Abstract
- unlabeled 말뭉치 데이터는 많지만, 특정 task를 학습하기 위한 labeled 데이터는 적다.
- 다양한 unlabeled 말뭉치를 이용한 generative pre-train과 특정 task의 fine-tuning의 큰 이점을 보여줄 것이다.
- 이전 접근방법과 다르게, fine-tuning동안 모델의 아키텍처를 최소한으로 바꾸고 효과적인 transfer learning를 위해 task-aware input 변환을 사용
- 우리의 general 모델은 특정 task에 맞춰진 모델보다 성능이 좋다. (12개 task중 9개 sota 달성)
1. Introduction
-
딥러닝 방식은 많은 labeled 데이터가 필요
- unlabeled 데이터를 활용한 모델이 (많은 시간&노력이 필요한) labeled 데이터수집의 대안이 된다.
-
지도 학습이 충분히 가능할 때 비지도 학습을 적용해 큰 성능 향상을 제공할 수 있다.
- 예시) pre-trained 단어 임베딩을 다양한 NLP task에서 사용하여 성능 향상
-
BUT) unlabeled 데이터에서 단어 수준 이상의 정보를 활용하는 것은 어렵다!
-
어떠한 objective를 이용해야 결과로 제공된 representation이 transfer learning에 유용한지 모른다.
- ex) language modeling, machine translation …
-
이렇게 학습된 representation을 대상 task로 transfer하는 효과적인 방법이 없다..
- 기존: task별로 모델 아키텍처 변경, 복잡한 학습 계획, 보조 학습 목표 추가…—> 이러한 불확실성으로 효과적인 반 지도학습(semi-supervised)이 어렵다.
-
이 논문에서는
-
unsupervised pre-training과 supervised fine-tuning을 조합한 semi-supervised 접근법 탐구
-
목표: 광범위한 NLP task에 적용되는 representation 학습
-
two-stage 학습 방법
- 먼저, unlabeled 데이터에 language modeling을 이용하여 초기 파라미터 학습
- 이렇게 초기화된 파라미터를 target task의 objective 알맞게 추가적으로 학습
-
모델 아키텍처: transformer 사용
-
transfer learning 동안, task-specific 한 입력을 생성 사용
- 이러한 방식은 다양한 task에 해당 모델을 최소한의 변화로 fine-tuning 할 수 있게 한다.
-
평가 방법 (4가지 task 사용)
- 자연어 추론(NLI): 상황을 설명하는 문장이 주어졌을 때 그 상황에 대한 상식적인 추론
- QA
- 의미 유사(semantic similarity)
- 문서 분류(text classification)
-
12개 중 9개의 task에서 SOTA 달성
-
추가적으로, pre-trained 모델의 zero-shot을 분석하고 downstream task에 유용함을 보임
2. Related Work
Semi-supervised learning for NLP
-
semi-supervised learning은 sequence labeling, text classification에 적용하면서 관심받음
-
초기: unlabeled 데이터의 단어 수준, 문단 수준의 통계 계산 → supervised 모델에 feature로 사용
-
몇년후: unlabeled 데이터로 학습된 word embedding이 다양한 task의 성능을 향상시킨 것을 증명
- 이런 방식은 단어 수준 정보만 사용
-
최근: unlabeled 데이터에서 단어 수준 이상의 학습 및 활용이 연구되고 있다.
- 예시) 문단, 문장 수준의 embedding은 text를 다양한 task에 적합한 representation으로 인코딩하는데 사용
Unsupervised pre-training
-
unsupervised pre-training은 좋은 초기화 지점을 찾는 semi-supervised learning의 special case
-
pre-training이 정규화 역할을 하여 DNN에 일반화에 도움이 되는 것을 확인
- 최근: 이미지 분류, 음성 인식, 기계 번역 등에서 사용되고 있다.
-
pre-training에서 LSTM을 사용하면 예측 능력이 짧은 범위로 제한된다.
- 우리는 Transformer 선택 → 예측 능력이 긴 범위로 확장
-
pre-trained 된 모델로 생성한 representation을 보조 기능으로 사용하면서 fine-tuning 진행
- transfer learning 동안, 최소한의 아키텍처 수정만 요구 (다른 모델은 많은 파라미터 추가)
Auxiliary training objectives (보조 훈련 목표함수)
- Auxiliary unsupervised training objectives는 semi-supervised learning의 대안
- 기존에 semantic role labeling의 개선을 위해 POS 태깅, NER, 등을 사용
- 우리도 Auxiliary training objectives를 사용하지만, unsupervised pre-training는 이미 task와 관련된 여러 언어적 측면을 학습한다.
3. Framework
- two-stage 학습
- 대량의 unlabeled 데이터로 고용량(high-capacity) 언어 모델 학습
- fine-tuning (labeled 데이터를 이용하여 task에 적용할 수 있게 학습을 진행)
3-1 Unsupervised pre-training
-
unlabeled corpus
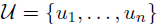
-
standard language modeling objective 사용
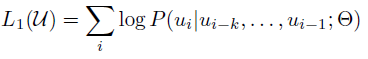
- k: context window 크기
- P: 조건부 확률(세타가 있는 NN을 이용하여 모델링된다.)
