✏️학습 정리
5. Passage Retrieval - Dense Embedding
-
Sparse embedding의 한계
- 차원의 수가 매우 크다 → compressed format으로 극복 가능
- 유사성을 고려하지 못함
-
Dense Embedding
- 더 작은 차원의 고밀도 벡터 (length = 50~1000)
- 각 차원이 특정 term에 대응되지 않음
- 대부분의 요소가 non-zero값
- overview
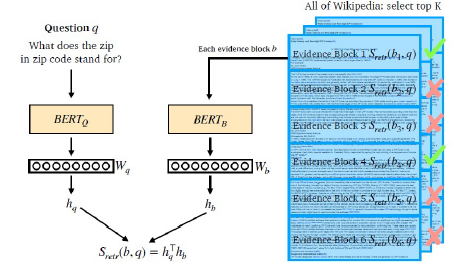
-
Dense Encoder
- 구조
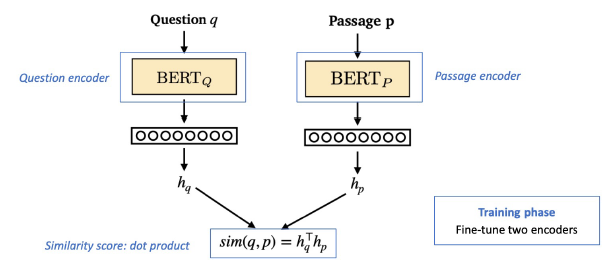
- 학습 목표: 연관된 question과 passage dense embedding 간의 거리를 좁히는 것 (higher similarity)
- 구조
-
Negative Sampling
- 연관된 question과 passage 간의 dense embedding 거리를 좁히는 것 → positive
- 연관 되지 않은 question과 passage간의 embedding 거리는 멀어야 함 → negative
- 뽑는법
- 랜덤
- 좀 더 헷갈리는 negative 샘플들 뽑기 (ex. TF-IDF가 높지만 답을 포함하지 않는 sample)
- objective function
- positive: negative log likelihood (NLL) loss 사용
-
Dense Encoding 개선
- 학습 방법 개선 (DPR)
- 인코더 모델 개선 (BERT보다 큰, 정확한 PLM 모델)
- 데이터 개선 (더 많은 데이터, 전처리, 등..)
6. Passage Retrieval - Scaling Up
-
MIPS (Maximum Inner Product Search)
- 주어진 질문 벡터 q에 대해 Passage 벡터 v들 중 가장 질문과 관련된 벡터를 찾아야함
- 관련성: 내적(inner product)이 가장 큰 것
- 문제: 실제로 검색해야할 데이터는 훨씬 방대 → 모든 문서 임베딩을 볼 수 없다.
-
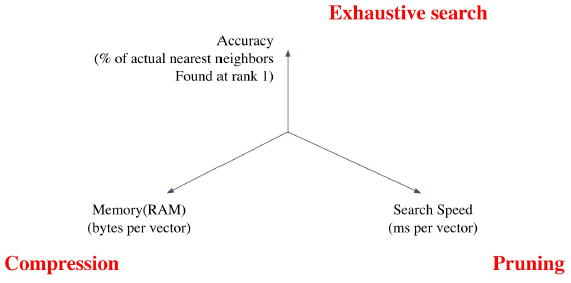
Tradeoffs of similarity search
- Search Speed
- 쿼리 당 유사한 벡터를 k개 찾는데 얼마나 걸리는지?
- Memory Usage
- 벡터를 사용할 때, 어디에서 가져올 것인지?
- Accuracy
-
brute-force 검색 결과와 얼마나 비슷한지?
