
재귀 알고리즘을 마스터하고 싶어서 릿코드 recursion 문제를 풀려고 하는데 연결 리스트 개념이 등장했다. 문제 제목들만 봐도 linked list가 많이 보였다. 알고리즘을 나름 열심히 풀던 2년 전에는 배열과 연결리스트의 차이를 알았는데 하나도 기억나지 않아서 빠르게 정리하고 넘어가려고 한다.
Linked List
배열처럼 순서에 따라 다수의 데이터를 저장한다. 그러나 큰 차이점이 있다.
배열은 각 데이터 요소들의 위치가 지정된다. 인덱스가 부여된다.
반면 연결리스트들은 다음 데이터 요소를 가리키는 인덱스 없이 그냥 다수의 데이터 요소들로 구성된다. 마치 객차들이 연속으로 연결되어 있는 기차와 같다고 보면 된다.
각각의 요소(element)를 노드라고 부른다. 각 노드는 데이터와 다음 노드를 가리키는 포인터를 가지고 있다. 더 이상 다음 노드가 없을 경우 아무것도 없음을 의미하는 null을 저장한다.
- Head : 연결리스트의 시작 노드
- Tail : 연결리스트의 마지막 노드
- length : 연결리스트의 길이
따라서 연결 리스트는 단지 다음 노드들을 가리키고 있는 수 많은 노드들이라고 보면 된다.
배열은 엘레베이터, 연결리스트는 계단같은 느낌이다.
Singly Linked List
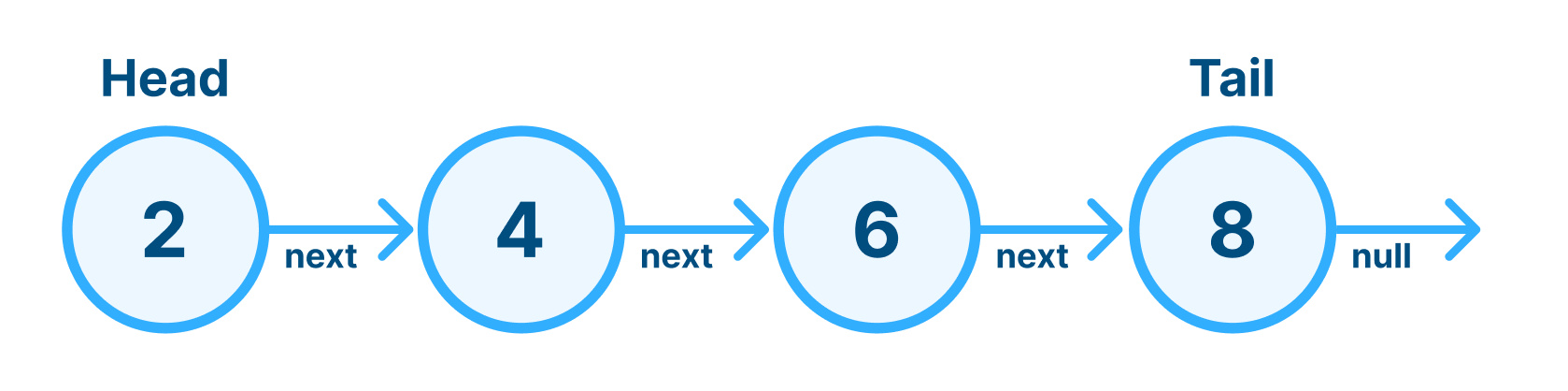
각 노드가 다음 노드로 오직 단일 방향으로만 연결되었다.
Tail은 맨 마지막에 노드를 추가하는 작업을 쉽게 해 줄 뿐이라서 꼭 있을 필요는 없지만 Head는 시작 지점이라 반드시 필요하다. 원하는 것을 찾을 때까지 새로운 것을 추가할 때 하나씩 계속 이동하면 된다.
= 임의 접근이 허용되지 않는다.
연결리스트를 사용해야하는 가장 중요한 이유는 “삽입”과 “제거” 를 쉽게 할 수 있다는 것이다.
⇒ 임의 접근이 필요하지 않은 아주 긴 데이터 세트나 많은 정보에 대하여 작업할 경우 혹은 그냥 리스트에 저장만 하면 될 경우 연결리스트를 사용하는 것이 바람직하다.
Doubly Linked List
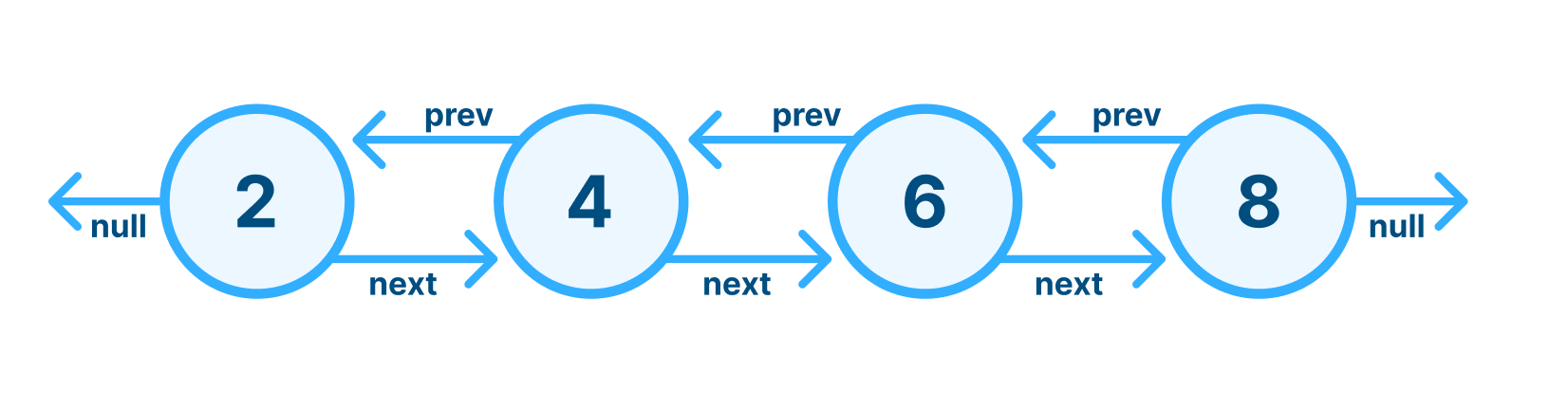
단일 연결 리스트는 한방향, 이중 연결 리스트는 양방향.
단일 연결 리스트에 앞의 노드로 갈 수 있는 포인터를 하나 더한 것뿐이다.
단일 연결 리스트에서 마지막 요소를 제거한다고 하면 리스트 전체를 순환해야 한다. 또 뒤에서 두번째 요소를 찾아야 한다. 그 요소를 Tail로 지정해줘야 하기 때문에!! 하지만 이중 연결 리스트는 그럴 필요가 없다. 마지막 요소를 없애고 싶다며 Tail로 가서 뒤에서 앞으로 작업을 하면 된다.

노드들을 Unique하게 식별할 수 있다면, 각각의 노드들을 HashMap과 같은 O(1)에 찾을 수 있는 자료구조에 넣어놓아, 삽입 및 삭제도 O(1), 조회도 O(1)에 하는 방법도 존재해요!