📘기본 과제
1. Data Preprocessing (Tokenization)
-
Tokenization (토큰화)
- 주어진 입력 데이터를 자연어처리 모델이 인식할 수 있는 단위로 변환해주는 방법
- 단어 단위 토큰화
- “I have a meal” → [’I’, ‘have’, ‘a’, ‘meal’]
- Vocabulary
- 컴퓨터가 인식할 수 있게 숫자 형식의 id로 매핑
- [’I’, ‘have’, ‘a’, ‘meal’] → [192, 39, 7, 456]
- encoding
- 문장 → 토큰화 → id
- decoding
- id → 토큰 → 문장
-
Spacy
spacy.load(): 원하는 언어 모델 loadtoken.text: 토큰화된 단어의 원형token.lemma_: 토큰화된 단어의 어근token.pos_: 토큰화된 단어의 품사spacy.lang.en.stop_words.STOP_WORDS: 불용어 (자주 등장하지만 큰 의미가 없는 단어)
-
Konlpy
- 형태소 분석기
- 한국어에서 단어는 공백을 기준으로 정의 X
- 체언 뒤에 조사가 붙는 것이 대표적인 특징이며 의미 단위가 구분되고 자립성이 있기 때문에 조사는 단어
- “나는 밥을 먹는다” → [’나’, ‘는’, ‘밥’, ‘을’, ‘먹는다’]
-
코드(개인 확인용)
2. RNN-based Language Model
-
RNN Model
-
Embedding, RNN module, Projection을 포함
-
아키텍처
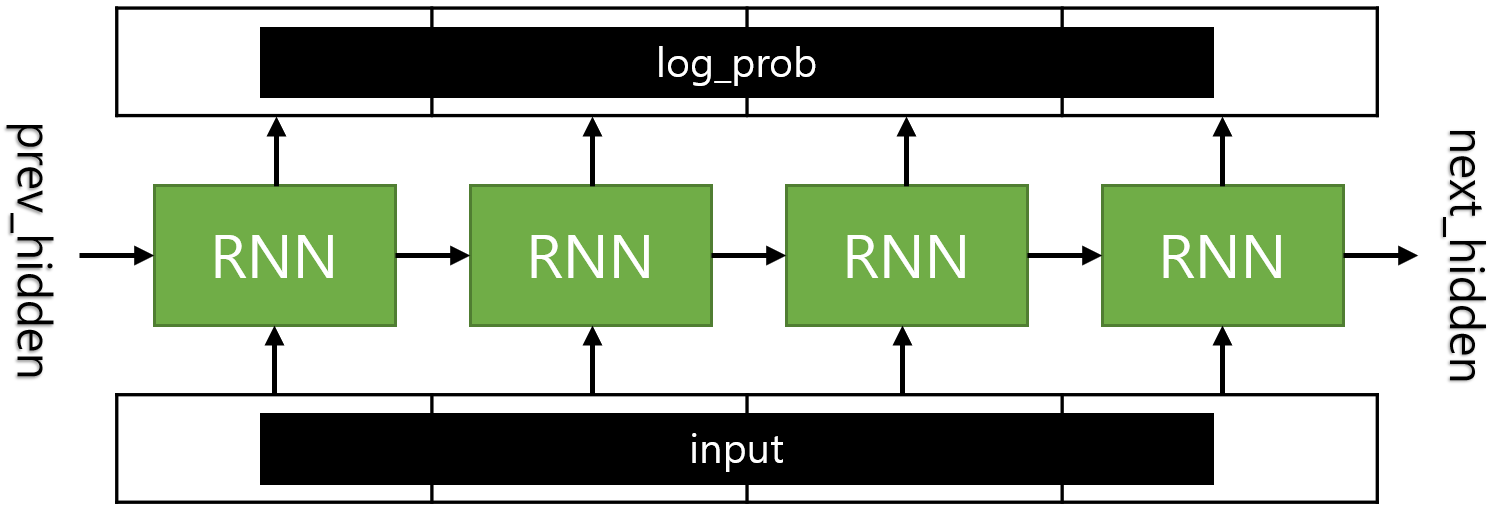
-
BPTT
- 한번에 sequence_length만큼에 대해서만 역전파를 수행해서 전체 Sequence를 학습시키는 방법
-
loss 함수
- NLL 함수 (negative log likelihood)
- https://pytorch.org/docs/stable/generated/torch.nn.NLLLoss.html
-
clip_grad_norm 사용
- 기울기 폭주 (gradient exploding) 방지
-
-
코드(개인 확인용)
🗣️피어세션
- RNN/LSTM/GRU 기반의 Language Model에서 초반 time step의 정보를 전달하기 어려운 점을 완화할 수 있는 방법
-
attention

-
- 동료 캠퍼분의 Fine-tune BERT for Extractive Summarization 논문 리뷰

함께 자라기