[EECS 498-007 / 598-005] 15. Object Detection


Intro
-
이번 강의에선 computer vision의 main task중 하나인 Object detection에 대해서 다룬다.
-
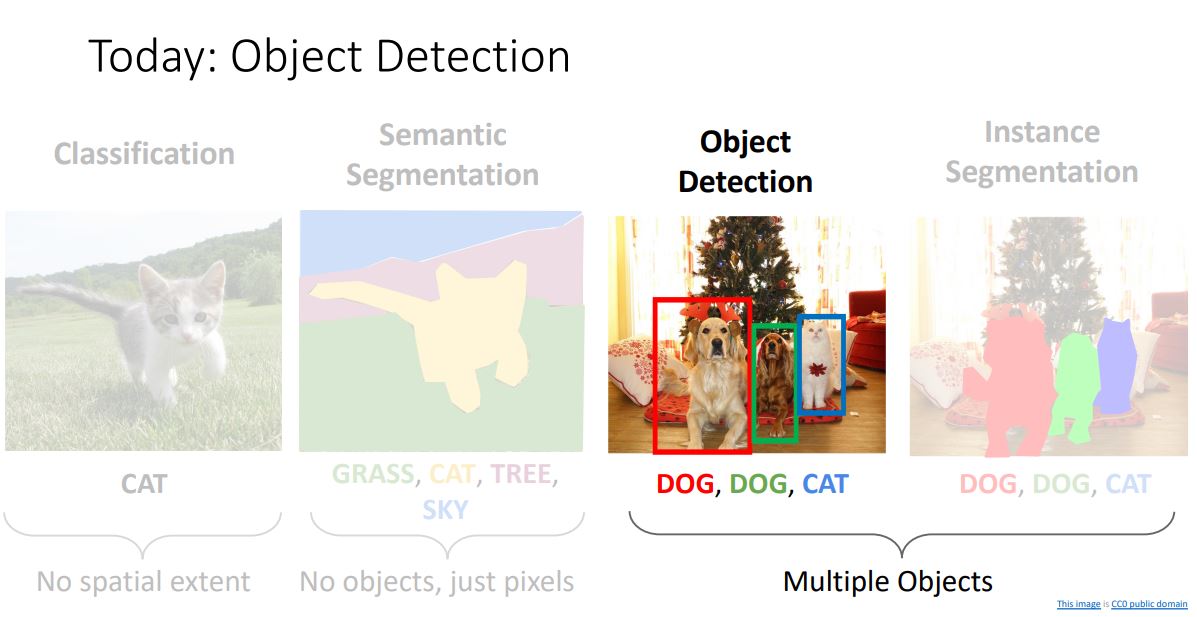
이 전까지 봐왔던 image classification task는 하나의 전체이미지를 CNN을 거쳐 single category label을 출력하는 형태였다.
-
Image classification은 많은 어플리케이션에서 사용되어온 만큼 매우 유용하지만 하나의 label(object)에 대해서만 분류한다는 단점이 있다.
Object Detection

-
Object detection은 single RGB 이미지를 input으로 받아 감지된 object들의 set 을 output으로 출력하는 형태이다.
-
각각의 object들은 Category label 과 해당 object의 spatial extent(location정보)를 나타내는 Bounding box 를 갖는다.
- 이때 bounding box는 (x,w,w,h)형태로 x, y는 box의 center인 하나의 pixel을 나타내곡 w, h는 box의 크기를 나타내게 된다.
-
Object detection은 image classification과 비교하면 상대적으로 약간의 복잡한 변화가 추가된 형태이다.

- Object detection이 image classification과 다르게 다룰 몇가지 문제는 다음과 같다.
- Multiple outputs
: Image classification과 다르게 detected object의 수가 가변크기를 가져야 한다는것.
- Multiple outputs
- Multiple types of output
: 앞서 언급했던데로 category label과 bounding box 인 두 종류의 다른 output을 갖는다.
- Multiple types of output
- Large images
: Image classification이 저해상도의 image를 다룬것과 다르게 Object detection은 상대적으로 고해상도의 image를 다루게된다.
- Large images
Detecting a single object
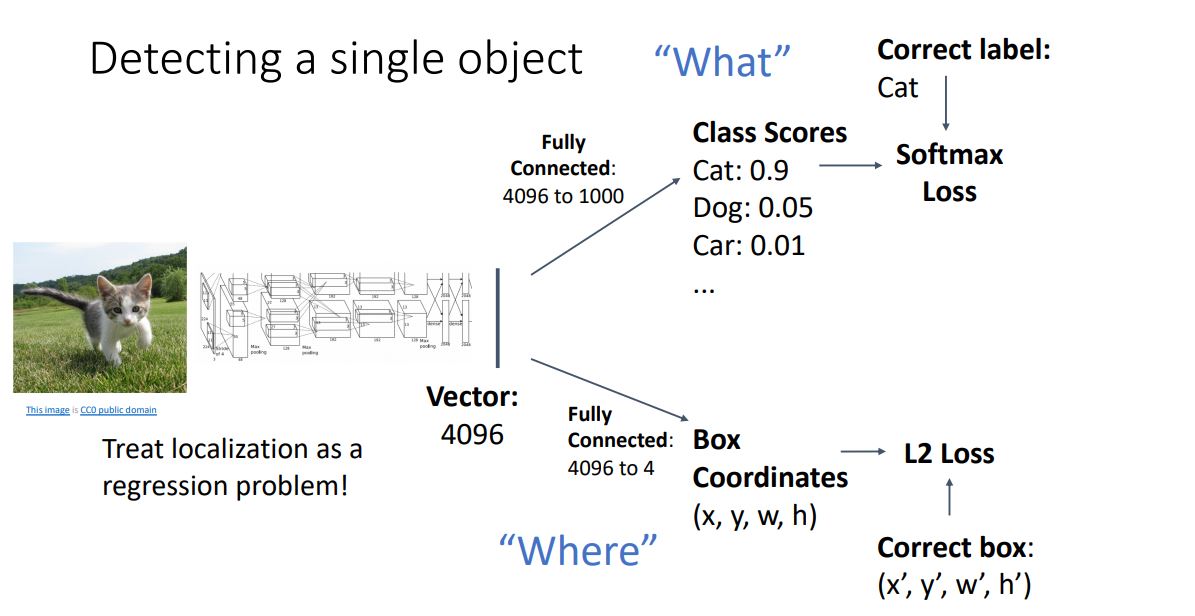
- Object detection 모델이 "a set of output"을 출력하는것을 보기 전에 single object에 대해 어떻게 detecting하는지 살펴보자.
-
일단 기본적으로 vgg, resnet과 같은 CNN을 통해 이미지의 vector representation(feature vector)을 뽑아낸다.
-
Vector representation을 통해 category label를 위한 loss, bounding box를 위한 loss 두가지의 branch를 갖게된다.
- 이때 label를 위한 branch에선 FC-layer를 통해 (class score를 위한)1000개의 vector로 나타내고, box를 계산하는 branch
에서는 box좌표정보를 위해 FC-layer를 통해 4개의 값을 뽑아낸다. - 또한 Box coordinates는 L2 loss와 같은 regression loss를 사용하게 된다
- 이때 label를 위한 branch에선 FC-layer를 통해 (class score를 위한)1000개의 vector로 나타내고, box를 계산하는 branch
-
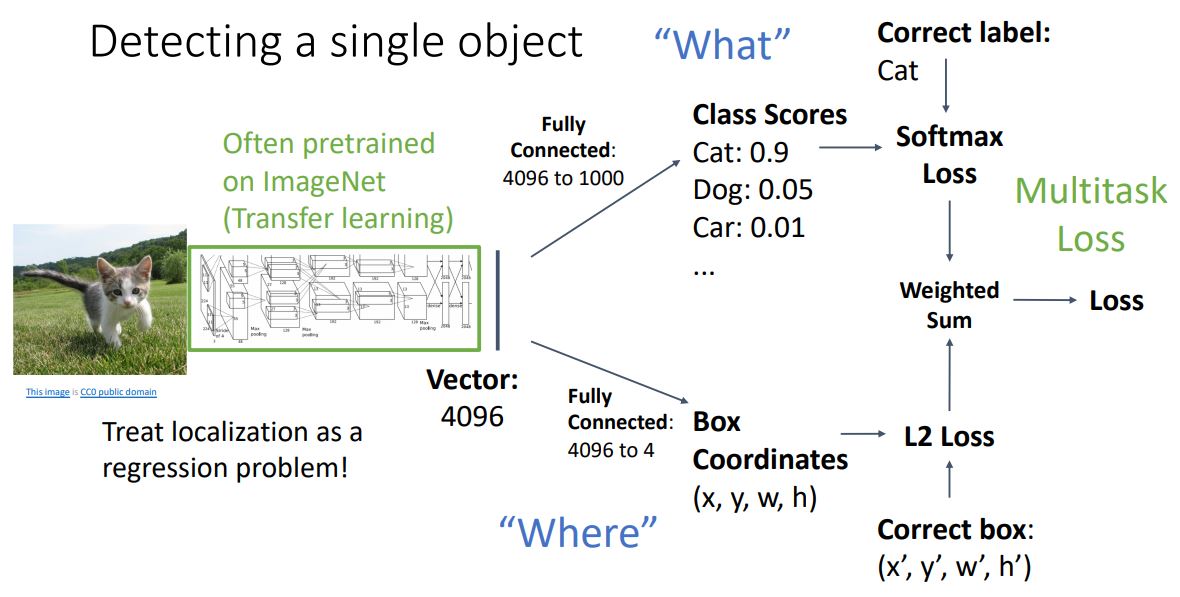
이때 gradient descent를 위해 두개의 loss를 잘 조합하여 single scalar loss를 구해주어야한다.
-
두개의 loss를 weighted sum을 통해 하나의 loss를 뽑아내게 되는데 이때 두 loss간 상대적인 중요도에따라 잘 tuning해주어야 한다.
-
이렇게 하나의 network에서 mutiple diffenrent loss를 갖는 형태를 Multitask Loss 라고 한다.

- 하지만 위 그림처럼 이미지마다 different numbers of outputs
을 갖는 경우 다른 mechanism이 필요하다.
Detecting Multiple Objects: Sliding Window
- Multiple Objects를 detect하기 위한 간단한 방법으로는 Sliding Window가 있다.