- 세타: SGD를 이용하여 학습
-
multi-layer Transforemr decoder를 활용
-
대상 token에 대해 출력 분포를 생성하기위해 position-wise feed forward layer가 뒤 따르는 input token에 대해 multi-headed self-attention 적용
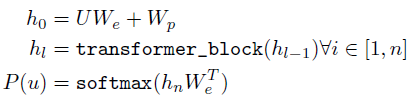
- U: token의 context vector
- n: layer의 개수
- We: token embedding matrix
- Wp: position embedding matrix
-
3-2 Supervised fine-tuning
-
C: labeled dataset (입력 토큰: x1….xm, label: y)
-
input을 pre-trained 모델에 넣고, 최종 transformer 블록의 activation(?) hlm을 얻는다.
- y를 예측하기 위해, hlm을 파라미터 Wy가 있는 선형 layer에 넣는다.
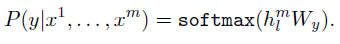
- objective
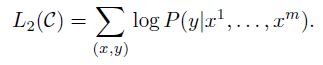
- y를 예측하기 위해, hlm을 파라미터 Wy가 있는 선형 layer에 넣는다.
- fine-tuning의 보조 목표로 language modeling을 추가 시킴
-
supervised 모델의 일반화 개선
-
수렴을 가속화하여 학습에 도움
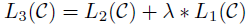
-
3-3 Task-specific input transformations
-
텍스트 분류의 경우, pre-trained 모델을 바로 fine-tuning 할 수 있다.
-
QA, textual entailment(의존 구문 분석)의 경우 입력의 형태가 바뀌어야 한다.
- pre-trained 모델은 연속된 text sequence에 대해 훈련 → 약간의 수정 필요
-
이전까지는 최상위 representation에 task별로 아키텍처를 추가했습니다.
- 상당량의 task별 사용자 지정을 도입해야 하고, 추가 아키텍처에 대해서는 transfer learning을 하지 않습니다.
-
우리는 순회 스타일 방식을 사용
- 구조화된 입력을 pre-trained 모델이 처리할 수 있는 순서화된 sequence로 변환하는 방식
- 입력을 변환하여 아키텍처의 큰 변경을 피할 수 있다.
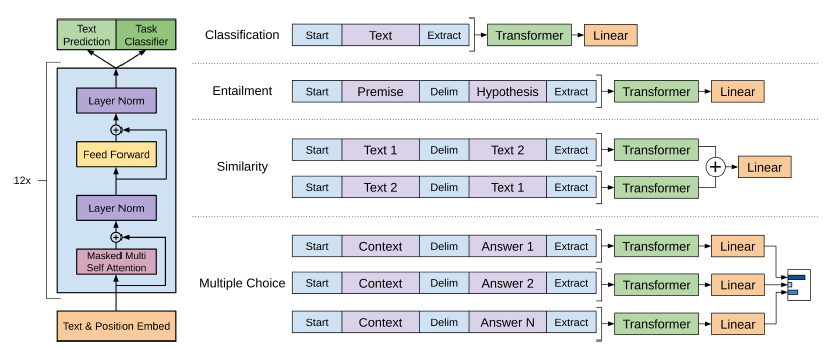
-
왼쪽: Transformer 아키텍처 & training objective
-
오른쪽: 다양한 task별로 입력 변환, 뒤에 linear + softmax 레이어 붙임
-
Textual entailment: 그림 참고
-
Similarity: text의 순서가 없다!
-
QA: context + question + {delim} + answer / 각 sequence는 독립적으로 처리 후, softmax로 정규화
4. Experiments
4-1 Setup
- Unsupervised pre-training
- BookCorpus dataset (어드벤처, 판타지, 로맨스 등 다양한 장르의 7000권 책, 미출간 포함)
- 긴 연속 context가 포함되어 있어 long-range 조건으로 학습 가능
- 1B Word Benchmark
- ELMO에서 사용, 문장 수준에서 뒤섞여 long-range 구조를 파괴되어 있다.
