✏️학습 정리
1. Part 1 - Bag of Words & Word Embedding
-
NLP
- 목적: 딥러닝을 이용하여 인간의 언어를 이해하거나 생성하는 것
- 응용예시: 언어 모델, 기계 번역, 질의응답, 문서 분류, 대화 시스템(챗봇)
- 단계별 processing
- low-level (토큰화, stemming = 어근 추출)
- word, phrase level (NER, POS, noun-Phrase chunking, dependency parsing, coreference resolution)
- sentence level (Sentiment analysis, machine translation)
- Multi-sentence level (Entailment prediction, question answering, dialog systems, summarization)
- 발전 과정
- word embedding
- RNN-model (LSTM, GRU ← LSTM 단순화, 계산 속도 UP)
- Transformer model (attention)
- 기계 번역 위주로 발전
- 다양한 NLP task에 따라 모델 custom
- self-supervised training (추가적인 label이 필요없는..)
- transfer learning
- 현재, GPU 자원의 한계로 NLP 연구가 어려워졌다! (매우 큰 train이 필요해서..)
-
Bag of Words
-
간단한 생성 예시
- unique한 단어들을 포함한 vocabulary (사전)을 생성한다.
- unique한 단어들을 one-hot vector로 encoding한다.
-
문제점?
- 단어의 의미와 관계없이 모두 동일한 관계 (단어간의 내적, 유사도, cosine 유사도가 0이다.)
-
Naive Bayes Classifier ( for 문서 분류)
-
Bayes’ Rule을 적용 (문서와 class)
-
문서 d, class c

-
문서 d가 단어 w들로 이루어져 있을 때
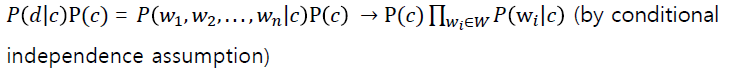
-
-
-
Word Embedding (Word2Vec, Glove)
- Word Embedding??
- 단어를 vector로 변환
- 비슷한 단어들은 비슷한 vector로 표현
- Word2Vec
-
근접한 단어들의 vector를 train하는 방법
-
가정: 비슷한 context에 있는 단어들은 의미도 비슷할 것이다.
-
분포 가설 (단어 cat은 확률 분포 p(w|cat)에 의해 의미가 정해진다.
-
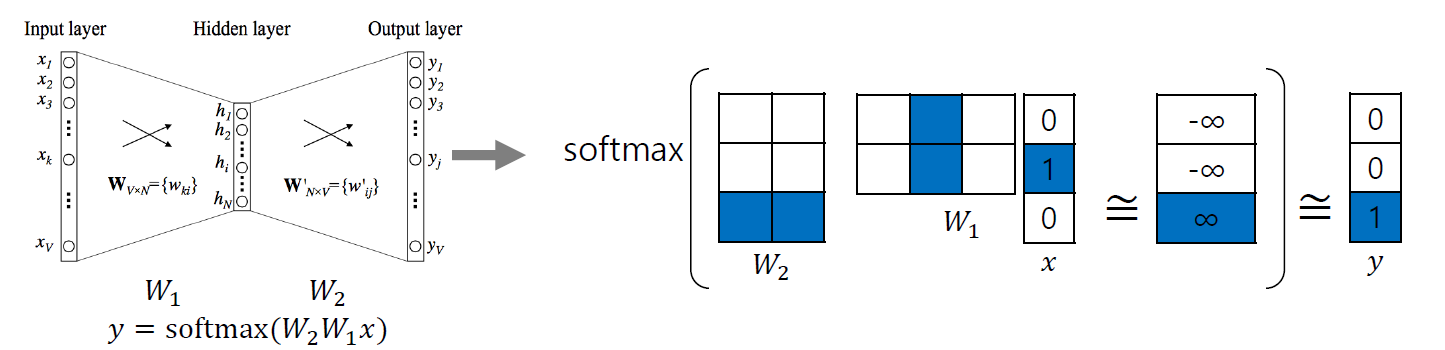
구조
-
핵심: 입력 단어의 W1상에서의 vector와 출력 단어의 W2상에서의 vector간의 내적에 기반한 유사도가 최대한 커지도록 한다. 다른 단어들과의 유사도는 최대한 작게 만든다.
-
예시
- Sentence: I study math 이고 슬라이딩이 3일 때
- (x, y) =(중심 단어, 근처 단어) : (I, study) / (study, I), (study, math) / (math, study)
-
특성
-
단어간의 관계가 vector간의 관계로 나타난다. (vector 공간상에서)

