성을 가지기 때문에 이미지 데이터에 적합한 모델이 되는 것입니다.https://dacon.io/en/forum/405840?page&dtype&ptype
3.4 Pre-trained bidirectional language model architecture
- 본 논문의 pre-train biLM은 양방향을 함께 학습하고, LSTM layer 사이에 residual connection 추가 → input의 feature를 더 잘 전달 & gradient vanishing 해결
- L=2인 biLSTM layer 사용, 4096개의 unit과 512차원의 projection 사용
- biLSTM의 input으로는 2048 character n-gram을 CNN에 넣는 char-CNN embedding 사용
4. Evaluation
<주요 task 성능 비교>
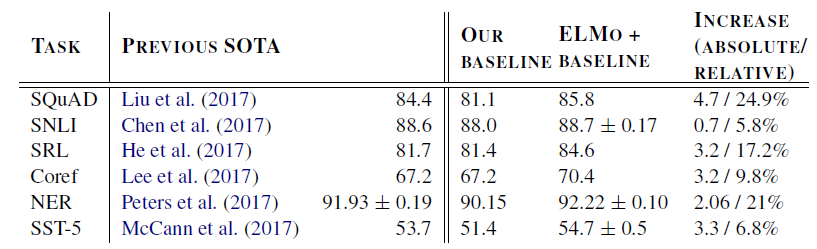
- 6개의 NLP task에서 ELMO를 추가한 것만으로 SOTA보다 좋은 성능 확인
5. Analysis
5.1 Alternate layer weighting schemes
-
λ : regularization strength (regularization의 중요도??, overfitting 방지로 regularization 사용 그 때 람다로 regularization 조절)
-
Regularization parameter인 λ는 매우 중요한 역할을 수행하는데, 해당 값이 1과 같이 매우 큰 경우 전체 weight function이 단순히 평균을 내는 역할을 수행하게 되고, 값이 매우 작아지면, 각 층에 대한 weight 값이 다양하게 적용된다.
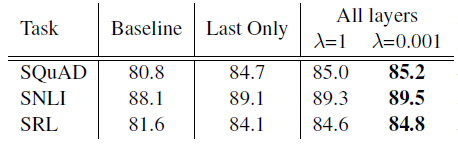
- 각 층의 weight값이 다양할 때 더 성능이 좋은 것을 확인할 수 있고, task의 종류의 영향은 받지 않는 것으로 확인
5.2 Where to include ELMO?
-
ELMO를 추가시키는 위치
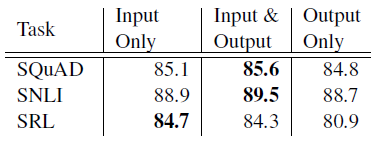
- SQuAD, SNLI의 경우 output에도 ELMO를 추가시켜주는 것이 더 좋은 성능을 보임
5.3 What information is captured by the biLM’s representations?
- ELMO를 추가하는 것만으로 기존 단어 임베딩보다 성능이 향상되었기에, biLM의 문맥을 고려한representation은 문맥에 따라 서로 다른 representation을 제공해야 한다.

- Glove의 경우 play라는 단어에 고정된 의미를 부여, 유사한 단어들도 한정적인 표현만 제공
- ELMO의 경우 ‘어떠한 역할을 수행한다’는 의미의 play와 ‘희곡/연극’의 의미의 play를 구분할 수 있다.
- Word sense disambiguation (단어 의미 명확화), POS tagging(품사 태깅)에서 좋은 성능 보임
- 이러한 실험들은 biLM에서 모든 layer가 중요한지 알려준다. layer마다 알 수 있는 문맥 정보가 다르기 때문이다.
5.4 Sample efficiency
-
ELMO를 추가했을 때 추가하지 않았을 때보다 학습속도가 빠르다. (parameter update 횟수 및 전체 training set size를 획기적으로 줄여준다. SRL task의 경우 최대 48배까지도 차이남)
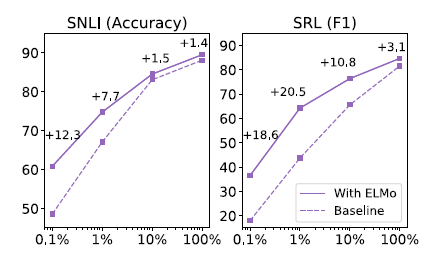
- x축: training set size
- 같은 크기의 dataset에서 ELMO를 사용하는 경우 훨씬 좋은 성능
- SRL task에서 ELMO 1%와 baseline 10%의 수치가 동일
5.5 Visualization of learned weights
-
softmax-normalized parameter Sj를 시각화
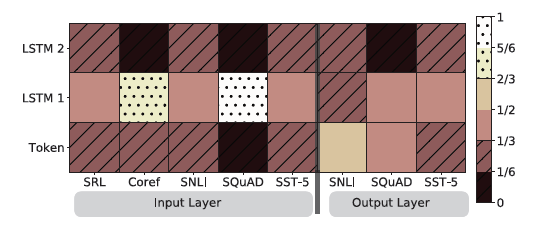
- ELMO를 biRNN의 input과 output에 사용했을 때 각각 나눠서 비교
- input에 사용되었을 때, 대부분 first LSTM layer가 가중치가 높은 것 확인
- output에 사용된 경우, 하단 layer에 더 높은 가중치를 갖고 있음을 확인 (상대적으로 균형잡힌 모습)
6. Conclusion
- biLM으로부터 고품질 문맥의존 representation을 학습한 일반적인 접근법 도입
- 광범위한 NLP task에 ELMO 적용시 큰 성능향상을 확인
- analysis을 통해 biLM의 모든 layer가 각각 효율적으로 문맥 정보를 포착하는 것을 확인했으며 (높은 layer는 semantic, 낮은 layer는 syntax), 모든 layer 사용시 전반적인 작업 향상을 보임
