✏️학습 정리
8. GPT 언어 모델
- GPT 모델 구조
-
Transformer의 Decoder 부분만 사용
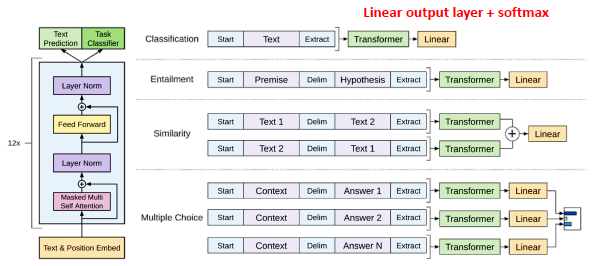
-
- GPT 모델 특징
-
적은 데이터로도 높은 분류 성능
-
다양한 자연어 task에서 SOTA 달성
-
Pre-train 언어 모델의 새 지평을 열음 (BERT의 밑거름)
-
여전히, 지도 학습 필요, labeled data가 필수
-
특정 task를 위해 fine-tuning된 모델은 다른 task에서 사용 불가
—> 언어의 특성 상, 지도학습의 목적 함수는 비지도 학습의 목적함수와 같다!
—> fine-tuning이 필요없다!
—>엄청 큰 데이터셋을 사용하면 자연어 task를 자연스럽게 학습!!
-
- Few-shot learning
-
다음 단어 예측 방식은 SOTA
-
but, 기계 독해, 요약, 번역 등의 자연어 task에서는 일반 신경망 수준...
—> Zero, One, Few-shot learning 제시!
-
- 생각해볼것
- 다음 단어, masked 단어 예측 방식이 정말 다 해결될까?
- Weight update가 없다는 것은 새로운 지식 학습이 없다는 것.. → 시기에 따라 달라지는 문제 대응 불가
- 모델 사이즈만 키우면 되는 것인가?
- 멀티 모달 정보가 필요! (GPT는 글로만 학습)
9. **GPT 언어모델 기반의 자연어 생성**
- 실습
실습
-
GPT-2 pre-training
-
텍스트 생성 방법 (서로 다른 디코딩 방법 사용)
- Greedy Search
- Beam Search
- Sampling
- Top-K Sampling
- Top-p (nucleus) Sampling
-
Few-shot learning
- KoGPT-2를 활용한 Few-shot
- KoGPT-2를 활용한 Zero-shot
-
KoGPT-2 기반의 챗봇
🗣️피어세션
- 주말동안 실험한 것 insight 공유
- entity 제시를 질문형 문장으로 실험 → 성능 향상이 오차 범위 내
- batch size 증가 (16 → 64), 유의미한 성능 향상 (LB f1 score 2점 상승)
- 전처리를 했을 때 보다 하지 않은 경우 성능 증가...
- train data의 중복 데이터셋, 미스 라벨링 존재...
- 수정해야 하나 고민

함께 자라기