-
- Search Speed
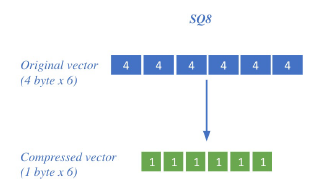
- Compression - Scalar Quantization (SQ)
- 벡터를 압축하여, 하나의 벡터가 적은 용량 차지 (메모리 down, 정보 손실 up)
- 4-byte floating point → 1-byte unsigned integer
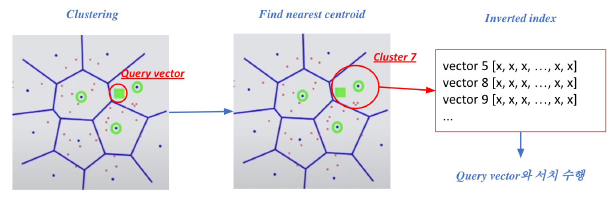
- Pruning - Inverted File (IVF)
- Search space를 줄여 search 속도 개선 (dataset의 subset만 방문)
- clustering + inverted file 활용
- 과정
- 주어진 query vector에 대해 근접한 centroid vector 찾음
- 찾은 cluster의 inverted list 내 vector들에 대해 search 수행
-
FAISS
-
효율적인 similarity search를 위한 라이브러리
-
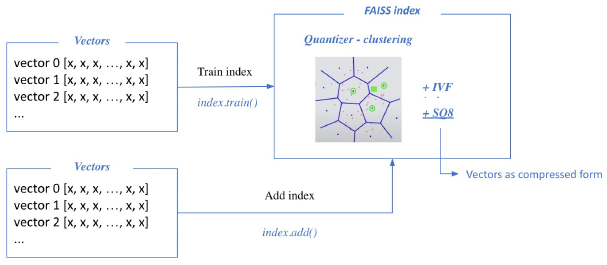
Passage Retrieval with FAISS
-
Train index and map vector
-
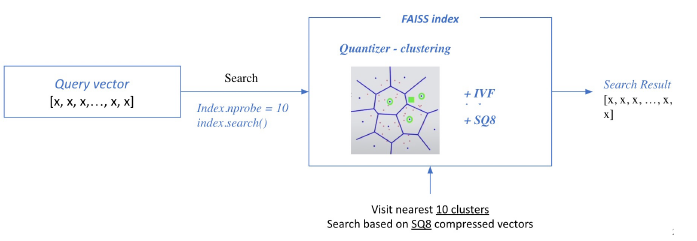
Search based on FAISS index
-
-
7. Linking MRC and Retrieval
- ODQA (Open-domain Question Answering)
- 지문이 따로 주어지지 않음. 방대한 World Knowledge에 기반해서 질의응답
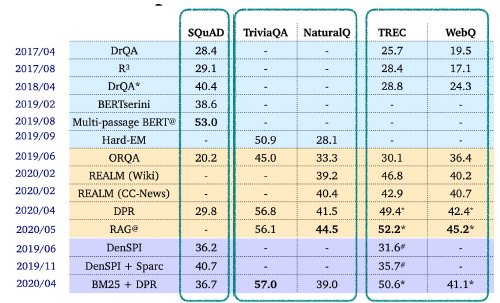
- ODQA Research
-
Retriever - Reader
- Retriever
- 데이터베이스에서 관련있는 문서를 검색
- TF-IDF, Dense...
- Reader
- 검색된 문서에서 질문에 해당하는 답을 찾아냄
- SQuAD와 같은 MRC 데이터셋으로 학습
- Distant supervision 활용 (질문-답변만 있는 데이터셋을 MRC 데이터셋으로 만들기)
- Inference
- Retriever가 질문과 가장 관련있는 top k개 문서 출력
- Reader는 k개 문서를 읽고 답변 예측
- Reader가 예측한 답변 중 가장 score가 높은 것을 최종 답으로 사용
- Retriever
-
Issues & Recent Approaches
- Different Granularity
- 각 Passage의 단위를 문서, 단락 또는 문장으로 정의할지 정해야 함.
- Retriever 단계에서 몇개(top-k)의 문서를 넘길지 정해야 됨
- 문서 → k=5, 단락 → k=29, 문장 → k=78
- Single-passage training vs Multi-passage training
- single: k개의 passage들을 하나씩 reader가 확인
- multi: k개의 passage들을 하나의 passage로 취급하여 reader가 확인
- Importance of each passage
- Retriever 모델에서 추출된 top-k passage들의 retrieval score를 reader 모델에 전달
- Different Granularity

함께 자라기