- Sliding Window방식은 전체 이미지에서 sub-rigions 혹은 sub-windows들을 CNN에 input으로 집어넣어 object인지 background인지 판단하게 된다.

-
하지만 이러한 Sliding window approach는 위 그림에서처럼 고정된 box size에 대한 모든 possible position뿐 아니라 모든 possible box sizes, possible aspect ratios를 고려해보면 엄청난 연산을 해야하고 이는 실현 불가능하다.
-
이러한 문제로 Object detection에 대한 또다른 approach가 필요하다.
Region Proposal

-
이미지의 모든 possible region들을 object detector를 통해 평가하는 대신 "set of candidate regions"을 생산하는 external algorithm을 사용한다.
- 이때 candidate region들은 상대적으로 이미지별로 small set이 되며되며 모든 object를 커버할 확률이 높다.
- 이러한 region proposals 이라는 명칭을 가진 candidate region을 생산하는 mechanism들은 오래전 몇몇 paper에서 제안되었다.
- 이들 중 가장 유명한 Selective Search algorithm은 이미지당 2000개의 object proposal을 생산하며 CPU를 통해 처리한다.
-
이러한 Region proposals algorithm을 활용하여 object detection의 input으로 넣는 딥러닝 모델을 살펴보자.
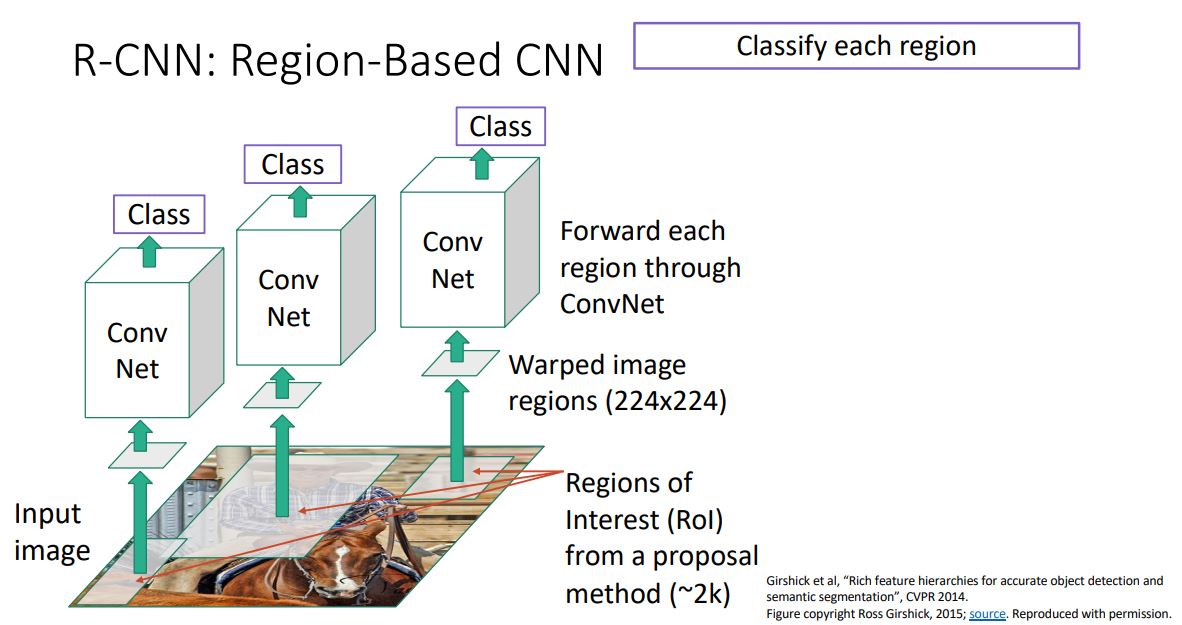
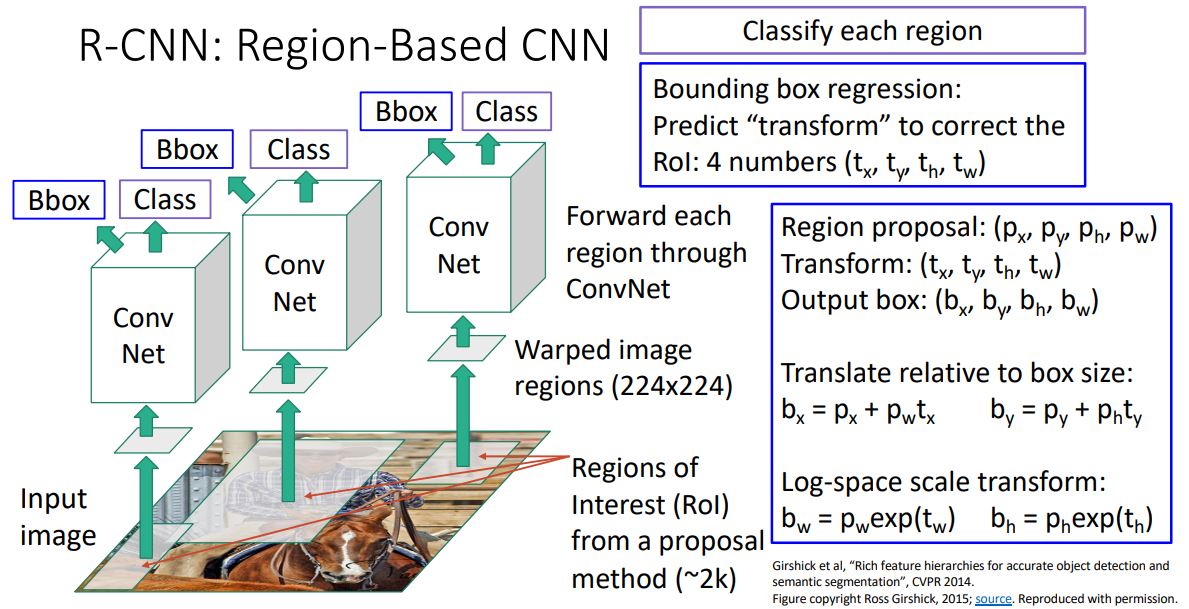
R-CNN: Region-Based CNN
-
R-CNN은 우선 input image에 selective search와 같은 region proposal mothod를 사용하여 2000개의 RoI(Region of interest)를
뽑아낸다. -
이때 2000개의 각각의 RoI들은 서로 다른 사이즈와 aspect ratio
를 갖고있기에 (224x224)size로 warping 시켜준다.- conv layer는 input size가 고정
-
Warped image region들은 각각 CNN으로 forwarding시켜 처리한다.
-
하지만 이때 selective search를 통한 image region들은 detect하고자하는 object들과 일치하지 않을 뿐더러 selective search를 통한 bounding box 추출 메커니즘이 black-box의 형태로 학습이 되지 않는다는 문제가 있다.
-
Black-box형태의 메커니즘에의해 발생한 문제는 이전에 살펴본 Multi-task loss 를 사용하여 해결한다.
-
CNN은 class score외에도 B-box를 예측하는 output이 있다.
- 이 Bbox는 region proposal box을 transform 시켜 우리가 원하는 최종 output box를 예측하는 값이다.
- 이러한 bounding box regression은 reigion proposal에 의한 RoI를 좀더 object에 fitting되도록 약간 수정시키는 것 이다.
- ConvNet을 통해 ()를 출력시키고 위 그림에서처럼 Region proposal box ()을 transform시켜 Output box ()를 최종 출력하게 된다.
- 이러한 trasnform된 최종 output box는 CNN에 input으로 들어오는 region proposal 영역을 trasnform시켰기에 input을 forwarding시키기 전 warping 시킨 것 과는 무관하다.
-
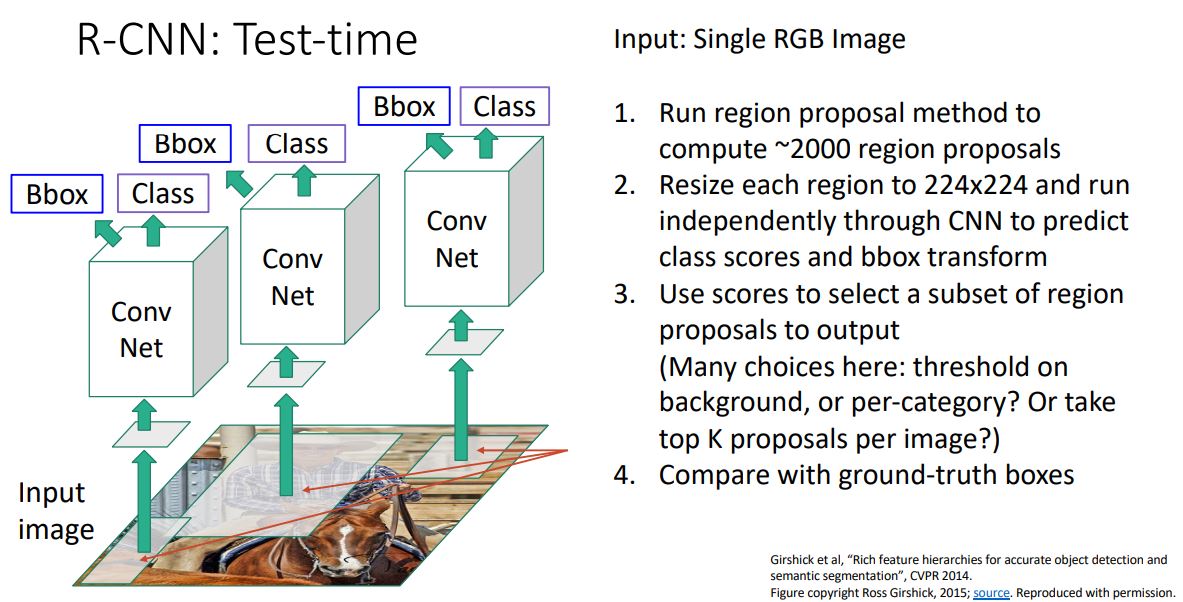
R-CNN의 test시 pipeline은 다음과 같다.
-
- RGB 이미지를 input으로 Region proposal method를 통해 2000개 가량의 region proposal을 추출한다
-
- 각각의 region proposal들을 고정된 크기로 resize 시키고 독립적으로 CNN에 forwarding시켜 (background를 포함한)class score와 Bbox trasform을 예측한다.
-
- Class score를 사용하여 각 region proposal중 subset을 선택하여 최종 output을 출력한다. 이때 다양한 방법들이있다.
