✏️학습 정리
1. 강의 소개 및 자세
-
수강생에게 바라는 모습
- 큰 그림을 인지하는 사람
- 직접 문제 정의를 하며, 능동적인 자세를 가지는 사람
- 지속적으로 개선하는 사람
-
강의 목표
- AI 엔지니어가 되기 위한 기본 소양 갖추기
- 문제 정의에 대한 고민을 하는 사람
-
추천 학습 방식
- 강의는 1회만(대신 학습 자료로 자주 복습), 흐름과 키워드 위주로
- 외우지 말자! (이해하고 자주 사용하면 자동으로 외워진다.)
- 나만의 언어로 정리해보자!
- 수평 학습 —> 수직 학습
2. 머신러닝 프로젝트 라이프 사이클
머신러닝 프로젝트 Flow
-
문제 정의의 중요성
- 문제 정의: 특정 현상을 파악 → 그 현상에 있는 문제를 정의하는 과정
- 문제가 명확하지 않으면 무엇을 해야할지 결정하기 어렵다! (ex. 저는 사람들을 행복하게 만들고 싶어요)
- 머신러닝, AI, 개발 등 대부분 업무에서 항상 문제 정의가 선행
- How 보다 Why에 집중
- 문제 해결 Flow
- 현상 파악
- 목적, 문제 정의 → 계속 생각하기, 쪼개서 생각하기
- 프로젝트 설계
- Action
- 추가 원인 분석
-
현상 파악
- 어떤 현상이 발견? 현재 상황 파악 필요
- 해당 일에서 어려움은 무엇?
- 해결하면 좋은 것은 무엇?
- 추가적으로 해볼 수 있는 것은?
- 어떤 데이터가 있을까?
- 예시) 음식점 매출이 감소하고 있다. 몇달 연속으로 감소하고 있으며, 전체 손님이 줄어들고 있다.
-
구체적인 문제 정의
- 앞선 현상을 더 구체적으로 명확한 용어로 정리해보기
- 예시
- 처음 방문하는 손님들이 심하게 줄어들고 기존 손님들도 줄고 있다. (처음 손님이 더 줄어들고 있다.)
- 처음 방문하는 손님들의 어려움 확인 (데이터 확인, 인터뷰)
- 그 결과, 메뉴가 너무 다양하고 메뉴 설명이 부족
- 문제 상황: 메뉴가 너무 다양해서 선정하기 어렵다!
- 원인: 메뉴 다양 / 설명 부족
- 당장 진행 할 수 있는 방식부터 사용
- 설명을 늘리는 방식 = 룰 베이스(만약 이런 음식 좋아한다면 이 메뉴 추천) → 당장의 문제 해결 추천 = 알고리즘 개발 → 문제 해결의 또 다른 방법
- 문제 정의는 현상을 계속 쪼개고, 그 문제를 기반으로 어떤 어려움을 겪고 있는지 파악
- 데이터로 할 수 있는 일을 만들어서 진행하되, 간단한 방법부터 점진적인 접근 (시간의 제약을 받고 있기 때문)
- 룰 베이스를 정하고 시작하면 좋다!
- base line 역할
- 병렬로 모델링 후에 룰 베이스 대비 얼마나 좋은지 파악 가능 (기준 역할)
-
프로젝트 설계
- 프로젝트 과정 (현실...)
- 문제 정의
- 최적화할 Metric 선택 (Metric: 평가지표)
- 데이터 수집, 레이블 확인 → 원본 data는 존재, but Metric에 따라 레이블을 다시 지정해야 할 수도...
- 모델 개발
- 모델 예측 결과를 토대로 Error Analysis. (잘못된 레이블이 왜 생기는지 확인)
- 다시 모델 학습
- 더 많은 데이터 수집
- 다시 모델 학습
- 2달 전 테스트 데이터에선 성능이 좋았는데, 어제 데이터엔 성능이 좋지 않음...
- 모델을 다시 학습
- 모델 배포
- 최적화할 Metric이 실제로 잘 동작하지 않아 Metric을 수정
- 다시 시작....ㅠㅠ
- 머신러닝 문제 타당성 확인
- 흥미로운 것보다 비지니스에서 어떤 가치를 줄 수 있는지 고려
- 머신 러닝 문제 → 데이터로부터 어떤 함수를 학습하는 것
- 머신러닝은 모든 문제를 해결하는 만능 도구가 아니다! (해결할 수 있어도 최적이 아닐 수 있다) → 유연한 사고를 갖자!
- 머신러닝이 사용되면 좋은 경우
- 학습할 수 있는 패턴이 있는가?
