📝 Wrap-up report
대회 개요
직접 RE 태스크에서 사용할 데이터를 제작해보기
- 팀 내부적으로 데이터 가이드를 만들고 이를 바탕으로 한 레이블링을 함께 진행한다.
- Relation set의 구성 및 정의, 가이드라인 작성, 파일럿 및 메인 어노테이션, 그리고 간단한 모델 Fine-tuning의 과정을 통해 실제 데이터 제작의 workflow를 경험할 수 있다.
- 이 과정에서 정밀한 가이드라인 제작의 중요성과 inter-annotator agreement(IAA)의 개념을 체득할 수 있다.
- 직접 데이터를 만들고 train / validation / test set으로 나누어 데이터의 활용성을 확인하는 과정을 경험할 수 있다.
- 다양한 어노테이션 툴을 배우고, 데이터의 퀄리티를 검증해볼 수 있다.
데이터셋 개요
데이터셋 종류
- 인문학 데이터: 총 75개 문서들에 대한 한국어 위키피디아 원시 데이터셋을 활용
['유물사관', '증산도', '중국의 미술', '실증사관', '발레', '인상주의', '연극', '역사학', '일본의 미술', '추상 (예술)', '역사적 유물론', '조로아스터교', '서양음악', '식민사관', '희곡', '아시아의 음악', '입체주의', '바로크', '기독교', '드라마', '마술', '공연 예술', '서정시', '마르크스주의', '아브라함 종교', '야수파', '인도의 음악', '상징주의', '한국음악', '미술의 역사', '유대교', '로코코', '미학', '메소포타미아 미술', '극시', '시 (문학)', '인문학', '도교', '원불교', '다다이즘', '힌두교', '문학', '아방가르드', '서커스', '민족사관', '르네상스', '종교', '수필', '신고전주의', '불교', '사실주의', '음악사학', '초현실주의', '표현주의', '변증법적 유물론', '역사관', '서양 미술사', '오페라', '이슬람교', '아랍 음악', '미술사', '중국 음악', '소설', '일본 음악', '뮤지컬', '역사', '행위 예술', '한국의 미술', '역사주의', '춤', '유교', '음악회', '서사시', '대륙사관', '아르 누보']
(한국어 위키피디아 https://ko.wikipedia.org/ CC BY-SA 3.0)엔티티 타입
- Subject
- SUBJ-PER: 인물
- SUBJ-SYS: 무언갈 다루는 체계, 관념, 단체 모두를 뜻함(종교, 학문, 기관, 민족, 국가, 문화, 직업)
- Object
- OBJ-PER: 인물
- OBJ-SYS: 무언갈 다루는 체계, 관념, 단체 모두를 뜻함(종교, 학문, 기관, 민족, 국가, 문화, 직업)
- OBJ-DAT: 날짜
- OBJ-LOC: 장소(GPS로 찍을 수 있는 특정 장소)
- OBJ-POH: 기타 명사(작품, 저작물, 기물, ORG로 생성된 실체가 있는 것)
인문학 관계 데이터셋 클래스 명 및 예시
- 총 10개
| 클래스명(한) | 클래스명(영) | 타입(sub, obj) | 설명 | 예시 문장 |
|---|---|---|---|---|
| 관계_없음 | no_relation | (, ) | 관계를 유추할 수 없음. 정의된 클래스 중 하나로 분류할 수 없음 | 《오페라의 유령》은 프랑스의 작가 가스통 르루의 원작 소설을 찰스 하트가 뮤지컬 극본으로 만들고 뮤지컬 음악의 귀재 앤드류 로이드 웨버가 작곡하였다. |