- 2000개 가량의 region proposal에서 CNN을 통해 구한 class socre들의 full distribution으로 background score 혹은 각 커테고리별로 threshold를 취하거나 top K개의 proposal을 output으로 출력하는 방법인데 이는 application마다 다른 방법을 선택해야 한다고한다.
-
- 마지막으로 output을 evaluate하기 위해 ground-truth boxes와 비교한다.
- 아니 test-time인데 왜 evaluate하고 ground-truth가 있는건지 모르겠다...
-
* 강의 중 한 질문의 답으로 모든 ConvNet은 weights를 공유한다고하였고 또한 강의에서 training-time을 언급하지 않은 이유는 training을 이해하기 위해선 몇가지 subtleties 들을 알아야 하기때문인데 짧게 설명하면 batch of image regions 을 사용하여 학습시킨다고 한다. 뭔소린지 잘 모르겠다.
- 논문을 찾아보니 "Domain-specific fine-tuning" 에 해당하는 학습 pipeline에서 IoU 가 0.5이상인 것들을 positive 객체로 보고 나머지는 negative로 분류하여 fine-tune하게되고, 각 SGD iteration마다 32개의 positive window와 96개의 backgroud window 총 128개의 배치로 학습이 진행하였다고 한다. (IoU는 바로 직후 다룰 예정)
Comparing Boxes: Intersection over Union (IoU)
- prediction box랑 ground-truth box랑 비교하기위한 mechanism으로 Intersection over Union (IoU)를 사용한다.


-
위 그림에서 주황색에 해당하는 Area of Intersection에 보라색에 해당하는 Area of Union을 나눠주어 overlap되는 ratio를 계산하게된다.
-
직전에 언급한데로 해당 논문에서는 IoU가 0.5이상인 것을 positive window로 사용하였다.
Overlapping Boxes: Non-Max Suppression (NMS)
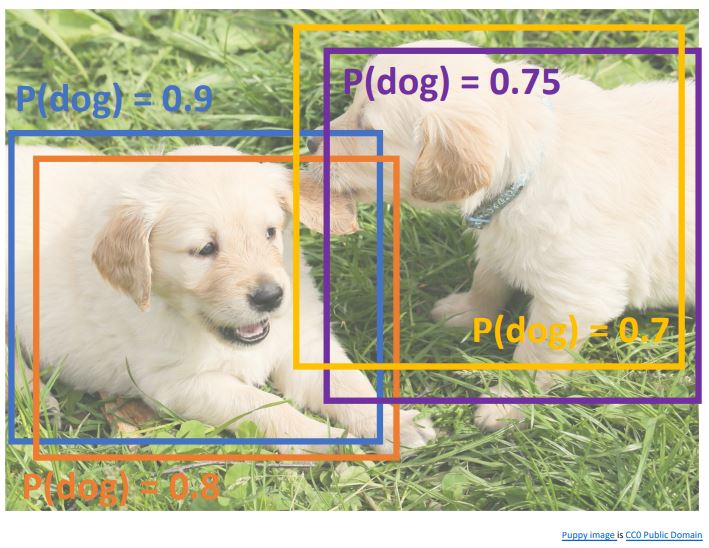
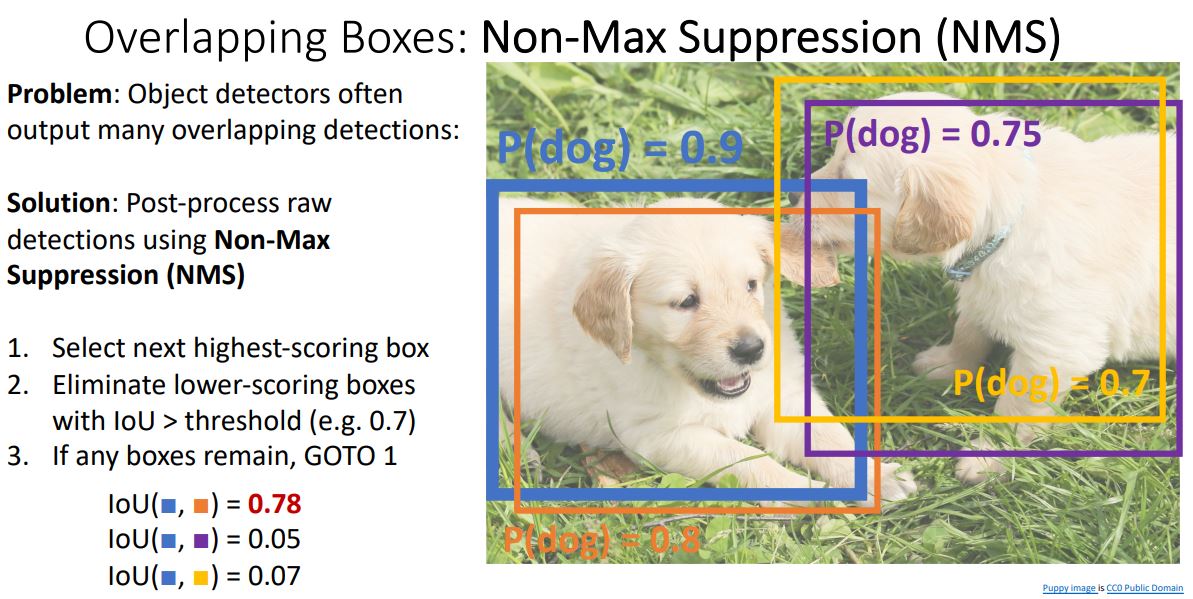
- Object detectors(R-CNN) 에서는 위 그림처럼 동일 class에 대한 여러 output box를 출력하게 되는데 이를 해결하기위한 방법으로 Non-Max Suppression (NMS)이 사용된다.
-
Non-max suppression 구현에는 다양한 방법들이 있지만 가장 간단한 방법으로는 greedy algorithm을 사용하는 것이고 다음과같은 과정을 갖는다.
- bounding box들의 예측 점수를 내림차순으로 정렬
- 가장 높은 점수의 box와 보다 낮은 점수의 나머지 박스들간
IoU를 계산하여 설정한 threshold보다 높은 box를 제거. - 남은 box가 있으면 계속 진행.
-
위 그림에서 NMS를 진행하면 파랑, 보라 box만이 남게된다.

- 하지만 위 그림처럼 많은 object가 있는 image의 경우 NMS는 좋은 결과를 내지 못한다. (엄청나게 overlapping되게 때문)
Mean Average Precision (mAP)
-
위에서 언급하였던 IoU matric을 사용해 individual box간 비교하는 방법외에 object detector가 test-set에 얼마나 잘 작동할지를 평가하는 overall perfomance metric이 필요하다.
-
Object detection에서 흔히 사용되는 matric인 Mean Average Precision 을 살펴보자.

-
일단 모든 test-set image를 object detector로 forwarding시키고 NMS를 통해 불필요한 detection들을 걸러낸다.
-
위 과정을 통해나온 각각 image의 bunch of detected boxes는 각category에 대한 class score를 갖게된다.
-
이 각각의 category를 가지고 Average Precision을 구하게되는데 이는 각 category가 overall에서 얼마나 잘 하고있는지? 를 나타내며 Precision Recall Curve를 통해 나타낼 수 있다.
-
각각의 detection에서 PR Curve를 그리는 법을 살펴보자
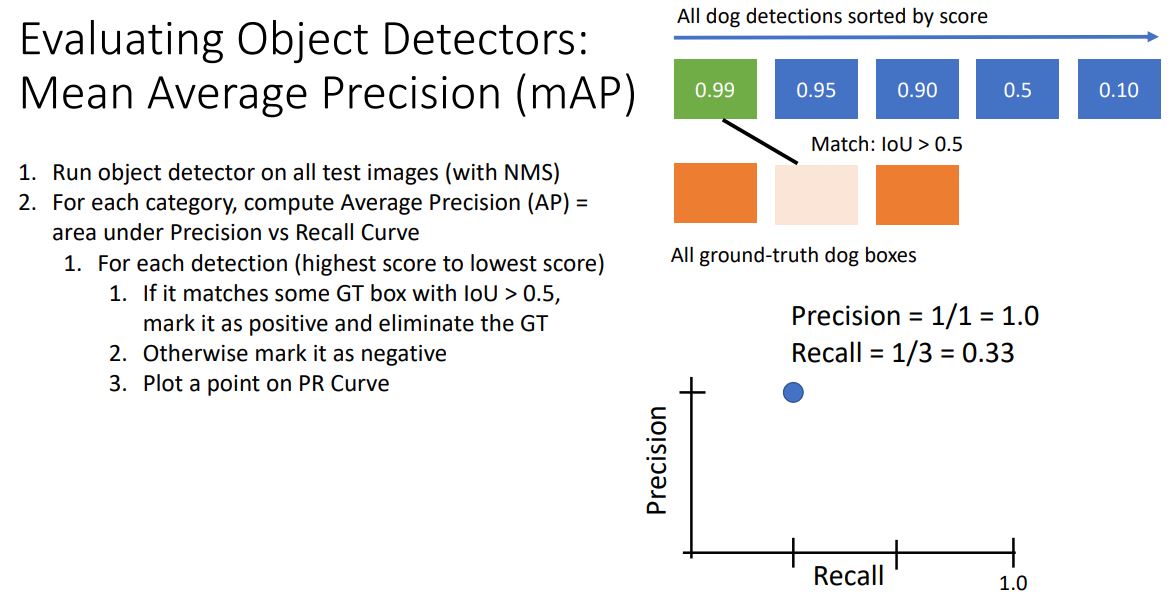
- 일단 가장 높은 score를 갖은 detection과 모든 GT(ground-truth)를 비교하여 IoU가 0.5보다 큰 GT를 (correct detection을 뜻하는) True Positive 가 되고, 나머지 GT를 False Negative 로 표시한다.
- 이때 Precision과 Recall은 위와과같은 공식을통해 계산되며
이를 PR Curve로 plot에 찍는다.
