📘 과제 1
-
Pytorch 공식문서
- 라이브러리의 모든 세부 정보가 담겨있는 곳으로 Custom 모델을 만들 때 꼭 필요한 정보들이 다 있다!
- https://pytorch.org/docs/stable/index.html
-
인덱싱
- torch.index_select (input, dim, index)
- torch.gather (input, dim, index)
-
nn Linear Layers
- nn.Linear: linear transformation 수행
- nn.LazyLinear: 출력 크기만 지정, 입력 크기는 첫 forward 진행시 자동으로 확인하여 지정
- nn.Identity: 입력과 출력이 동일하게 나옴
-
nn.Module
- Container
- nn.Sequential: 모듈들을 하나로 묶어 순차적으로 실행시키고 싶을 때
- nn.ModuleList: 묶어놓은 모듈들을 원하는 것만 쓰고 싶을 때
- nn.ModuleDict: 리스트에 담긴 모듈의 크기가 정말 커지면 인덱싱으로 찾기 어려워지므로 dict 형태로 저장
- 기존 리스트나 dict 사용은 안될까??
- 기존 데이터형들은 nn.Module의 submodule로 인식을 하지 못해 등록이 안된다.
- Parameter
- Tensor도 있는데 왜 쓸까??
- 기능적으로는 동일하다. 하지만 Parameter로 지정하지 않으면 back propagation에서 gradient 값을 업데이트 해줄 때 업데이트 되지 않고, 모델을 저장할 때도 철저히 무시된다!
- Tensor도 있는데 왜 쓸까??
- Buffer
- parameter로 지정하지 않아서 값이 업데이트 되지 않는다 해도 저장하고 싶은 tensor는 buffer로 저장
- Container
-
hook
- custom 코드를 중간에 실행시킬 수 있도록 만들어놓은 인터페이스
- 프로그램의 실행 로직을 분석할 때 사용
- 프로그램에 추가적인 기능을 제공하고 싶을 때 사용
-
Pytorch hook
- Tensor에 적용하는 hook
- register_hook으로 추가
- Module에 적용하는 hook
- register_***hook으로 등록
- Module hook 종류
- forward_pre_hook
- forward_hook
- backward_hook (거의 안씀)
- full_backward_hook
- state_dict_hooks (load_state_dict 함수가 내부적으로 사용)
- Tensor에 적용하는 hook
-
apply
- 적용할 함수를 입력으로 받고, 모델의 모든 sub 모듈에 적용시킨다.
- 일반적으로 가중치 초기화에 많이 사용됨 (parameter로 지정한 tensor의 값을 원하는 값으로 지정??)
📘 과제 2
-
Dataset
- torch.utils.data의 Dataset 클래스를 상속
- 보통 init(초기화), len(최대 element 수), getitem(idx번째 데이터 반환) 메서드로 구성
-
DataLoader
- 모델 학습을 위해서 데이터를 미니 배치 단위로 제공해주는 역할
- dataset: 생성한 Dataset 인스턴스
- batch_size: 배치 사이즈
- shuffle: 데이터를 섞어서 사용하겠는지 설정
- sampler, batch_sampler: index를 컨트롤하는 방법(shuffle=False)
- SequentialSampler : 항상 같은 순서
- RandomSampler : 랜덤, replacemetn 여부 선택 가능, 개수 선택 가능
- SubsetRandomSampler : 랜덤 리스트, 위와 두 조건 불가능
- WeigthRandomSampler : 가중치에 따른 확률
- BatchSampler : batch단위로 sampling 가능
- DistributedSampler : 분산처리 (torch.nn.parallel.DistributedDataParallel과 함께 사용)
- num_workers: 데이터를 불러올 때 사용하는 서브 프로세스 개수
-
무조건 높다고 좋은것이 아니다. (CPU에 병목 생길 수 있음)
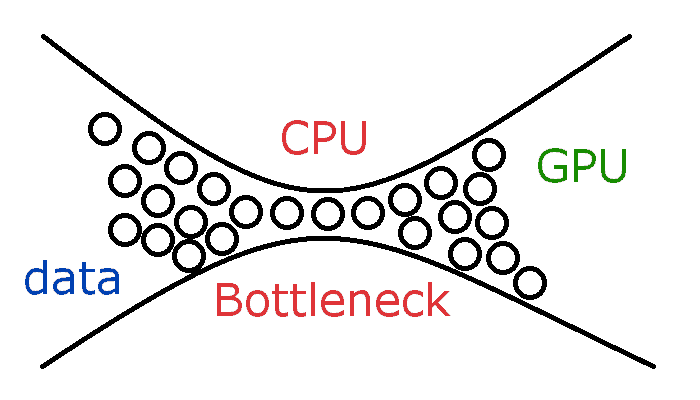
-
- collate_fn: 데이터셋에서 sample list를 batch 단위로 바꾸기 위해 필요한 기능입니다. 데이터 사이즈 맞추기 위해 많이 사용
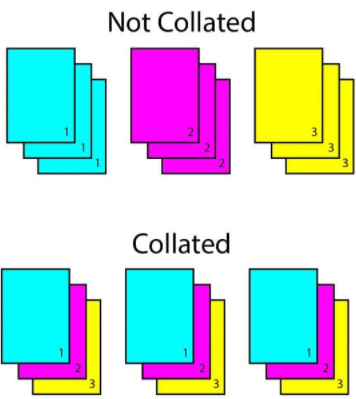 ref. https://www.coastalcreative.com/wp-content/uploads/2019/10/collated-not-collated-543x600.jpg
ref. https://www.coastalcreative.com/wp-content/uploads/2019/10/collated-not-collated-543x600.jpg
{kind=link}
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)-
torchvision의 transform 함수
- transforms.Resize
- 이미지 사이즈 변환
- transforms.RandomCrop
- 이미지를 임의의 위치에서 자릅니다.
- transforms.RandomRotation
- 이미지를 임의의 각도만큼 회전
- transforms.RandomHorizontalFlip or RandomVerticalFlip
- 이미지를 입력된 확률만큼 상하 or 좌우 반전
- transforms.Resize
-
Pytorch Dataset
- MNIST (torchvision)
- AG_NEWS (torchtext)

함께 자라기