| 체계:생성일 | sys:founded | (SYS, DAT) | Object는 Subject가 발생한 날짜, 연도, 연대, 시기 | 인상주의라는 이름은 1874년 4월 25일 미술 비평가 르로이가 파리의 전시회에서 비판적인 뜻으로 사용한 것에서 유래하며, 오늘날 서양 미술사에서 19세기 후반을 대표하는 사조로 쓰이고 있다. |
| 체계:파생물 | sys:subsystem | (SYS, SYS) | Object는 Subject의 하위&파생 개념, 단체, 체계 | 연극을 위한 대본집을 희곡이라고 하며 이는 문학의 하위 장르 중 하나이다. |
| 체계:발생지 | sys:birthplace | (SYS, LOC) | Object는 Subject가 발생한 장소, 나라, 지역, 도시 | 힌두교는 고대 인도에서 발생하였다. |
| 체계:생성물 | sys:creation | (SYS, POH) | Object는 Subject를 기반으로 만들어진 생성물 | 힌두교의 주요 경전인 베다는 기원전 1500년 경에 성립되어 베다 산스크리트어로 기록되었다. |
| 체계:관계자 | sys:member_of | (SYS, PER) | Object는 Subject의 창시자, 추종자, 관계자 | 이미 1980년대부터 김구림, 성능경, 이강소, 이승택 등의 행위예술 작가들은 이런 작업을 시도하고 있었다. |
| 사람:활동시기 | per:period_of_activity | (PER, DAT) | Object는 Subject의 활동 시기, 시간대, 시대, 연도 | 이미 1980년대부터 김구림, 성능경, 이강소, 이승택 등의 행위예술 작가들은 이런 작업을 시도하고 있었다. |
| 사람:관련인 | per:related_person | (PER, PER) | Object는 Subject와 밀접하게 관계 있는 인물(가족, 사제, 동료) | 발해 3대 왕인 문왕은 딸이었던 정효공주와 정혜공주가 죽자 각각 묘를 만들어 주었다고 한다. |
| 사람:연고지 | per:related_location | (PER, LOC) | Object는 Subject의 연고지(출생, 성장, 활동) | 평화를 위해 헌신해 온 베트남 출신의 불교지도자 틱낫한(釋一行, Thich Nhat Hanh) 스님이 이끄는 수행공동체인 Plum Village가 프랑스 보르도에 소재하고 있으며, 유럽과 미국, 베트남 등지의 스님들과 재가불자들이 주로 모여 있다. |
| 사람:저작물 | per:creation | (PER, POH) | Object는 Subject의 저작물 | 플라톤이 <국가>에서 제시한 삼계급설과 유사하다. |
타임라인

결과
IAA 점수
# raters = 5, # subjects = 1656, # categories = 9
PA = 0.8977053140096601
PE = 0.17578872902518144
Fleiss' Kappa = 0.876최종 데이터 비율
- sklearn의 StratifiedShuffleSplit 기능으로