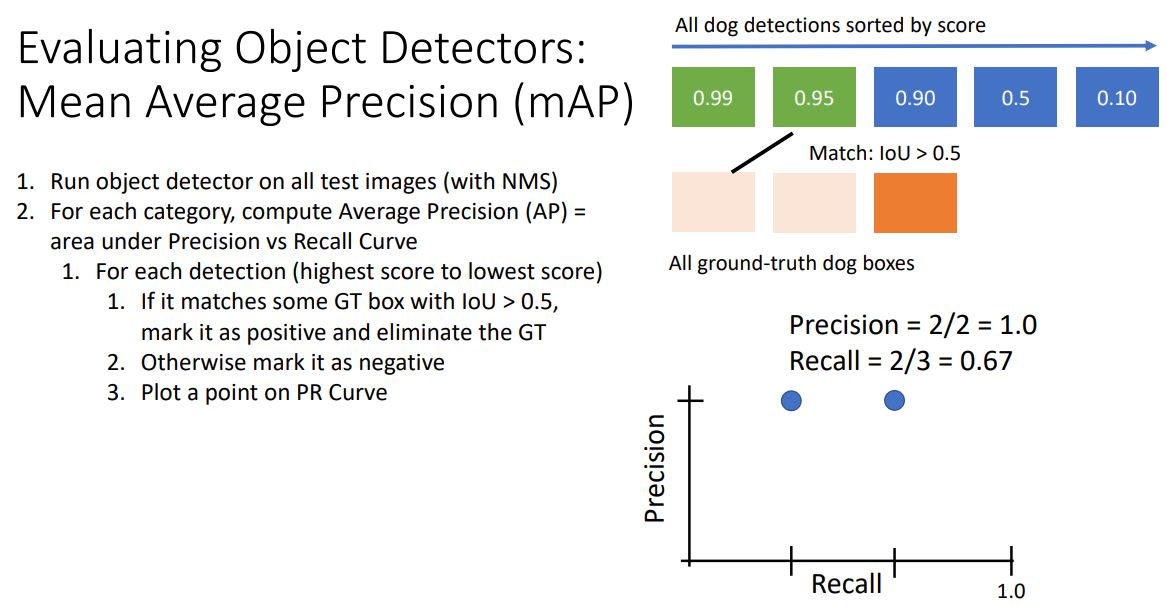
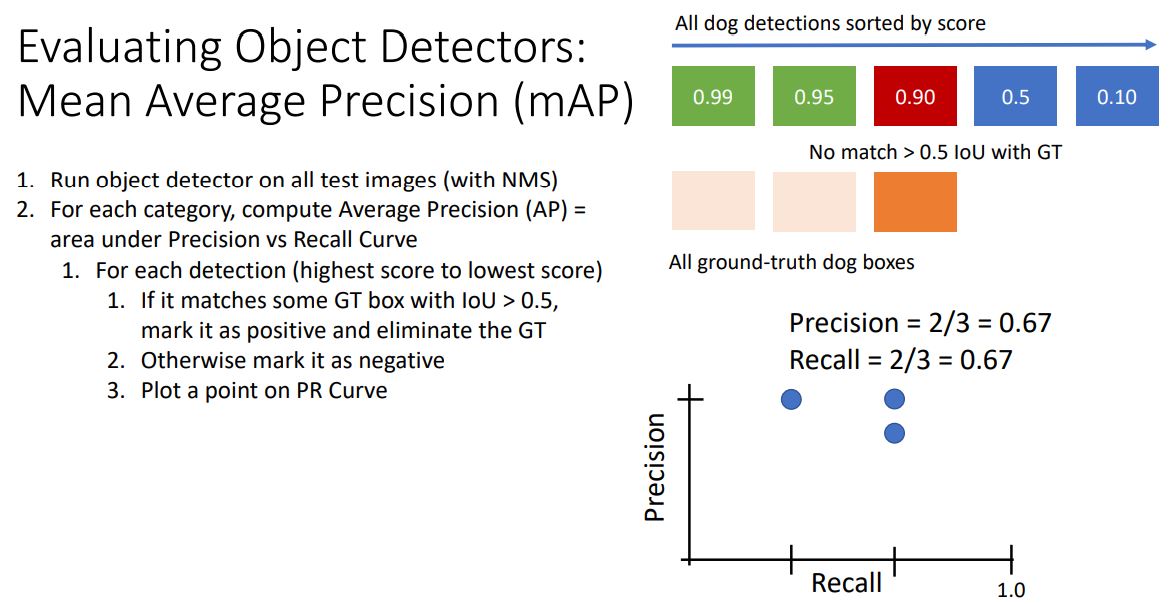
- 각 detection의 높은 score순으로 진행하다가 (두번째 그림처럼) IoU가 0.5이상인 GT가 positive로 flaging된 GT이면 False Positive 가 되고 이를 통해 Precision, Recall을 계산하여 plotting한다.
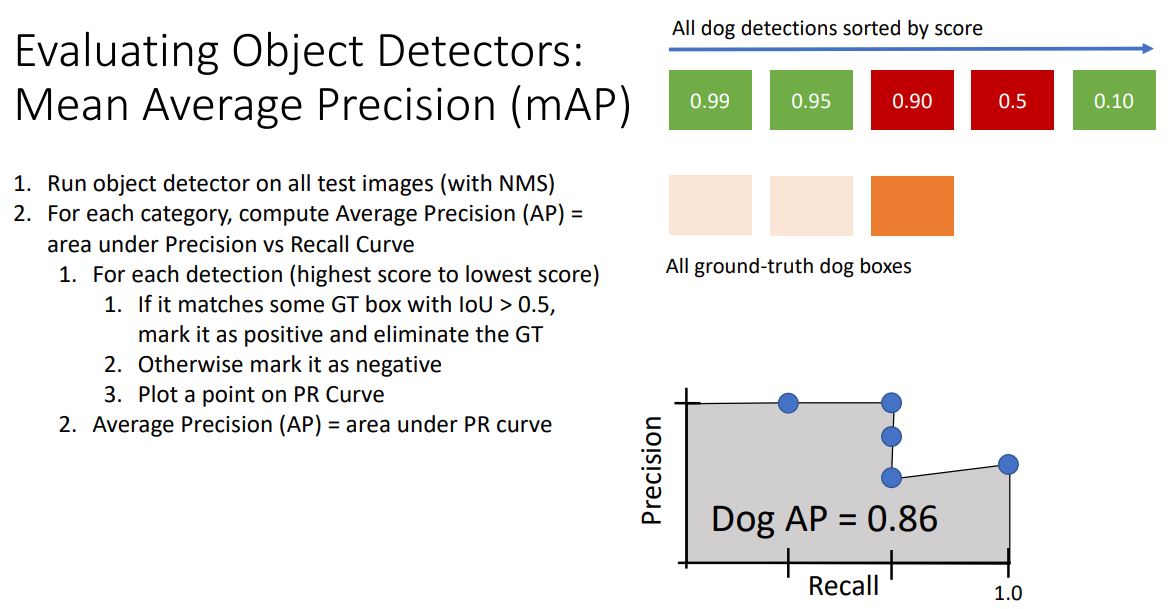
-
모든 detection에 대해 Precision, Recall을 계산하여 plotting을 하였으면 PR curve의 area를 구하여 Average Precision (AP) 를 구해준다.
- 이때 AP는 0~1 사이의 값을 갖는데 0에 가까울수록 detector가 terribly하다는 의미를 갖고 1.0값을 갖는다면 high score detection 값들이 TP(True Positive)이며 FP(False Positive)가 없다는 뜻이다(모든 detection 들이 GT와 매칭된다는 것).

-
위처럼 category별로 구해진 AP들을 평균내어 mAP를 구해줄 수 있게된다.
-
하지만 이런 mAP는 사실 IoU > 0.5 를 사용하기에 localizing boxes를 평가하는데 적합하지 못하다.

- 그래서 위 그림의 COCO mAP 처럼 여러 IoU thresholds의 mAP를 평균내어 사용하기도한다.
- 다시 R-CNN으로 돌아와서 이러한 R-CNN도 문제가있다.
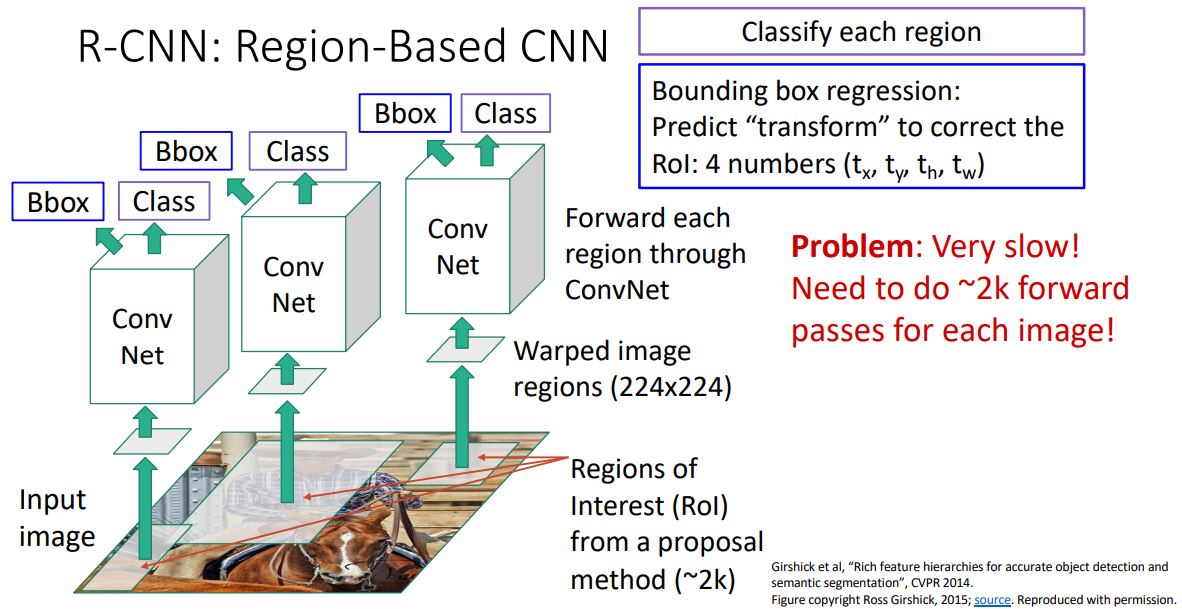
- 위 그림에 나온 것 처럼 R-CNN은 2000개 가량의 region proposal을 CNN에 forwarding 시켜야 하기에 매우 느리다.
