📘기본 과제
3. Subword-level Language Model
-
서브워드 (Subword)
- 하나의 단어를 여러개의 단위로 분리했을 때 하나의 단위
- subword → sub + word / su +bword ... (각각이 subword)
-
서브워드 토큰화 (Subword tokenization)
- 서브워드 단위로 토큰화
- "나는 밥을 먹는다" -> ['나', '는', '밥', '을', '먹', '는다']
- "나는 밥을 먹는다" -> ['나', '는', '밥', '을', '먹는', '다'] ...
- 왜 필요??
- 단어단위 임베딩을 사용하는 경우 학습에 사용되는 말뭉치의 크기가 커질수록 등장하는 단어가 더더욱 많아져 임베딩의 매개변수는 더 커지게 되고 전체 매개변수 대비 단어 임베딩이 차지하는 비중이 매우 높아진다. → (서브워드 토큰화 각광)
- 학습 데이터에서 등장하지 않은 단어는 모두 unknown 토큰으로 처리된다. 처음 보는 단어를 모두 unknown 토큰으로 넣게 되면 모델의 성능이 저하될 수 있다. 하지만, 서브워드 단위로 토큰화한다면 가장 작은 문자 단위로 토큰화가 가능하기 때문에 out of vocabulary(oov) 문제가 발생하지 않는다.
-
Byte Pair Encoding (BPE)
- 대표적인 서브워드 토큰화 방법
- 논문
-
Transformers 라이브러리를 활용한 서브워드 토큰화
- Transformers 라이브러리는 다양한 Transformer 구현체를 제공하는 라이브러리이다. 모델외에도 토큰화기를 지원하는데, 이미 학습된 서브워드 토큰화기 역시 쉽게 불러올 수 있다.
from transformers import BertTokenizerFast- Huggingface tokenizers
4. 번역 모델 전처리
- 문장 전처리
-
NLP 모델에 자연어 정보를 전달하기 위해서는 적절한 현태로의 전처리 필요
-
번역 모델의 경우
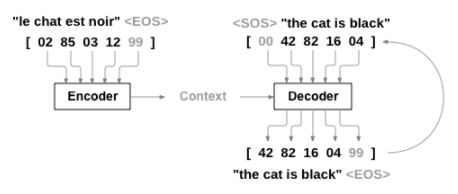
-
- Collating
-
문장들을 빠르게 처리하기 위해 병렬화 필요 → 배치화
-
다양한 길이의 문장을 배치화하기 위해 배치 내의 최대 길이 문장을 기준으로 문장에 패딩을 넣는 과정 필요
-
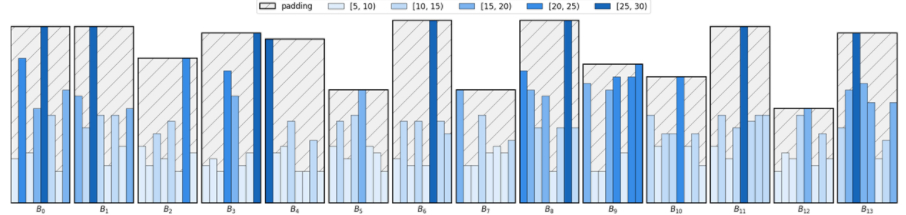
- Bucketing
-
주어진 문장의 길이에 따라 데이터를 그룹화하여 패딩을 적용하는 기법
-
bucketing을 사용하지 않을 경우 위 사진과 같이 배치에 패드 토큰 개수가 늘어나 학습이 오래 걸린다.
-
아래 그림과 같이 길이에 따라 그룹화하여 패딩을 적용하면 학습을 효율적으로 가능

-
🗣️피어세션
- 동료 캠퍼 Transformer 논문 발표

함께 자라기