✏️학습 정리
Part 5. Self-supervised Pre-training Models
-
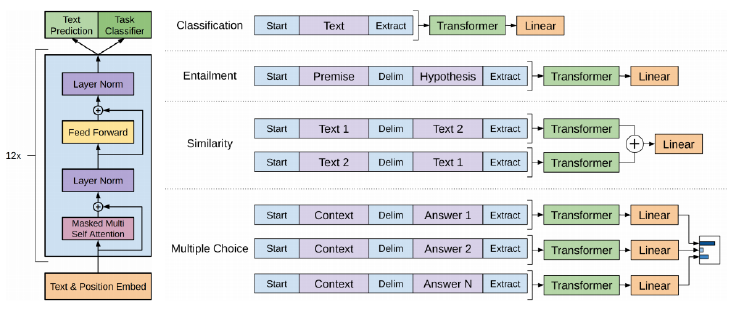
GPT-1 (Open AI)
-
자연어 처리의 다양한 task들을 동시에 처리할 수 있는 통합된 Model
-
task마다 다른 special token을 사용
-
transfer learning 시, Linear 부분을 사용자에게 맞게 custom 가능 (문서 분류 → softmax layer 추가)
-
pre-trained된 transformer 부분은 그대로 사용 or Learning rate 작게 해서 사용
-
대규모 data로 학습된 GPT-1 모델을 우리가 해결해야할 task에 사용
- 우리가 가진 data가 적어도 준수한 결과가 나온다! → 우리 data로만 학습한 모델보다
-
-
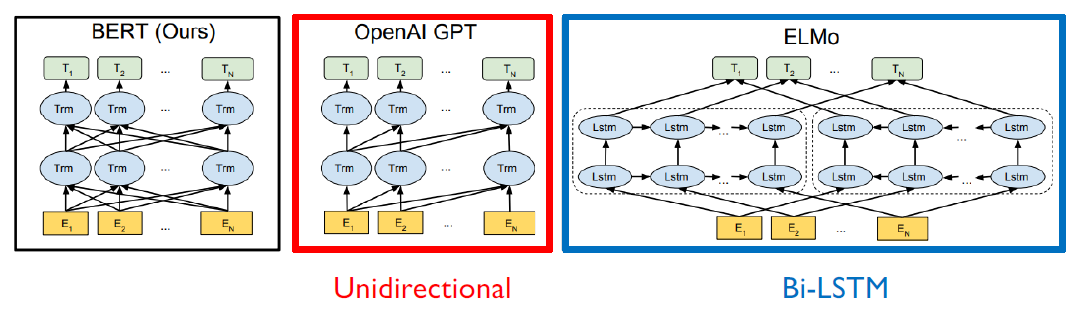
BERT
-
ELMo → GPT → BERT 로 발전
-
MLM (Masked Language Model)
-
input token을 특정 비율(hyper parameter)로 masked token으로 바꾼다.
-
논문에서는 15%
-
문제점: 실제 task에서는 mask token X, 그래서 다음과 같이 변화를 줌

-
-
NSP (Next Sentence Prediction)
-
input 문장 A, B가 있을 때, B가 A의 next 문장인지 예측
-
[CLS] : 문장의 분류, 다중 문장 task 일 때
-
[SEP] : 문장의 끝

-
-
Summary

- Positional Embedding
- 학습에 의해 최적화된 값을 사용
- Segmentation Embedding
- 문장 level에서의 positional embedding
- 다중 문장일 경우 문장을 좀 더 구분해줄 필요가 있다.
- Positional Embedding
-
-
다양한 NLP Test
- GLUE Benchmark

- MRC (Machine Reading Comprehension, 질의응답)
- BERT: SQuAD 1.1 (글에서 정답 찾기), SQuAD 2.0 (no answer data 추가), On SWAG (다중 문장, 다음 문장 예측)
- GLUE Benchmark

함께 자라기