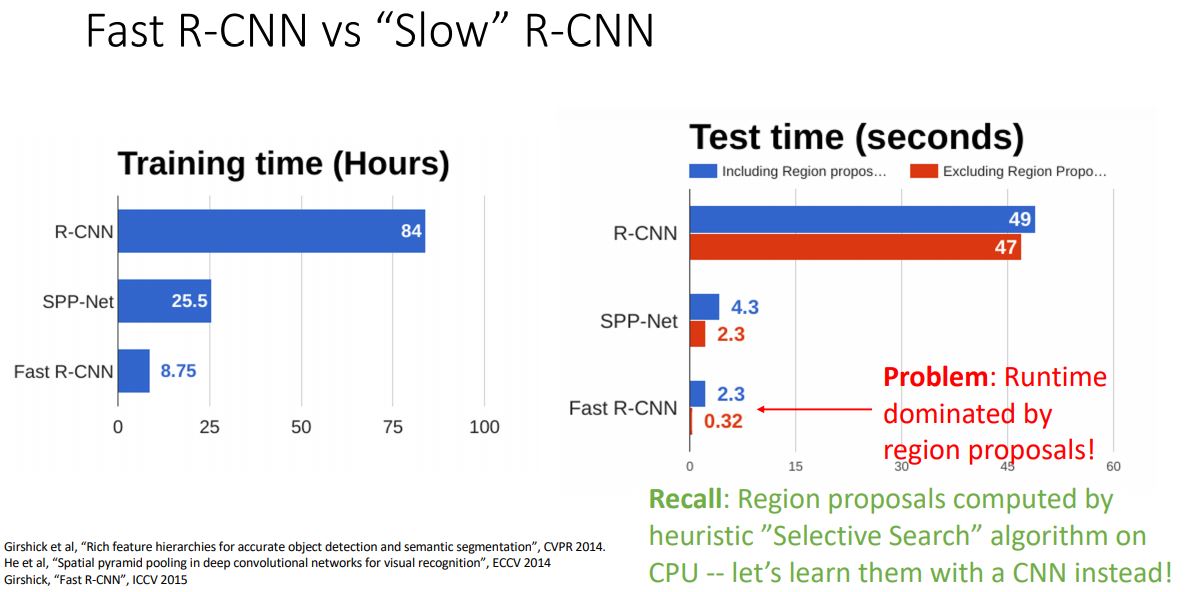
Fast R-CNN
- R-CNN의 매우 느린 문제를 해결하고자 하는 Fast R-CNN을 살펴보자.
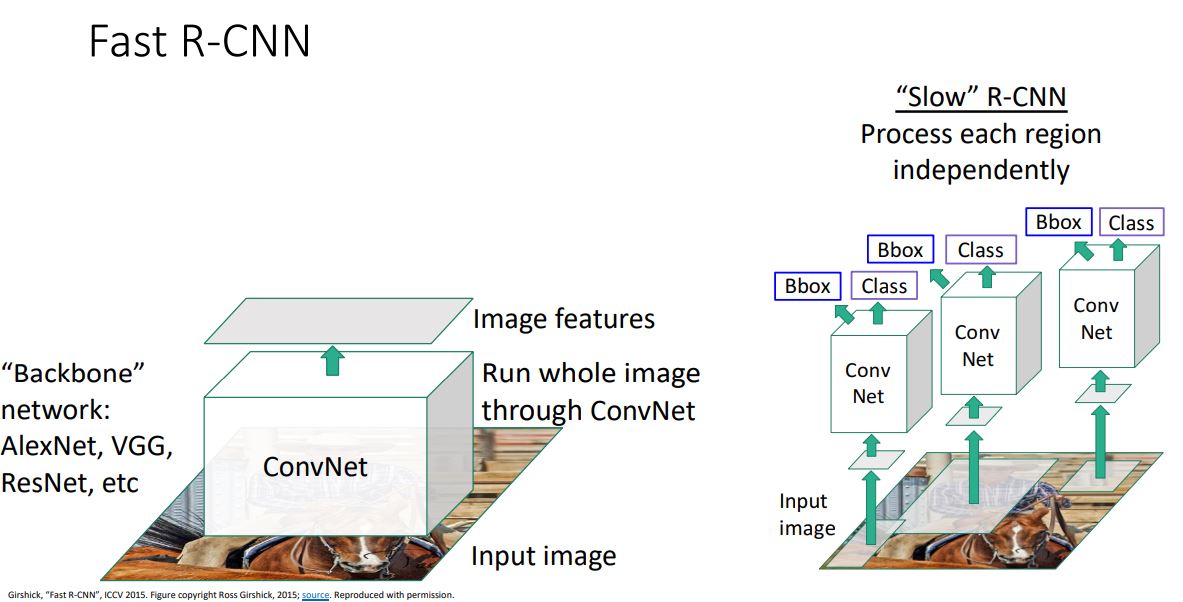
- 위 그림처럼 기존 R-CNN처럼 모든 region proposal을 CNN에 forwarding 시키는 것이 아닌 전체 image를 single CNN에 forwarding시켜 feature를 뽑아낸다.
- 이때 FC-layer는 없고 오직 Conv-layer만 있다.
- Backbone network(CNN)을 통해 뽑아낸 features를 가지고 selective search와 같은 method를 통해 RoI를 뽑아내게된다.
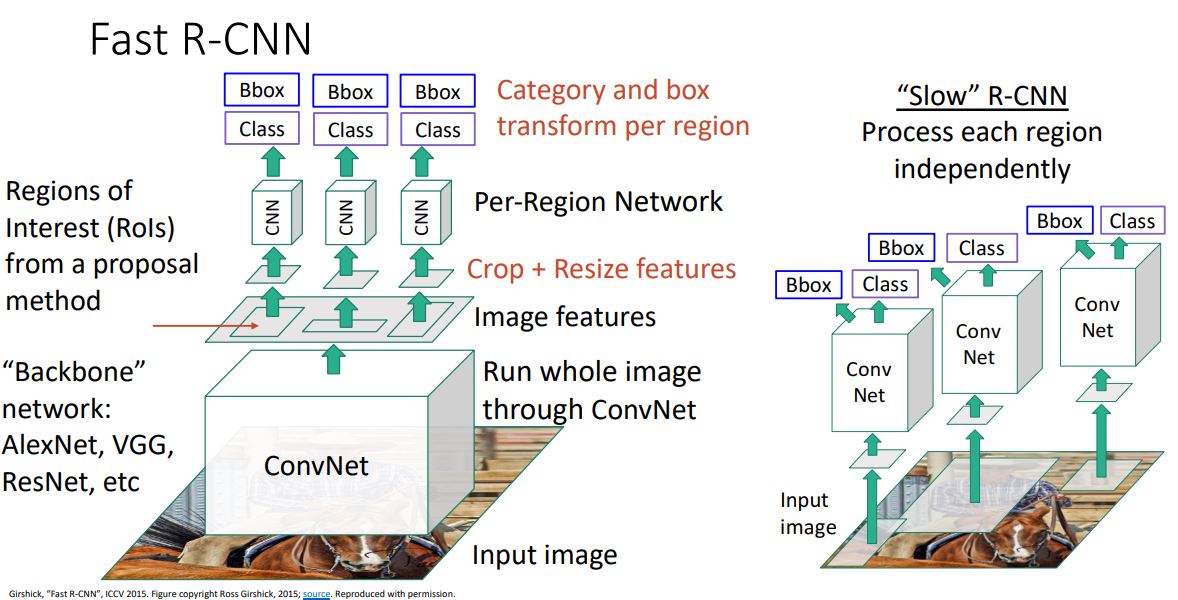
- 추출한 RoI들은 cropping시키고 resize시켜 각각을 CNN에 forwarding시켜 R-CNN과 같은 과정으로 output을 출력하게 된다.
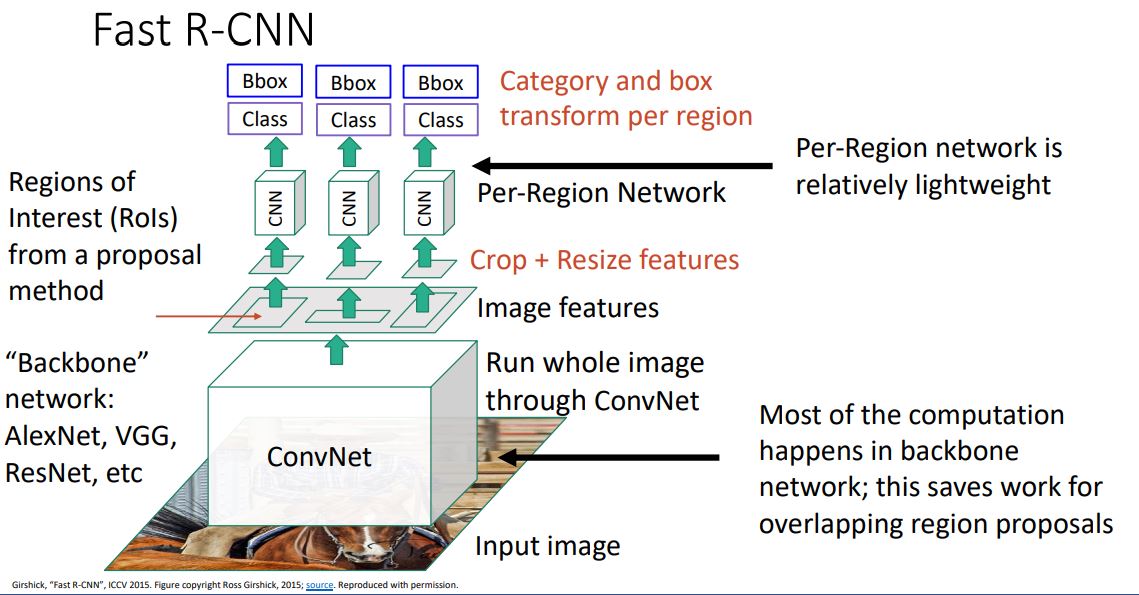
- 이때 중요한 것은 대부분의 연산이 backbone network에서 이루어진 다는 것이고 각각의 region을 처리하는 CNN(Per-Region network)에서는 상대적으로 가볍고 빠른 연산이 처리된다.