- Task별로 사용한 Dataset

- BookCorpus dataset (어드벤처, 판타지, 로맨스 등 다양한 장르의 7000권 책, 미출간 포함)
-
Model specifications
Parameter Descrption State dimension decoder: 768, inner state: 3072 Batch size 64 random sample ×× 512 token/sample Schedule 100 epochs, Optimizer Adam Learning Rate 0~2000 step까지 2.5e-4까지 증가, 이후 cosine 함수를 따라 0으로 서서히 감소 warmup_steps 4000 Regularization L2(w=0.01w=0.01) Activation GELU(Gaussian Error Linear Unit) - original transformer를 따름
- decoder만 사용
-
Fine-tuning details
- Unsupervised pre-training의 파라미터 그대로 사용
- p=0.1 dropout 추가
- Learning Rate: 6.25e-5
- batch size: 32
- epoch: 3
- learning rate decay는 warmup을 포함해 각 학습당 0.2%, λ=0.5
4-2 Supervised fine-tuning
-
NLI, QA, Semantic Similarity, text classification에 대하여 평가 진행 (일부는 GLUE 포함)
-
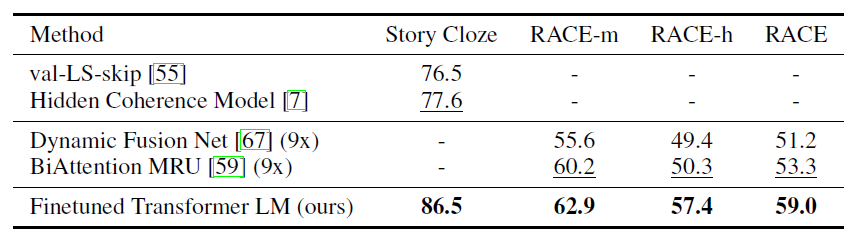
Natural Language Inference
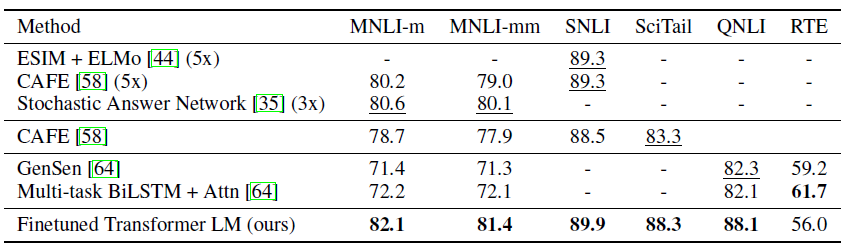
- Question answering and commonsense reasoning
- Semantic Similarity & Classification
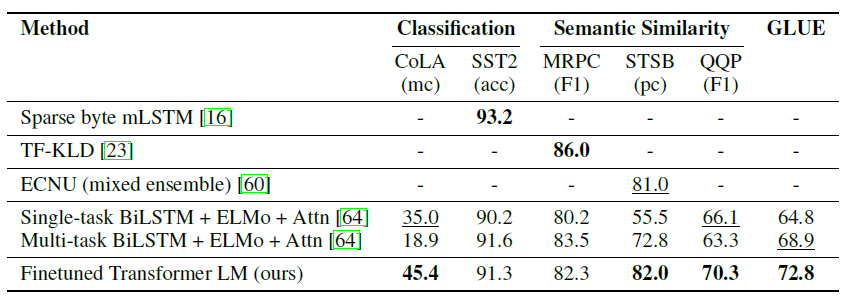
- 앙상블도 능가했다.
- 우리의 방식이 작은 데이터셋부터 큰 데이터셋까지 잘 작동함을 알 수 있었다.
5. Analysis
Impact of number of layers transferred
-
transferring embedding이 성능 향상에 도움이 되며, 각 transformer layer 당 최대 9%의 성능향상을 발견 → pre-trained 모델의 각 layer가 task를 해결하는데 유용한 기능을 포함
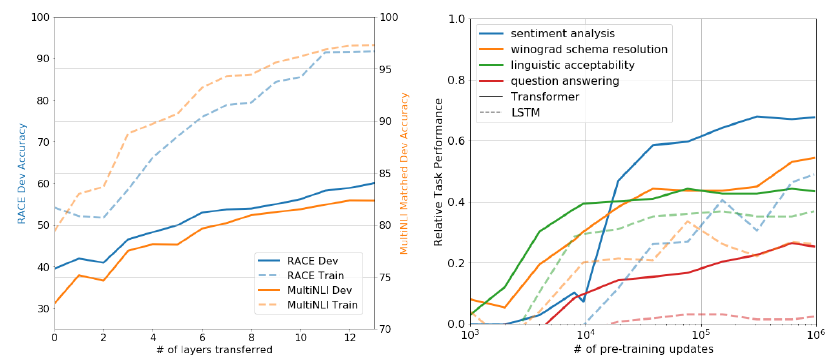
- 오른쪽: zero-shot 관련
Zero-shot Behaviors
- LSTM과 비교해서 Transformer의 attention 구조가 transfer learning에 더 효과적이다.
- LSTM은 zero-shot 성능에서 큰 편차를 보였다.
- zero-shot은 Transformer 구조의 귀납적 편향이 전이를 돕는다고 암시한다.
Ablation studies

- fine-tuning에서 language modeling objective를 제거했을 때
- 큰 dataset은 성능 down, 작은 dataset은 성능 up
- LSTM과 비교
- 성능 하락
- pre-train없이 바로 fine-tuning
- 약 15% 정도 성능 하락
6. Conclusion
- pre-train + fine-tuning으로 natural language understanding에 대한 강력한 framework 소개
- 긴 연속 text가 있는 다양한 corpus pre-train으로 모델이 세계 지식과 long-range 학습이 가능
- 우리의 연구가 다양한 분야의 비지도 학습의 작동방식과 이해를 더욱 향상시키는 데 도움이 되었으면 한다.