train(60%)dev(20%)test(20%)로 라벨 간 비율을 보장하여 분할label train dev test no_relation 187(18.8%) 75(22.6%) 87(26.2%) sys:subsystem 218(21.9%) 43(12.9%) 52(15.6%) sys:member_of 149(15.0%) 50(15.1%) 41(12.3%) sys:founded 108(10.8%) 37(11.1%) 27(8.1%) sys:creation 81(8.1%) 27(8.1%) 32(9.6%) sys:birthplace 44(4.4%) 23(6.9%) 14(4.2%) per:creation 97(9.7%) 46(13.8%) 41(12.3%) per:related_location 43(4.3%) 15(4.5%) 23(6.9%) per:related_person 34(3.4%) 8(2.4%) 11(3.3%) per:period_of_activity 32(3.2%) 7(2.1%) 4(1.2%) total = 1656(100%) 993(60%) 331(20%) 332(20%)
모델 학습 결과
- 사용 모델: klue/roberta-large 사용, 10 step마다 dev set 사용하여 evaluation
- 주요 하이퍼 파라미터
- LR: 2e-5
- Epoch: 5
- Batch Size: 16
- FP16: True
- training 결과

- test 결과
micro f1 auprc accuracy 92.369 96.334 0.9157 - confusion matrix
-
‘관계_없음’을 다른 라벨로 오판별 하는 사례가 가장 많았음
-
‘사람:관련인’ 을 ‘관계_없음’으로 오판별하는 사례가 두 번째로 많이 있었음
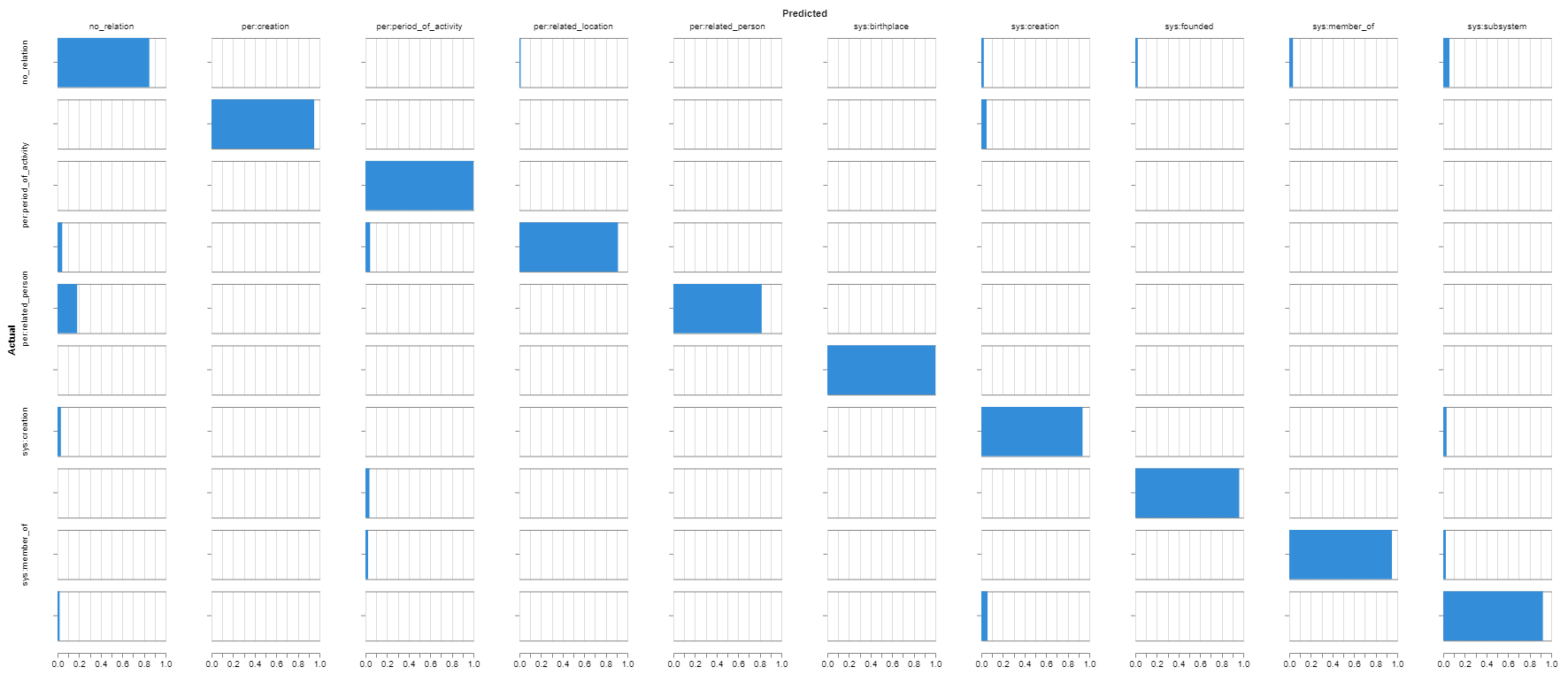
-
회고
-
생각보다 dev, test셋의 metric 지표값이 높게 나왔다.
- 원인
- Label들의 바운더리가 상당히 포괄적이었기에 model이 label을 판별하는 데 그다지 정밀성이 필요하지 않았다.
- dev, test셋을 분할할 때, train 셋에 존재하는 sentence가 label, entity 조합만 다른 상태로 유입되었을 가능성이 있다. 이로 인해 테스트 난이도가 쉬워졌을 것으로 추측한다.
- 피드백
- model의 관점에서 판별 난이도가 어떨지 고려하면서 label을 결정 하는 과정이 필요.
- 다음 프로젝트부터는 dev, test셋 분할 시에 이렇게 같은 문장이 들어가는 케이스가 있는지 면밀히 확인 후, manual 하게 걸러내는 작업을 시도.
- 원인
-
관계를 정의할 때 Type별 조합을 하나씩만 만들어 main tagging 난이도가 많이 쉬워졌다.
- 원인
- 마찬가지로 Label들의 바운더리를 포괄적으로 설정했기 때문에 발생했다.
- (Sub-Obj)의 타입만 알면 두가지 케이스 밖에 존재하지 않았기 때문에 Main Tagging 작업이 단순해졌다.
- 피드백
- 충분한 회의를 통해 엔티티 Type의 세분화가 필요할 것으로 보인다.
- 원인
-
git으로 코드관리를 하지 않아 tagging시에 혼란이 생겼다.
- 원인
- json → 구글 스프레드시트로 변경하는 코드가 간단하다고 생각되어 각자 관리를 하였다.
- 각자 코드를 관리하다보니 업데이트가 되어도 서로 알기가 힘들었다.
- 피드백
- 아무리 간단한 코드여도 git으로 코드 관리는 필수.
- 원인
-
데이터 도메인에 대한 이해의 부족
- 원인
- ‘인문학' 이라는 데이터를 고려하지 않고 기존 KLUE를 바탕으로 엔티티 Type과 라벨을 선정
- 피드백
- 데이터에 대한 면밀한 이해와 분석을 바탕으로 새로운 Type과 관계를 선정할 필요가 있다.
- 원인

함께 자라기