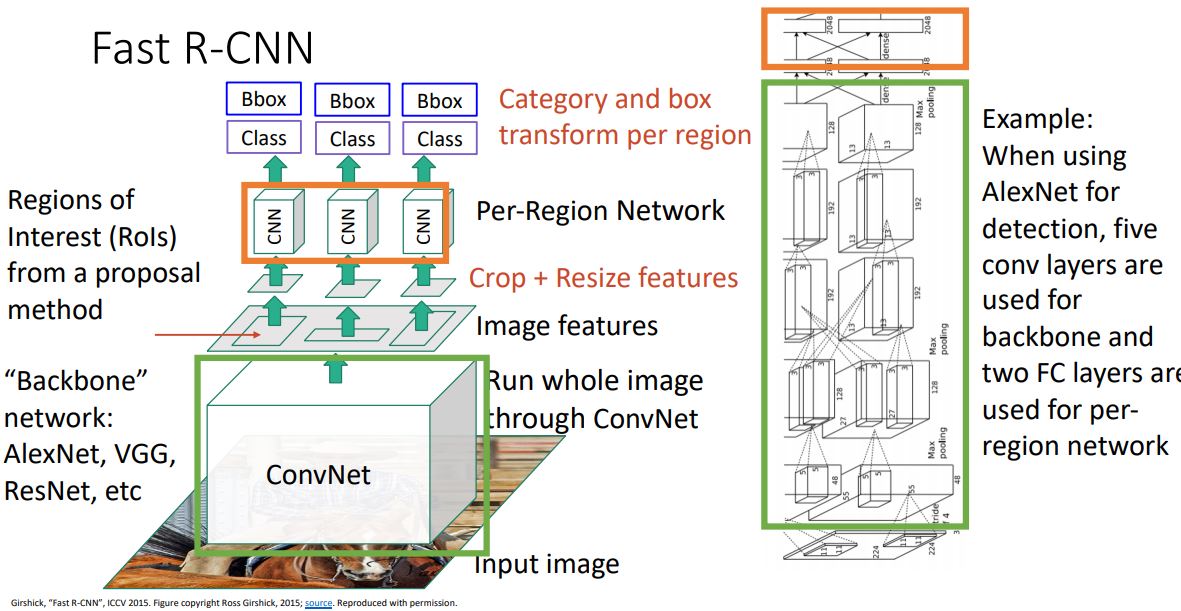
- 위 두 그림처럼 AlexNet과 ResNet을 예로들어 봤을땐 네트워크의 아랫단의 conv-layer들만 사용하여 backbone을 구성하였고, output layer 직전의 FC-layer (ResNet의 경우엔 conv-layer까지) 만 사용하여 Per-Region Network로 사용하는 것을 볼 수 있다.
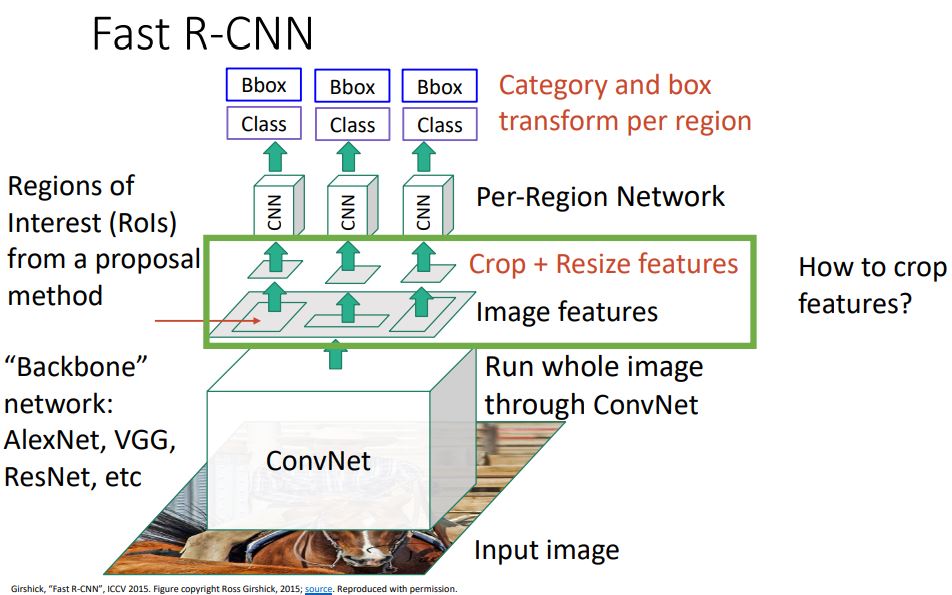
-
Fast R-CNN에서 feature를 cropping를 하는데 이때 backbone network까지 differentiable하게 만들어줘 backporp될 수있게 만들어 주어야 한다.
-
그렇다면 어떤 방식으로 differentiable하게 feature를 cropping하는지 살펴보자.
Cropping Features: RoI Pool
- Fast R-CNN에서 cropping feature로 사용되는 RoI Pooling 은 input image에서의 RoI를 image feature에 맞도록 매핑시키는 것 이다.
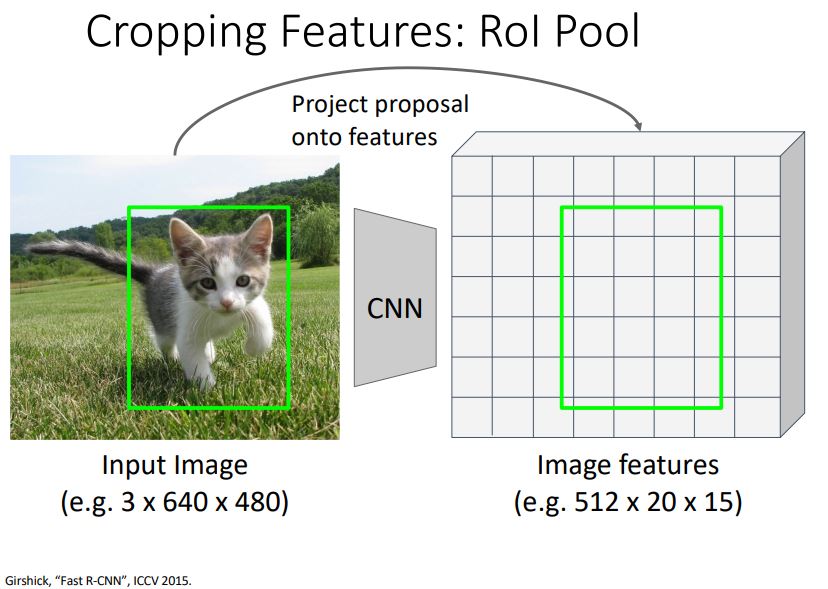
- 위 그림처럼 3x640x480의 input image의 RoI(region proposal)를 512x20x15의 features로 projection 시켜주는 것 이다.
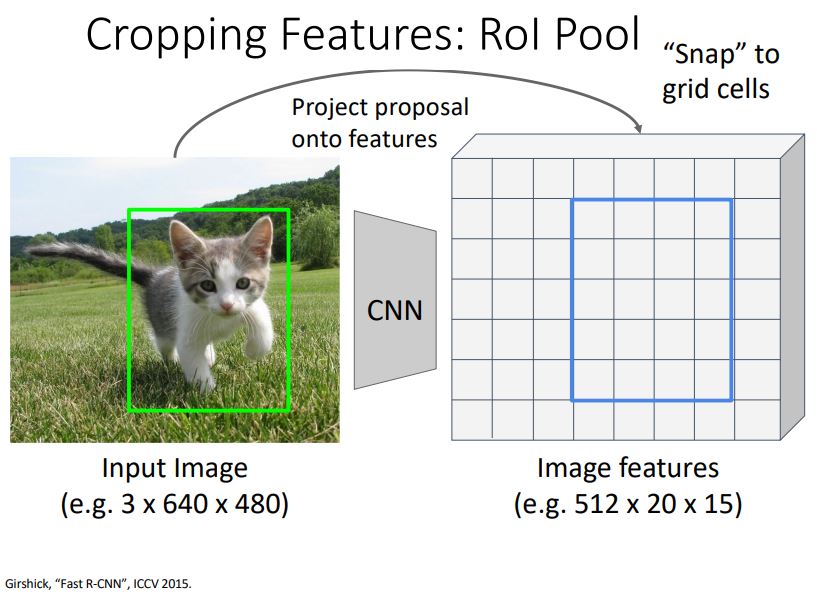
- 하지만 그냥 projection 시켜주면 RoI가 feature grid에 완전히
align되지 않기에 convolutional feature map에 "Snap" 시켜준다.
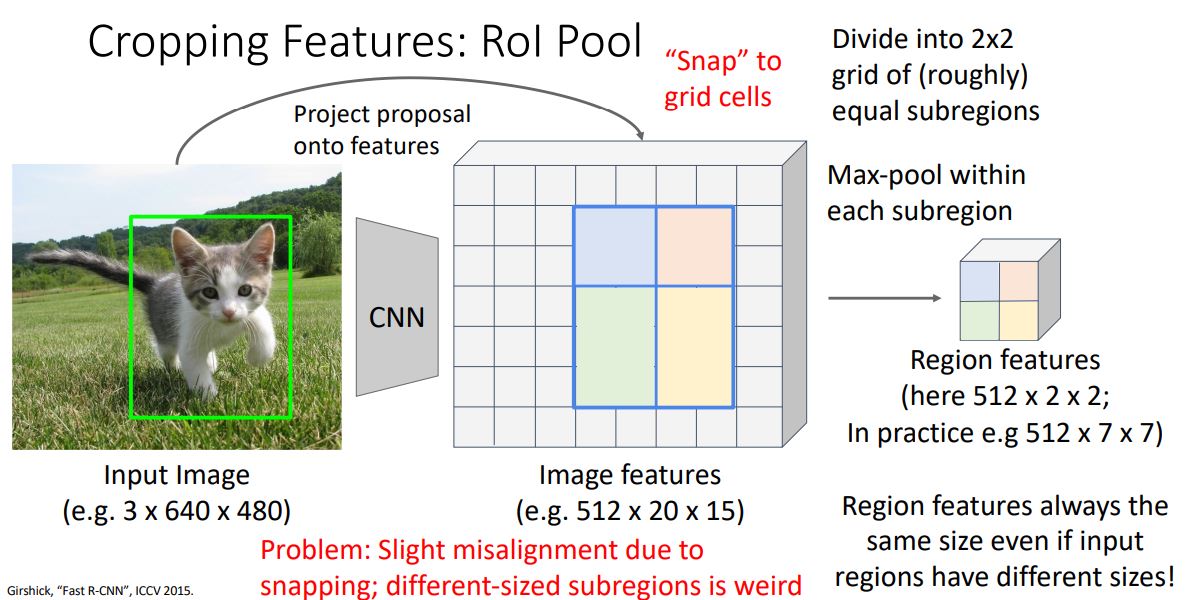
-
Projection된 RoI를 위 그림처럼 대충 2x2 sub-reigion으로 나누고 각 sub-reigion들을 max pooling시켜준다.
