✏️학습 정리
3. Generation-based MRC
-
Generation-based MRC
- 주어진 지문과 질의를 보고, 답변을 생성 (생성 문제)
- 평가 방법
- EM, f1 Score (Extraction-based MRC와 동일한 방법)
- 모델 구조
- Seq-to-seq PLM 구조
- Prediction 형태
- Free-form text 형태
-
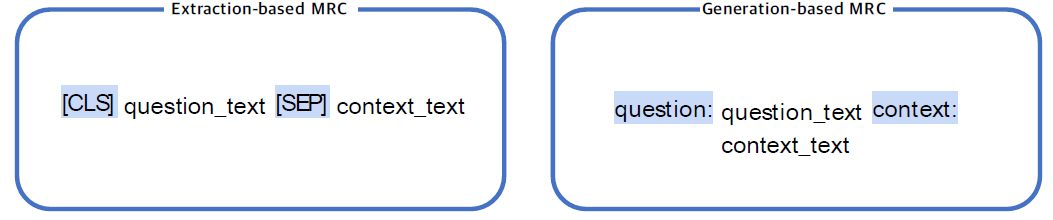
Pre-processing
- Tokenization
- WordPiece Tokenizer 사용 (Extraction-based MRC와 동일)
- Special Token
-
기존 토큰 대신 자연어를 이용하여 정해진 텍스트 포맷으로 데이터 생성
-
- Attention mask (Extraction-based MRC와 동일)
- Token type ids
- 입력시퀀스에 대한 구분이 없어 존재 X
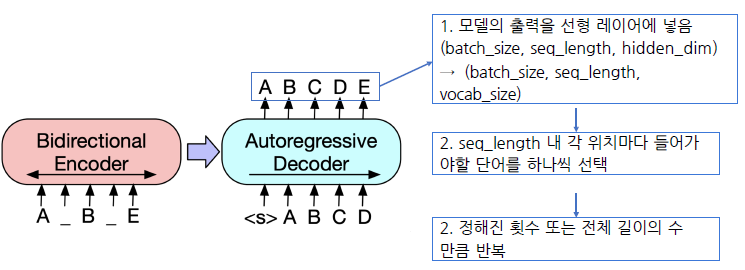
- 모델 출력
-
실제 텍스트 생성
-
전체 시퀀스의 각 위치마다 모델이 아는 모든 단어들 중 하나의 단어를 맞추는 분류 문제
-
- Tokenization
-
Model
- BART
- BERT + GPT (encoder + decoder)
- 텍스트에 노이즈를 주고 원래 텍스트를 복구하는 문제를 푸는 것으로 pre-training
- BART
-
Post-processing
- Decoding
- 디코더에서 이전 스텝에서 나온 출력이 다음 스텝의 입력으로 들어감
- Searching
- Greedy Search
- Exhaustive Search
- Beam Search
- Decoding
4. Passage Retrieval - Sparse Embedding
-
Passage Retrieval
-
질문에 맞는 문서를 찾는 것
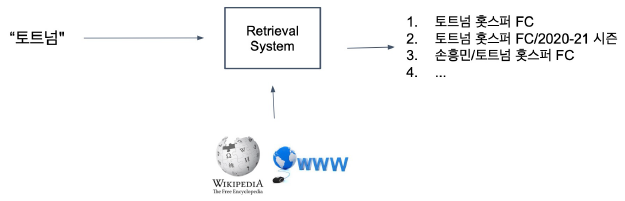
-
overview
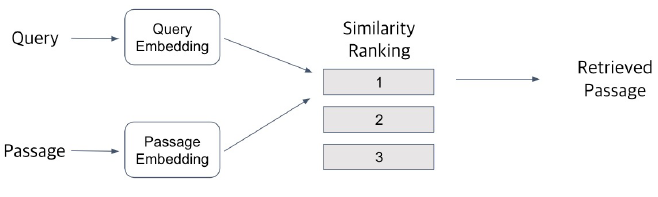
-
-
Open-domain Question Answering
- 대규모의 문서 중에서 질문에 대한 답을 찾기
- Passage Retrieval과 MRC를 이어서 2-Stage로 만들 수 있음
-
Passage Embedding Space 터 공간
- Passage 간 유사도를 알고리즘으로 계산 가능
- Sparse Embedding
- Bag-of-Words (n-gram으로 구성)
- 벡터 차원 = term 개수
- Term overlap을 정확하게 잡아 내야 할 때 유용
- 의미가 비슷하지만 다른 단어인 경우 비교 불가
-
TF-IDF (Term Frequency - Inverse Document Frequency)
- Term Frequency: 문서 내 단어의 등장 빈도
- Inverse Document Frequency: 단어가 제공하는 정보의 양
- DF(t): t가 등장한 document 개수 / N: 총 document 개수
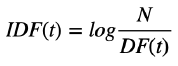
- DF(t): t가 등장한 document 개수 / N: 총 document 개수
- TF + IDF

- BM25
- TF-IDF의 개념을 바탕으로, 문서의 길이까지 고려하여 점수를 매김
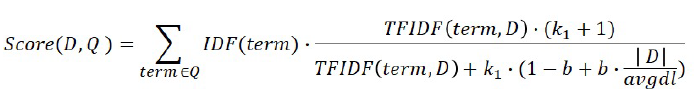
- TF-IDF의 개념을 바탕으로, 문서의 길이까지 고려하여 점수를 매김

함께 자라기