- 학습을 위한 목적 함수를 만들수 있는가? (loss 정의할 수 있어야함)
- 패턴이 복잡한가? (간단하면 굳이 쓸 필요가 없다.)
- 데이터가 존재하거나 수집할 수 있는가?
- 사람이 반복적으로 실행하는 일인가?
- 머신러닝이 사용되면 좋지 않은 경우
- 비윤리적인 문제 (차별을 암시하는 등..)
- 간단히 해결할 수 있는 문제
- 좋은 데이터를 얻기 어려울 경우 (시작부터 힘들다.., 좋은 학습이 어려움)
- 한번의 예측 오류가 치명적인 결과를 발생할 경우 (택시 요금 예측 등..)
- 시스템이 내리는 모든 결정이 설명 가능해야 하는 경우 (모든걸 설명 못 할 수 있다.)
- 비용 효율적이지 않을 경우 (GPU, 인건비 등..)
- 목표 설정
- Goal: 큰 목적, 최종 목적
- Objective: 목적을 달성하기 위한 세무 단계의 목표 (구체적 목표)
- 목표를 설정하며 데이터 확인 (여러가지 시나리오 고려)
- Label을 가진 데이터가 있는 경우
- 유사 Label을 가진 데이터가 있는 경우 (음악의 경우 재생시간, 건너뛰기 → 선호도 예측)
- Label이 없는 데이터 (직접 레이블링 or 없는 상태에서 학습 방법)
- 데이터가 아예 없는 경우 (수집 방법 고민)
- 데이터셋을 만드는 일은 반복적 (Self Supervised Learning 등을 사용해보기)
- 최적화하고 싶은 목적 함수가 여러가지 있을 경우, 충돌 가능
-
두 loss를 하나의 loss로 결합, 해당 loss를 최소화
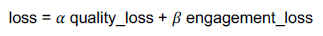
—> 알파, 베타를 조정할 때마다 다시 학습해야됨
-
2개의 모델 (각각의 Loss를 최소화) 사용 (알파, 베타 조정할 때마다 재학습 X)
-
- Baseline
- 모델이 더 좋아졌다고 판단할 수 있는 baseline 필요
- 간단한 모델부터 시작 (점진적으로 개선)
- 프로토타입
- 회사의 동료들에게 모델을 활용할 수 있는 환경 준비
- Voila, Streamlit, Gradio
- Metric Evaluation
- 문제를 해결할 경우 어떤 지표가 좋아질까?를 고민
- 작게는 모델의 성능 피죠(RMSE), 크게는 비지니스 지표
- 지표를 잘 정의해야 기존보다 더 성과를 냈는지 파악 가능
- 프로젝트 과정 (현실...)
-
Action (모델 개발 후 배포 & 모니터링)
- 현재 만든 모델이 어떤 결과를 내는가?
- 잘못 예측하는 부분이 있다면 어떤 부분인가?
- 어떤 부분을 기반으로 예측하는가? 등..
-
추가 원인 분석
- 새롭게 발견된 상황을 파악 → 어떤 방식으로 해결할지 고민
- 앞서 진행한 과정 반복
비지니스 모델
-
비지니스
- 회사에서 중요한 것 = 비지니스
- 비지니스에 대한 이해도가 높을수록 문제 정의를 잘 할 가능성 존재
-
비지니스 모델 파악
- 회사의 비지니스 파악
- 데이터를 활용할 수 있는 부분 파악 (Input)
- 모델을 활용한다고 하면 예측의 결과를 어떻게 활용되는가? (Output)
- 누군가 산업에 대해 정리해둔 Paper가 있는지 찾아보자!