-
RoI pooling으로 인해 input region이 매번 다르더라도 tensor(output)가 매번 고정된 size를 갖게되는 것 이다.
* 어떻게 왜 differentiable하게 만든건지 모르겠다.
-> 일단 어디서 본 것은 conv layer의 input size는 고정될 필요는 없지만 fc layer의 size는 고정되어야한다고 본 것 같다.
-
이렇게 Fast R-CNN은 전체 이미지에 convolution연산을 진행함 으로서 2000번 conv연산 할 것을 원콤으로 처리한것. (conv layer에서 모든 region proposal의 연산을 공유했다고 볼 수도 있다)
-
추가로 snap하는 과정에서 약간의 오차가 생길 수 있어 약간 더 복잡한 방식으로 bilinear interpolation을 사용하는 RoI Align이 사용되곤 하는데 강의에서 깊게 다루지 않고 정리하기 너무 빡세서 혼자만 대충 봤습죠
-
이러한 Fast R-CNN도 "Slow" R-CNN에 비해 속도가 훨씬 빨라졌지만 여전히 (cpu를 사용하는) heuristic algorithm인 selective search를 사용하기에 여전히 이부분이 'bottle neck'이다
-
그렇기에 CNN을 사용하여 region proposal을 구하는 방법이 필요하다.
Faster R-CNN: Learnable Region Proposals
-
직전에 언급한데로 병목이 일어나는 heuristic algorithm인 selective search를 제거하고 CNN을 통해 region proposals을 예측해야한다.
-
이를 위해 Faster R-CNN에서는 Region Proposal Network(RPN)을 추가함으로 CNN에서 reigion proposal을 예측할 수 있게 만들었다.
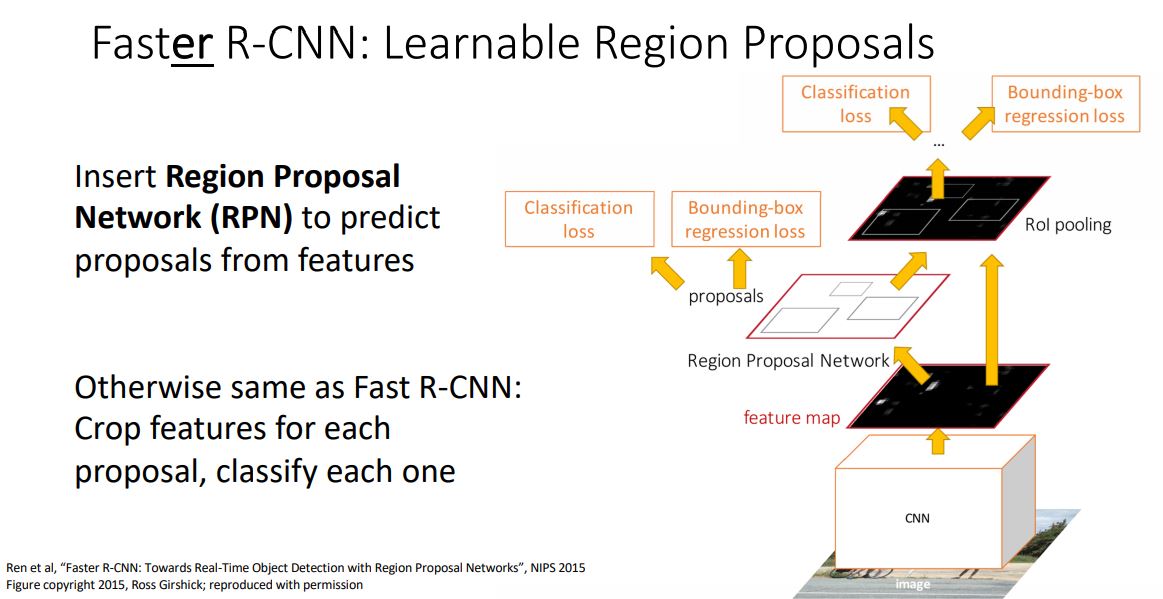
-
Faster R-CNN은 Region Proposal Network(RPN)을 제외한 나머지 구조는 Fast R-CNN과 동일하다.
-
Image level feature에서 selective search를 통해 region proposal을 뽑아내는 대신 RPN을 통해 region proposal을 뽑아낸다.
-
RPN에서 어떻게 CNN을 통해 trainable way로 region proposal을 뽑아내는지 알아보자.
Region Proposal Network (RPN)
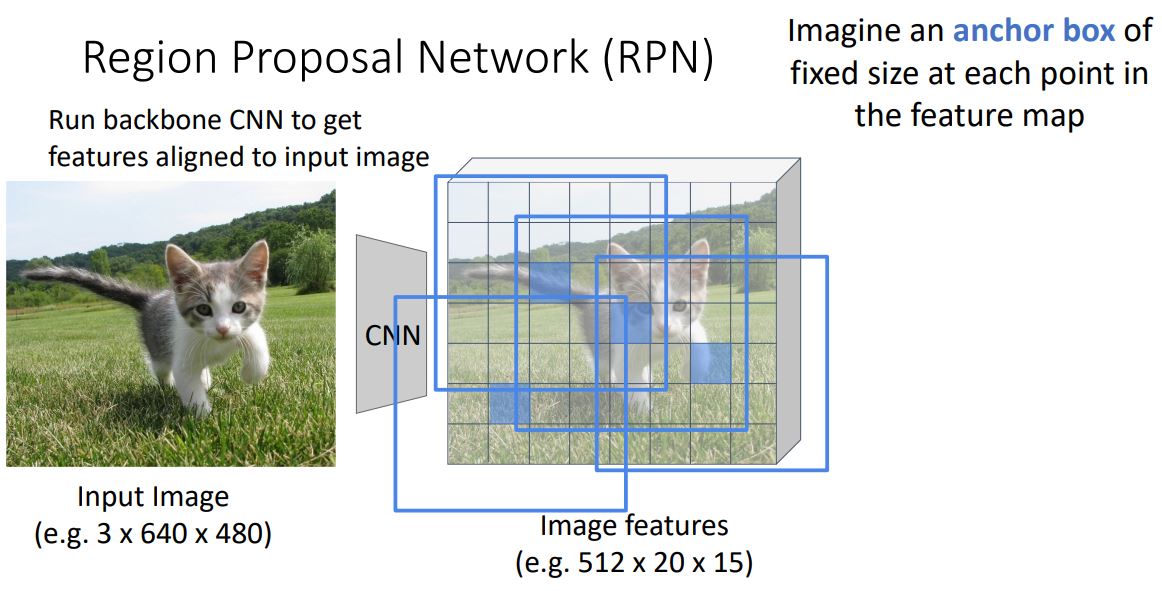
- R-CNN에서 input image의 RP를 feature map에 projection시키고 align시켰던 것과 달리 RPN에서는 feature map의 모든 point에서 고정된 크기의 anchor box를 사용한다.
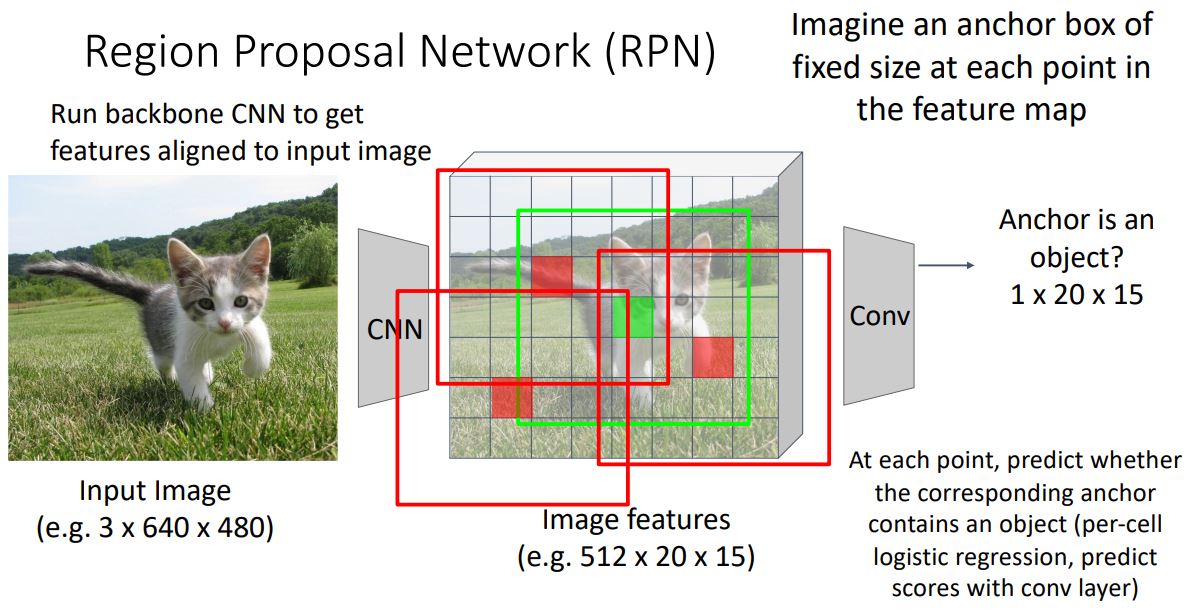
- 이때 RPN에선 anchor box안에 object가 있는지 없는지를 분류하여 CNN을 통해 학습시킨다.
- 이는 일종의 binary classification으로 각 position의 anchor box에 객체가 있으면 positive 없으면 negative score가 출력된다.
- single 1x1 conv를 붙여 output을 출력한다.
- 이때 two category에 대한 classification이므로 softmax loss를 통해 학습시킨다.
