✏️학습 정리
Part 4 - Transformer
-
Transformer
- Attention is all you need 논문에서 처음 등장
- 기존 RNN의 long term dependency를 해결
-
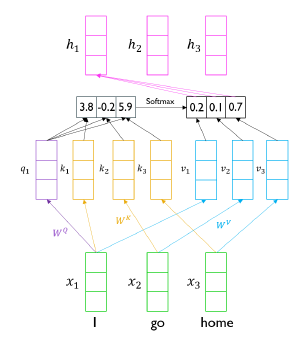
Scaled Dot-Product Attention
-
input: query, key, value
-
output: weighted sum of values
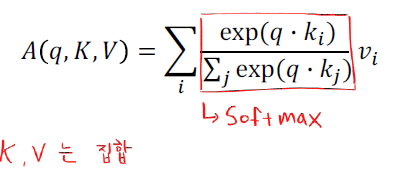
-
Q도 집합으로 한번에 계산 가능
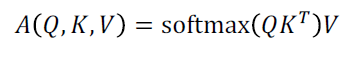
-
실제 transformer 구현 상으론 동일한 shape로 mapping된 Q, K, V가 사용되어 각 matrix의 shape는 모두 동일
-
Scaling
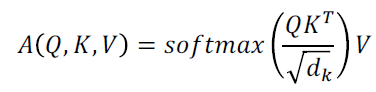
-
Why Scaling??
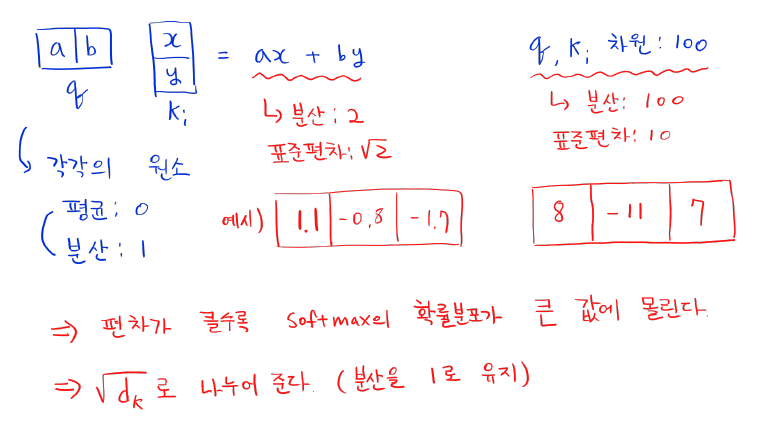
-
- Multi-Head Attention
-
Scaled Dot-Product Attention을 여러번 수행 (병렬적으로)
-
i : 버전 (몇번째 헤드)

-
output의 shape은 input shape과 같게 만들어준다.
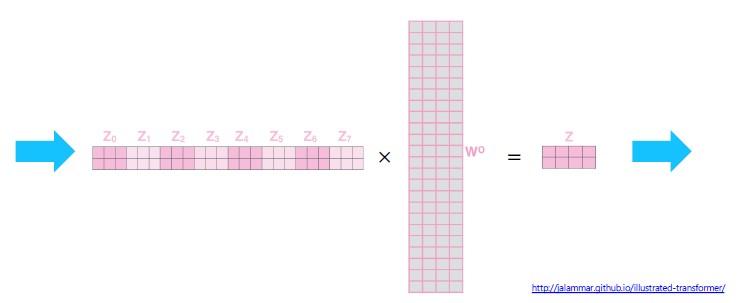
-
- Layer type별 성능 비교
-
n: sequence 길이
-
d: representation의 차원 (hyper parameter)
-
k: convolution kerner size
-
r: neighborhood in restricted self-attention

-
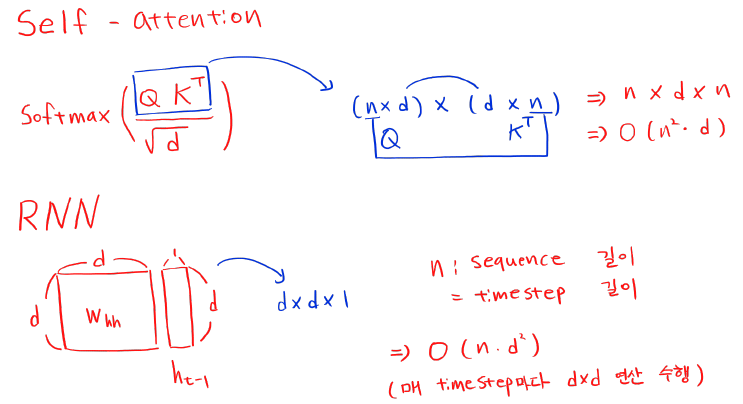
간단한 계산 과정 (self-attention, RNN)
-
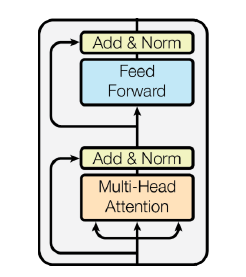
- Transformer Block
-
Base 구조
-
Add (Residual connection): 깊은 NN 만들 때 gradient vanishing 해결
-
Norm
-
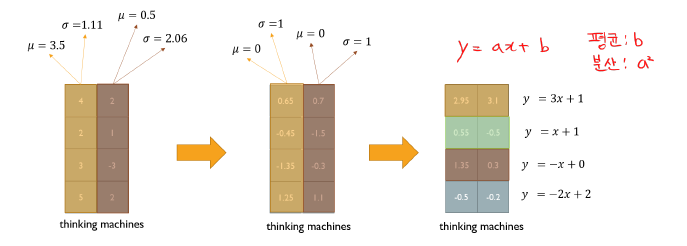
주어진 다수의 sample들에 대해서 그 값들의 평균을 0, 분산을 1로 만들어준 후, 우리가 원하는 평균과 분산을 주입할 수 있도록 하는 선형 변환
-
Layer Normalization 사용 (학습 안정화, 최정 성능 개선)
-
-
-
Positional Encoding
- sequence 위치 정보 추가
- why?
- 위치 정보 없을 시 순서와 관계없이 값이 동일하게 나온다.
-
Decoder

- query: 이전 decoder layer
- key, value: encoder의 output
-
Masked Self-Attention
- 기존 방식

- 토큰의 출력으로 ‘나는’이 나온 후에 input으로 넣어야하는데 이미 ‘나는’, ‘집에’도 input으로 사용 (cheating)
- Masked
-
attention을 모든 data로 진행한 후 보지 말아야하는 값들을 0으로 후처리
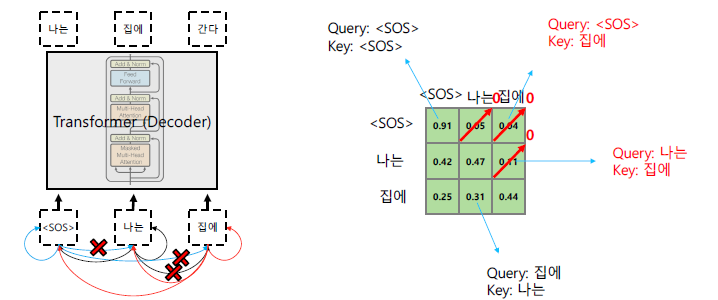
-
Row 별로 합이 1이 되도록 Normalize 실행
-
- 기존 방식
🗣️피어세션
- Wandb 그룹 설정
- Academic 아이디로 사용시 시간 무제한