- 예시) awesome mobility machine learning github
3. Linux & Shell Command
-
Linux
- 서버에서 자주 사용하는 OS
- FREE! & 오픈소스
- 안전성, 신뢰성
- 쉘 커맨드, 쉘 스크립트
- CLI(Command Line Interface): Terminal
-
대표적인 Linux 배포판
- Debian
- Ubuntu (초보자들이 쉽게 접근 가능)
- Redhat
- CentOS (Redhat 브랜드와 로고 제거 버전)
-
Linux 사용법
- VirtualBox에 Linux 설치
- Docker로 설치
- WSL 사용 (윈도우)
- Notebook에서 터미널 실행
-
Shell
- 사용자가 문자를 입력해 컴퓨터에 명령할 수 있도록 하는 프로그램
- sh: 최초의 쉘
- bash: Linux 표준 쉘
- zsh: Mac OS 기본 쉘
-
기본 쉘 커맨드
man: 커맨드의 메뉴얼 문서를 보고 싶은 경우mkdir: 폴더 생성ls: 현재 접근한 폴더의 폴더, 파일 확인ls -a: 전체 파일 출력ls -l: 퍼미션, 소유자, 날짜 용량 출력ls -h: 용량을 GB, MB 등으로 표현 (-lh로 많이씀)
pwd: 현재 폴더 경로를 절대 경로로 보여줌cd: 폴더 변경하기, 폴더로 이동echo: 터미널에서 텍스트 출력vi: vim 편집기로 파일 생성- Command Mode (기본 Mode)
- Insert Mode (파일을 수정하는 Mode)
- Last Line Mode (ESC 후 콜론(:)을 누르면 나오는 Mode)
bash: 쉘 스크립트 실행sudo: 관리자 권한으로 실행 (조심해서 사용)cp: 파일 또는 폴더 복사cp test1 test2-r: 디렉토리 복사시 안에 파일 모두 복사cp test1 test2-f: 복사할 때 강제 실행
mv: 파일, 폴더 이동 (이름 바꿀 때도 활용)cat: 특정 파일 내용 출력clear: 터미널 창 청소history: 최근에 입력한 쉘 커맨드 history 출력 (!번호입력시 해당 커맨드 재활용)find: 파일 및 디렉토리 검색export: 환경 변수 설정 (터미널 꺼지면 사라지게 됨)alias: 별칭으로 설정된 것을 볼 수 있음
-
추가 쉘 커맨드
head,tail: 파일의 앞 / 뒤 n행 출력sort: 행 단위 정렬sort -r: 정렬을 내림차순으로 (default: 오름차순)sort -n: Numeric 정렬
uniq: 중복된 행이 연속으로 있는 경우 중복 제거uniq -c: 중복 행의 개수 출력
grep: 파일에 주어진 패턴 목록과 매칭되는 라인 검색grep -i: 대소문자 구분없이 찾기grep -w: 정확히 그 단어만 찾기grep -v: 특정 패턴 제외한 결과 출력grep -E: 정규 표현식 사용- ^단어: 단어로 시작하는 것 찾기
- 단어$: 단어로 끝나는 것 찾기
- . : 하나의 문자 매칭
cut: 파일에서 특정 필드 추출cut -f: 잘라낼 필드 지정cut -d: 필드를 구분하는 구분자 (default: \t)
-
표준 스트림 (Stream)
-
Unix에서 동작하는 프로그램은 커맨스 실행시 3개의 Stream 생성
-
stdin: 0으로 표현, 입력 (커맨드, 비밀번호 등..) -
stdout: 1로 표현, 출력 값 (터미널에 나오는 값) -
strerr: 2로 표현, 디버깅 정보나 에러 출력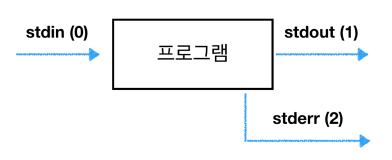
-
-
Redirection & Pipe
- Redirection: 프로그램의 출력(stdout)을 다른 파일이나 스트림으로 전달
>: 덮어쓰기 (Overwrite)>>: 맨 아래에 추가 (Append)
- Pipe: 프로그램의 출력(stdout)을 다른 프로그램의 입력으로 사용하고 싶은 경우
ls | grep “vi”: 현재 폴더에 있는 파일명 중 vi가 들어간 단어를 찾고 싶은 경우
- Redirection: 프로그램의 출력(stdout)을 다른 파일이나 스트림으로 전달
-
서버에서 자주 사용하는 쉘 커맨드
ps: 현재 실행되고 있는 프로세스 출력ps -e: 모든 프로세스ps -f: Full Format으로 자세히 보여줌
curl: Request를 테스트할 수 있는 명령어, 웹 서버 요청 작동 확인 가능 (httpie 등도 있다.)df: 현재 사용 중인 디스크 용량 확인scp: SSH를 이용해 네트워크로 연결된 호스트 간 파일을 주고 받는 명령어scp -r: 재귀적 복사scp -P: ssh 포트 지정scp -i: SSH 설정을 활용해 실행
nohup: 터미널 종료 후에도 계속 작업이 유지하도록 실행 (파일의 Permission이 775여야 함)chmod: 파일의 권한 변경
-
쉘 스크립트
- .sh 파일 (안에 쉘 커맨드 추가)
- bash로 실행 가능
#!/bin/bash: Shebang (이 스크립트를 Bash 쉘로 해석)

함께 자라기