✏️학습 정리
Part 5. Self-supervised Pre-training Models
-
GPT-2
- 동기: 다양한 NLP task들이 질의응답 (자연어 생성 output을 가지는) task로 통합할 수 있다.
- Reddit에서 최소 3 karma인 데이터만 scrap하여 사용 (good quality)
- Preprocess (BPE, Minimal fragmentation)
- Model (기존 GPT-1 구조와 유사, layer가 깊어질수록 layer의 index에 비례해서 초기화해주는 값(weight)을 더 작게 만들어줌)
-
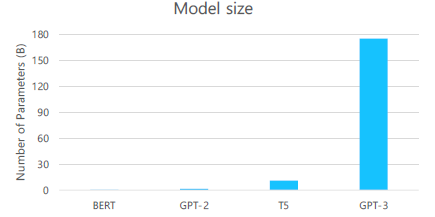
GPT-3
-
모델 size를 매우 크게 만듦
-
96 Attention layer, 3.2M Batch size
-
Few-Shot Learner (input에 한번에 넣는다)

→ fine-tuning 없이 pattern을 하나의 seq로 주었을 때 성능이 좋아지는 것을 확인할 수 있다.
-
-
ALBERT (A Lite BERT)
-
Factorized Embedding Parameterization

-
Cross-Layer Parameter Sharing
- FFN parameter 공유
- attention parameter 공유
- 둘다 공유 (제일 성능이 좋다.)
-
Sentence Order Prediction (좀 더 어려운 학습)
- NSP는 BERT에게 너무 쉬운 task
-
-
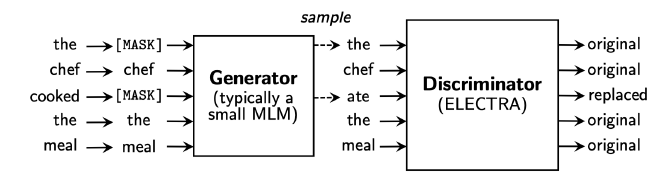
ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately)
-
token이 replace되었는지 detect하는 모델
-
Generator: BERT 등..
-
-
Light-weight Model (모델 경량화)
- DistillBERT (2019)
- 선생 모델, 학생 모델 존재
- 학생 모델: 선생 모델 결과를 gt로 사용
- Tiny BERT (2020)
- 학생 모델: 선생 모델의 결과뿐만 아니라 parameter, hidden state도 유사해지도록 학습
- DistillBERT (2019)
-
Knowledge Graph(외부지식 표현) into LM
- ERNIE
- KagNET
🗣️피어세션
- BERT의 Masked Language Model의 단점
- 논문 참고: https://arxiv.org/pdf/1906.08237.pdf
- 사전 학습과 실제 fine-tuning에 사용하는 데이터 간 discrepancy가 존재한다.
- 예측된 단어들은 모델의 joint probability를 만들어낼 때 사용되지 못한다.
- 사람이 학습할 때에는 외부 피드백이 존재한다. 하지만 BERT는 self-supervised model로 스스로 피드백을 만들어내기 때문에 그런 부분에서 차이가 존재한다.

함께 자라기