✏️학습 정리
2. Part 2 - RNN, LSTM, and GRU
-
RNN
-
구조
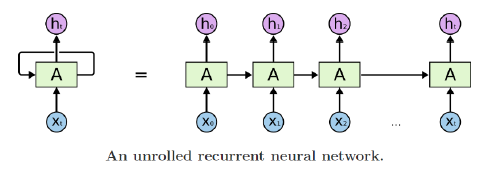
-
서로 다른 time step에서 들어온 데이터를 처리할 때 동일한 parameter 사용
-
hidden state 계산
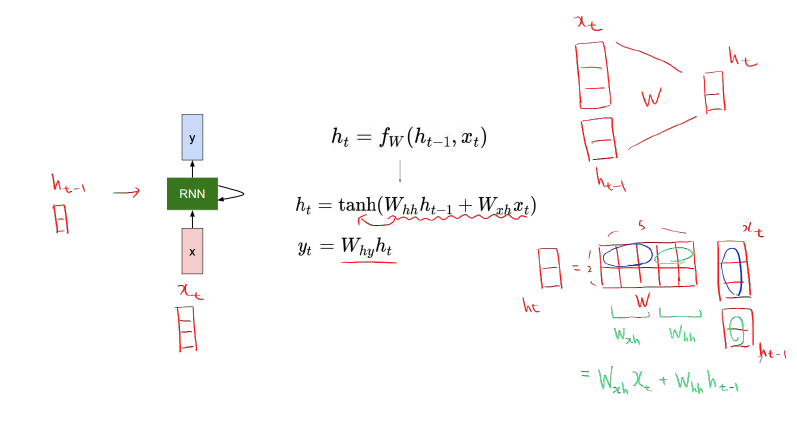
-
RNN Type
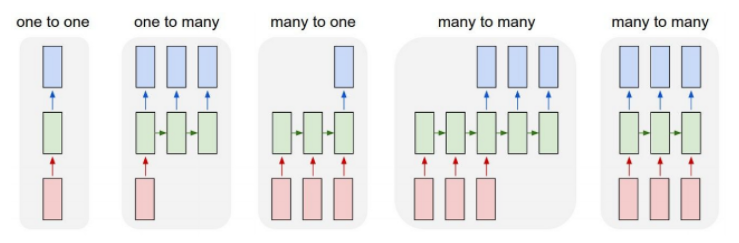
- one-one: 표준 NN
- one-many: Image Captioning
- many-one: Sentiment Classification
- many-many: Machine Translation / Video classfication (frame level), POS tagging
-
-
Char level Language Model
-
기본적으로 다음 단어 예측
-
예시 구조 (’hello’ sequence 학습)

-
-
BPTT (Backpropagation through time)
-
RNN을 학습시키는 방법

-
Truncated BPTT
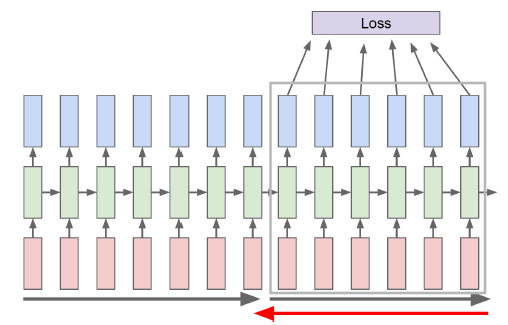
-
Vanishing / Exploding Gradient Problem
- 역전파동안 각 time step에서 같은 matrix를 곱하다보면 gradient가 폭발하거나 소멸한다.
-
-
LSTM (Long Short-Term Memory)
-
핵심: 변형없이 cell state 정보를 그대로 전달 (long-term dependency 문제 해결)
-
long-term dependency: hidden state의 과거 정보가 마지막까지 전달되지 못하는 현상
-
구조
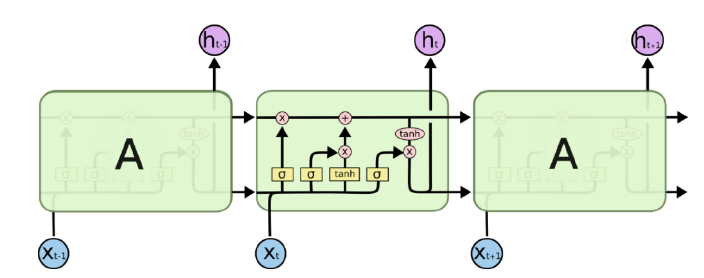
-
Forget Gate: 이전 cell state의 일부만 반영
-
Input Gate: 추가된 정보를 일부만 반영
-
Output Gate: 다음 time step에 hidden state를 넘겨준다.
-
-
GRU (Gated Recurrent Unit)
- LSTM 간략화
- cell state가 없음
- hidden state가 LSTM의 cell state와 비슷한 역할을 함
-
Backpropagation in LSTM, GRU
-
덧셈 연산으로 gradient vanishing & exploding 방지

-
🗣️피어세션
-
Logit
- 딥러닝에서는 확률화되지 않은 예측 결과
- 보통 분류 문제에서 softmax 함수의 입력으로 사용된다.
-
Word2Vec, GloVe 단점
-
Word2Vec
- 장점
- 직관적인 이론으로 워드 임베딩 입문에 제격
- 전처리 작업이 간단하여 메모리를 적게 먹는다
- 단어 간 관계성을 파악할 수 있다(동의어 등)
- 단점
- 단어 간 관계성 설정에 확실한 이론적 뒷받침이 미비하다
- (단어 간 관계성 설정에 용이한)데이터가 충분해야 학습이 잘된다.
- 문장의 길이가 길수록 메모리 공간 활용이 효율적이지 못하다. - 원핫 인코딩을 사용하는 경우
- vocabulary 사이즈가 너무 크기 때문에, softmax를 사용할 경우 모델이 학습하기 어렵다
- 장점
-
GloVe
- 장점
- 단어 간 관계성에 집중하는 형태의 손실함수를 사용하여, 단어분석 Task에서 Word2vec보다 더 빠른 성능을 보인다.
- co-occurrent로 워드 임베딩을 계산하기 때문에 동시에 등장한 횟수를 미리 계산해 중복되는 계산을 줄여 속도가 빠르다.
- 단점
- co-occurrence matrix 기반의 vocabulary 셋은 메모리를 무지막지하게 크게 먹는다, 또한 이 matrix 관련 하이퍼파라미터를 조작해야 할 경우, matrix 자체를 다시 구성해야 하는 번거로움이 있다.
- co-occurrence matrix의 경우 매우 sparse한 matrix가 되는데 이를 해결하고자 SVD와 같은 차원축소 기법을 사용한다. 그렇기 때문에 새로운 단어를 추가하고자 할때는 행렬을 새로 구성해야 한다는 단점이 생긴다고 한다.
- co-occurrence matrix 기반의 vocabulary 셋은 메모리를 무지막지하게 크게 먹는다, 또한 이 matrix 관련 하이퍼파라미터를 조작해야 할 경우, matrix 자체를 다시 구성해야 하는 번거로움이 있다.
- 장점
-
둘 다 해결하기 어려운 문제
- 사전(vocabulary)에 등록되지 않은 단어를 표현하는 방식을 학습하기 어렵다.
- 반의어를 관계적으로 분리하려는 문제에 취약 → 감정분석이 어렵다.
-

함께 자라기