-
유추 가능 (단어간의 +,- 가능)
-
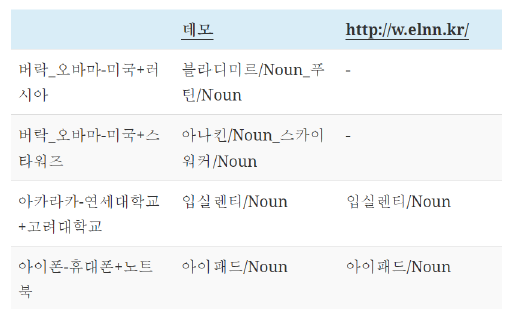
Intrusion Detection: 다른 의미를 가진 단어 선택
-
-
응용 (단어 유사도, 기계 번역, POS, NER, 감정분석...등)
-
- GloVe
-
co-occurrent matrix (동시출현)을 계산한다.
-
새로운 형태의 loss 사용
-
u: 입력 word vector, v: 출력 word vector, P: 두 단어가 한 윈도우에서 몇번 등장하는가
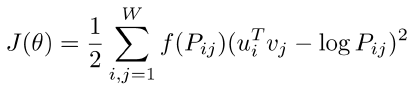
-
빠른 train 가능
-
작은 말뭉치(데이터)로도 잘 작동
-
예시 (비교급들의 vector 관계)
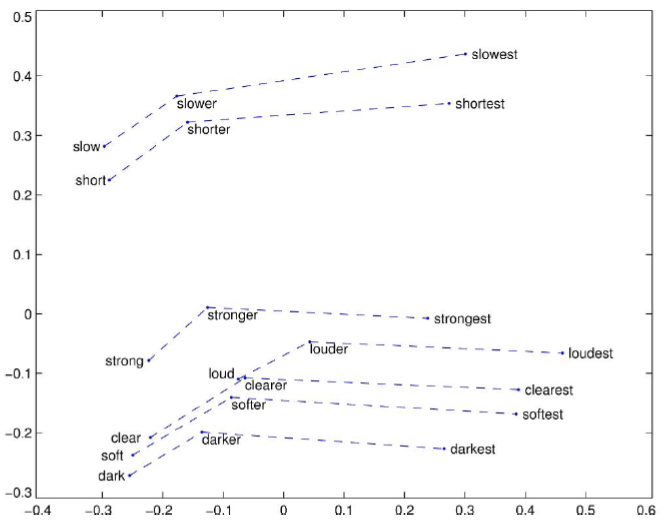
-
- Word Embedding??
📒공부하며 찾아본 것
-
NER (Named Entity Recognition)
- 문자열을 입력으로 받아 단어 별로 해당되는 태그를 내뱉게 하는 multi-class 분류 작업
- 개체명 인식 (NE를 인식)
- NE
- 일반적인 개체명 (인물, 장소 등...)
- 특정 분야 개체명 (전문 분야의 용어)
- 기계 번역 품질 향상, 사용자에게 맞춤형 번역 제공
- 개체명이 일반적인 명사로 잘못 해석되면 문장의 이해 자체가 어려워진다.
- 참고
-
POS(Part of Speech) tagging
-
문장 내 단어들의 품사를 식별하여 태그를 붙여주는 것
-
예시
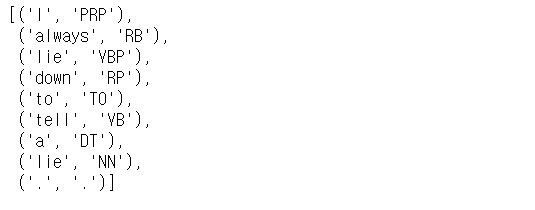
-
- Noun-Phrase chunking
-
chunking: 여러 개의 품사로 구(phrase)를 만드는 것
-
chunk: 만들어진 구
-
예시

ref. https://ichi.pro/ko/nlpeseo-pos-taeging-mich-cheongking-hagseub-147300065323211
-
-
Dependency Parsing
-
Parsing: 각 문장의 문법적인 구성 또는 구문을 분석하는 과정
-
Consitituency parsing: 문장의 구성요소를 파악하여 구조를 분석하는 방법

-
Dependency Parsing: 단어간 의존 관계를 파악하여 구조를 분석하는 방법
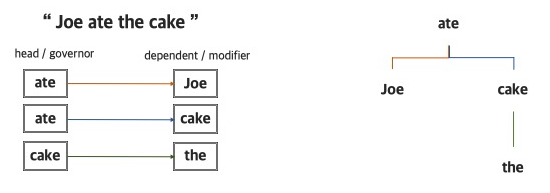
-
ref. https://velog.io/@tobigs-text1314/CS224n-Lecture-5-Linguistic-Structure-Dependency-Parsing
-
-
Coreference Resolution (상호참조해결)
-
임의의 개체(entity)를 표현하는 다양한 단어(멘션)들을 찾아 연결해주는 자연어처리
-
예시

-
-
Entailment prediction
- 두 문장이 주어졌을 때, 첫 번째 문장과 두 번째 문장의 관계를 예측 (수반, 반대, 중립)
-
Self-Supervised training (자기지도 학습)
- label이 없는 untagged data를 기반으로 한 학습 (자기 스스로 학습 데이터에 대한 분류를 수행)
-
조건부독립 (conditional independence assumption)
- 세 개의 변수 a, b, c가 있을 때, a와 b가 독립적이라면 다음 식이 성립
p(a|b,c) = p(a|c)
p(a,b|c) = p(a|b,c)p(b|c) = p(a|c)p(b|c) - 증명: https://en.wikipedia.org/wiki/Conditional_independence
- 세 개의 변수 a, b, c가 있을 때, a와 b가 독립적이라면 다음 식이 성립
