✏️학습 정리
10. Transformer와multi-modal 연구
-
BERT 이후 다양한 LM
-
XLNet
-
Relative Positional Encoding
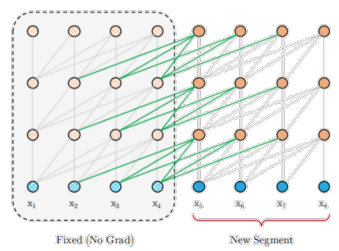
- Positional Encoding → token 간 관계성 표현
- BERT처럼 절대적 위치를 표현하는 것이 아닌, 현재 token의 상대적 거리 표현법 사용
- Sequence 길이 제한 X
-
Permutation Language Modeling
- 토큰들의 모든 순열 조합 생성 후 학습
-
-
RoBERTa
- BERT 구조에서 학습 방법 고민
- Model 학습 시간 증가 + Batch Size 증가 + Train data 증가
- Next Sentence Prediction(NSP) 제거 → 너무 쉬운 task라 성능 하락시킴
- Longer sentence 추가
- Dynamic Masking: 똑같은 텍스트 데이터에 대해 masking을 10번 다르게 적용하여 학습 (문제를 어렵게 만듦)
-
BART
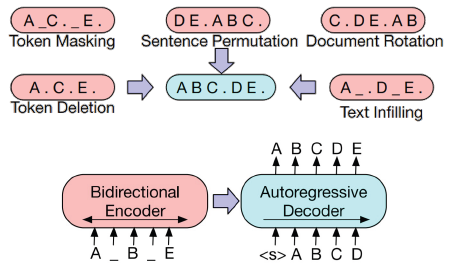
- Transformer Encoder, Decoder 통합 LM
-
T-5
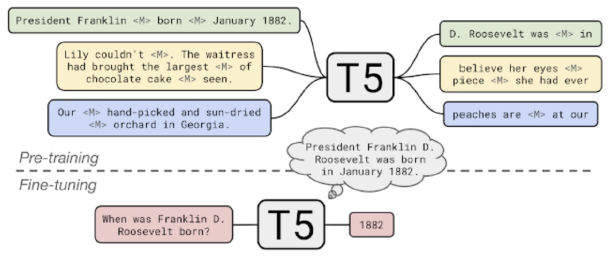
- Transformer Encoder, Decoder 통합 LM
- 단일 단어가 아닌 여러 단어를 Masking
-
Meena
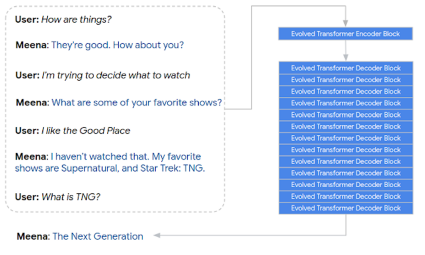
- 대화 모델을 위한 LM
- end-to-end multi-turn 챗봇
- 챗봇 평가 metric SSA에서 압도적 성능 (기존 SOTA와 비교했을 때)
-
Controllable LM
-
모델의 편향 제어
-
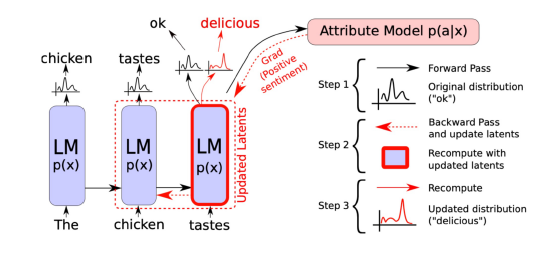
Plug and Play Language Model (PPLM)
-
보통 모델들은 다음에 등장할 단어를 확률 분포를 통해 선택
-
내가 원하는 단어들의 확률이 최대가 되도록 이전 상태의 vector를 수정
-
수정된 vector를 통해 다음 단어 예측
-
확률 분포를 사용하기 때문에, 중첩 가능
-
특정 카테고리에 대한 감정 컨트롤 가능 (범죄 사건에 대해서 부정적 단어 선택 등..)
-
-
-
-
Multi-model Language Mod
-
할머니세포
- 이 세포는 1개의 단일 세포가 어떤 개념에 대해 반응
-
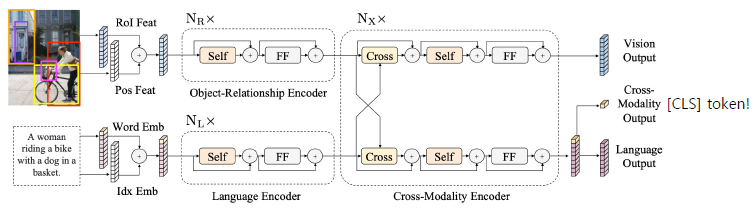
LXMERT
-
이미지와 자연어를 동시에 학습
-
Cross-modal reasoning language model
-
이미지 feature, 자연어 feature가 하나의 모델에 반영
-
-
ViLBERT
-
BERT for vision-and-language

-
-
Dall-e
- 자연어로부터 이미지를 생성해내는 모델
- 과정
- VQ-VAE를 통해 이미지의 차원 축소 학습
- Autoregressive 형태로 다음 토큰 예측 학습
-
🗣️피어세션
- 서로 실험 셋팅이 조금씩 달라 고정
- max_len: 256
- 모델: roberta-large, 4 epoch
- TAPT 적용 (세부설정은 좀더 실험하고..)
- data 전처리 수행 X, special token은 punctuation(#, @) 사용

함께 자라기