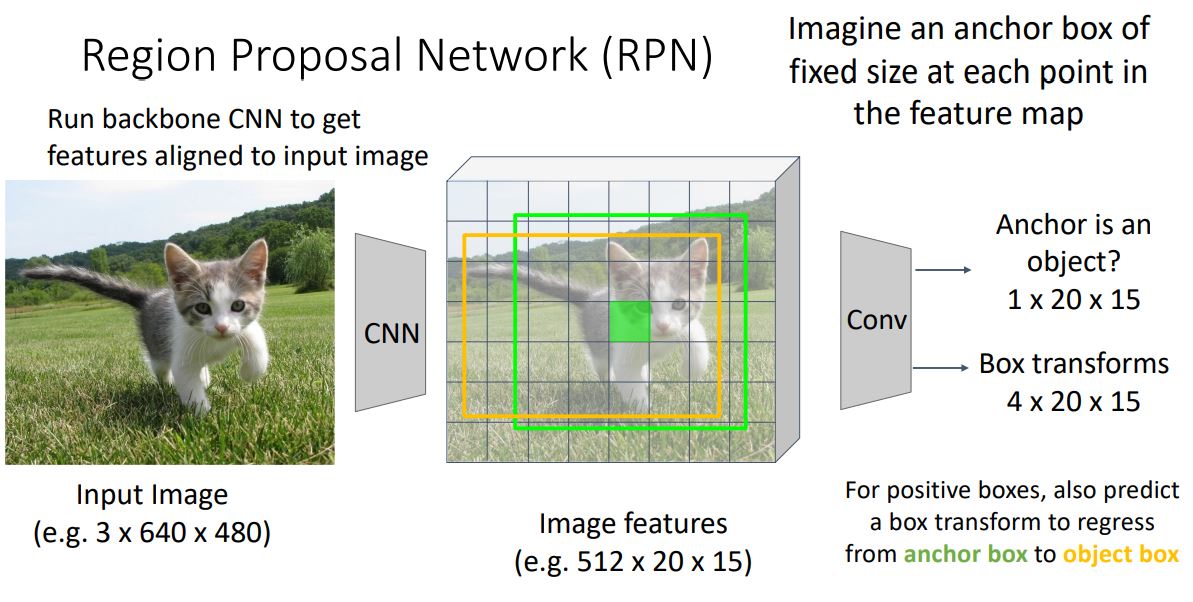
- 이러한 anchor box는 object에 잘 맞지 않아 regression을 위한 box transform을 사용하여 학습한다. (이전 R-CNN에서 Bbox의 regression 에서 본 형태)
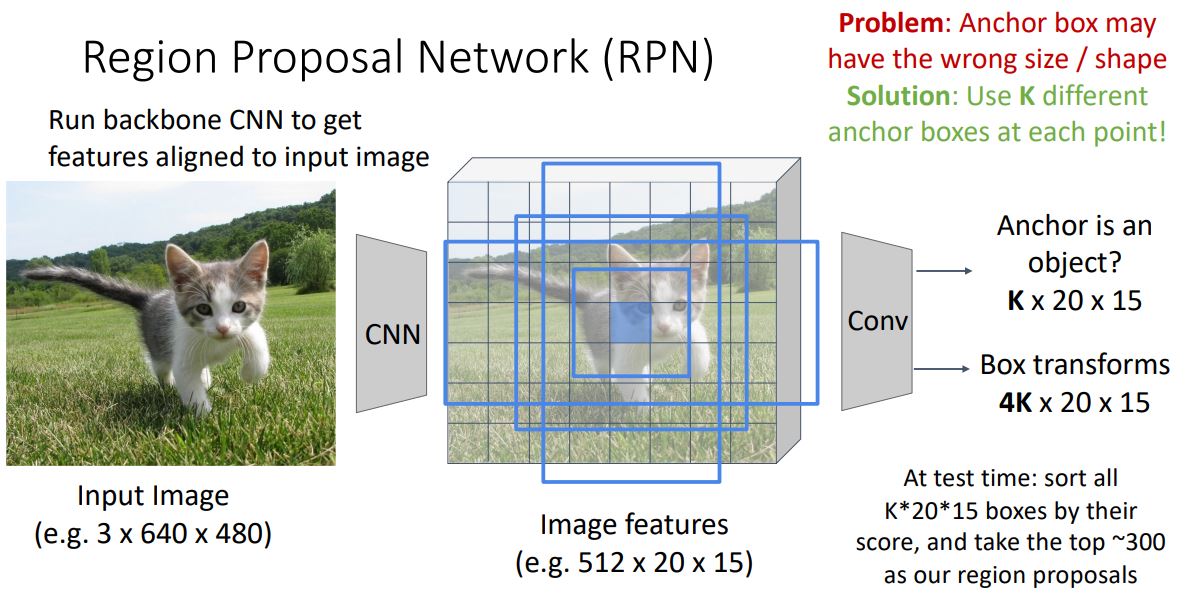
-
위와같은 고정된 크기의 anchor box만을 사용하면 모든 type의 object들을 잘 표현하지 못하기에 위 그림처럼 feature map마다 K개의 (서로 다른 size, aspect ratio를 갖는) anchor box들을 사용한다.
- 실제 구현할때에는 2K개의 anchor box를 통해 anchor당 positive score, negative score를 나누어 softmax loss를 사용하기도 하지만 하나의 score를 위해 logistic regression loss를 사용한다고도 한다.
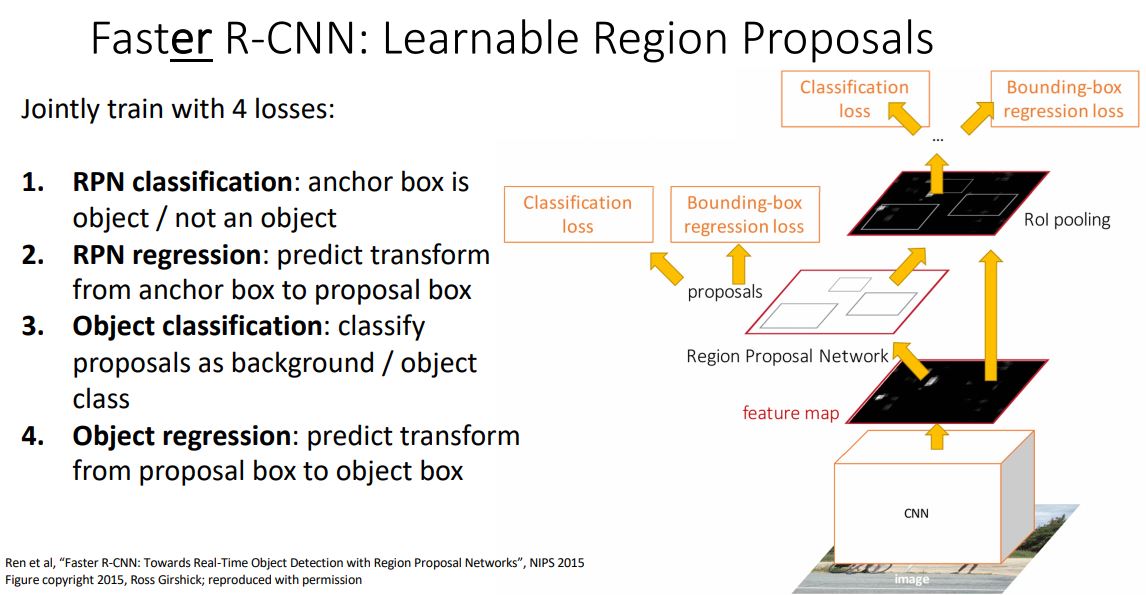
-
Faster R-CNN은 위 그림처럼 4개의 loss를통해 학습하게 된다.
-
각각의 loss들은 이전에 언급이 되었기에 설명은 생략합니다.
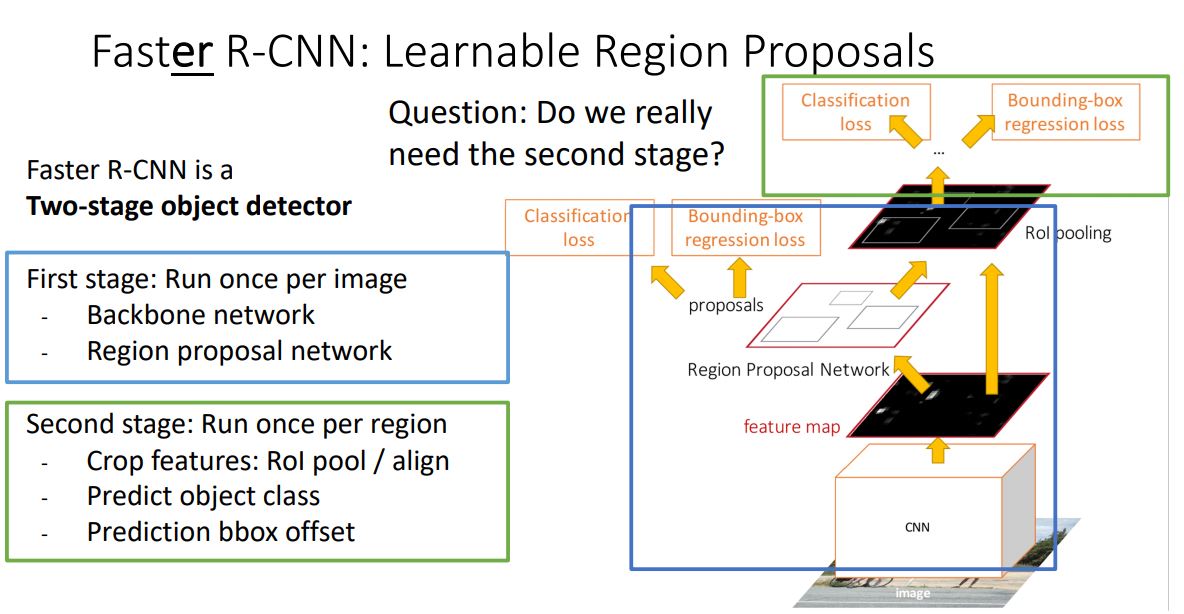
- Faster R-CNN은 위 그림처럼 object detector의 Two-stage method라고도 불리는데 그렇다면 굳이 second stage로 나눌 필요가 있을까?

-
Single-Stage Object Detection에서는 Faster R-CNN의 첫번째 stage만 사용하고 object or not을 판단하는 binary classification 대신에 full classification decision을 사용한다.
(위 그림에서 C+1 category별로 anchor를 사용) -
또한 regression도 카테고리별로 box transform을 학습하게 되는데 이를 category-specific regression 이라고 한다.

-
Object detection task든 다양한 선택을 할 수 있고 이로인한 trade-off관계를 위 그림을 제공하는 paper를 통해 insight를 얻을수 있다. 언젠간 읽어보겠지 ㅎㅎ.
-
끝 -
