[EECS 498-007 / 598-005] 14. Visualizing and Understanding

Intro
-
이번 강의는 convolutional neural network에서의 Visualizing and Understanding에 대해 다루어본다.
-
첫번째 토픽은 neural net내부를 들여다봐 training data에 대해 배운다는 것이 무엇인지 이해하려하는 테크닉이고
-
두번째 토픽은 neural net을 Visualizing 하고 Understanding하는데 사용되는 많은 테크닉들이 deep dream, style transfer와 같은 application에서도 사용될수 있다는 것이다.
-
Inside Convolutional Networks
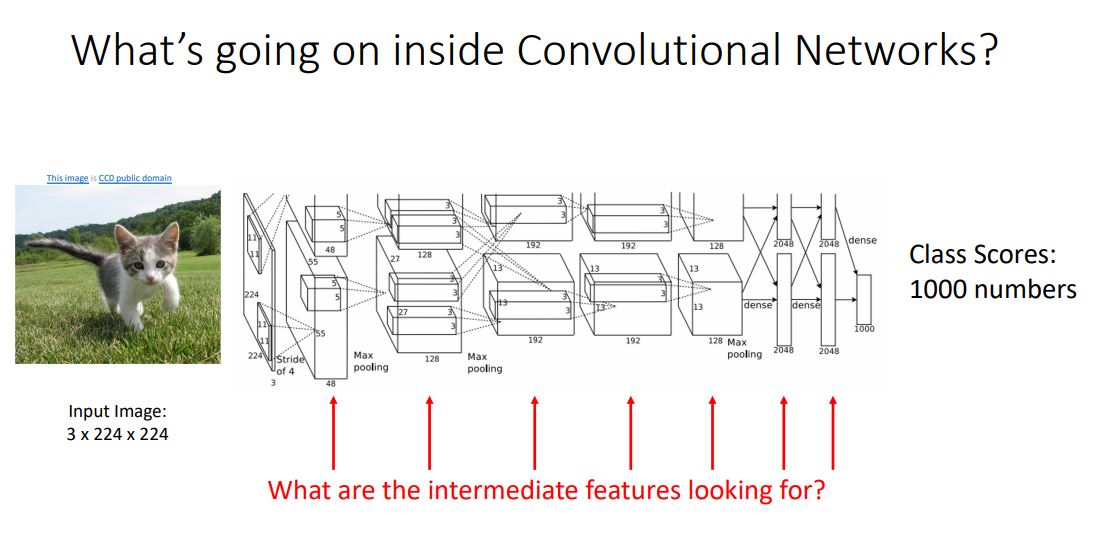
- CNN내부의 각각의 다른 layer들과 feature들을 살펴보고 각각이 "why it works or why it dosen't work"인지 알아봄 으로써 more intuition을 얻을 수 있다.
First Layer : Visualize Filters
- Lec3 classification에서도 언급되었듯 neural net안에서 무슨일이 일어나는지 알아보는 가장 기본적인 아이디어로 first layer에서 filter를 시각화 해보는 것이다.

-
위 그림에서처럼 여러 CNN model의 첫번째 layer의 filter를 살펴보면 다음과같이 나타나며 이는 각각의 filter들이 나타내는 일종의 templates묶음이라고 생각해 볼 수 있다.
- 잘 이해가 되지 않는다면 Lec3를 살펴보고 옵시다ㅎㅎ
Lec3. Linear Classifiers
- 잘 이해가 되지 않는다면 Lec3를 살펴보고 옵시다ㅎㅎ
-
위에 나오는 architecture들은 각각 다른 구조를 가지고 있지만 첫번째 layer의 filter를 위처럼 시각화해서 나타내보면 상당히 비슷하다는 것을 알 수 있다.
Higher Layers: Visualize Filters

-
첫번째 layer에서 fiter를 시각화 했던 것 처럼 higher layer에서도 filter를 시각화 해 볼 수 있는데 위 그림처럼 두번째 세번째 layer만 보았을 때에도 channel과 dimension이 커지며 뭐가뭔지 이해하기 힘들어진다.
-
그렇기에 layer에서 무슨 일이 일어나고 있는지 알기위한 다른 테크닉이 필요하다.
Last Layer
- Neural net이 뭘하고있는지 이해하기 위해 중간 layer들을 건너뛰고 마지막 fully-connected layer를 살펴볼 수 있다.
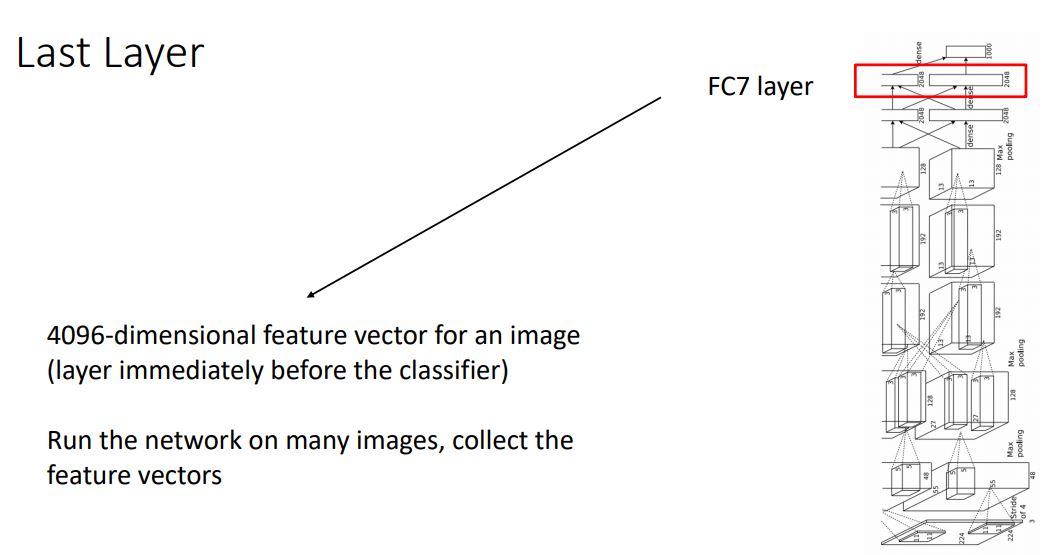
- ImageNet dataset을 학습시킨 AlexNet에서 1000개의 class score를 도출하기 직전 4096-dimensional feature vector를 가진 FC7-layer를 다양한 테크닉을 통해 시각화화여 살펴봄으로써 network가 무엇을 "represent" 하려하는지 이해해보자.
Last Layer : Nearest Neighbors

-
가장 간단한 방법으로 4096-dimesional vector에 nearest neighbors를
적용해보자. -
그림 왼쪽은 학습 시키기 전 pixel space에서 nearest neighbors를 적용시킨 모습이고 오른쪽 그림은 last layer(FC7)의 feature space에서 nearest neighbors를 적용시켜본 그림이다.
-
이렇게 feature space에서의 NN은 오른쪽 그림의 코끼리처럼 머리가 어느방향으로 가있든 NN으로 찾은 test image가 trining image의 label과 동일 하다는 것을 볼 수있다.
- 이를 통해 raw pixel value가 다르더라도 model을 거쳐 feature vector로 표현되는 것은 같은 label을 갖을수 있다는 것을 보여준다.
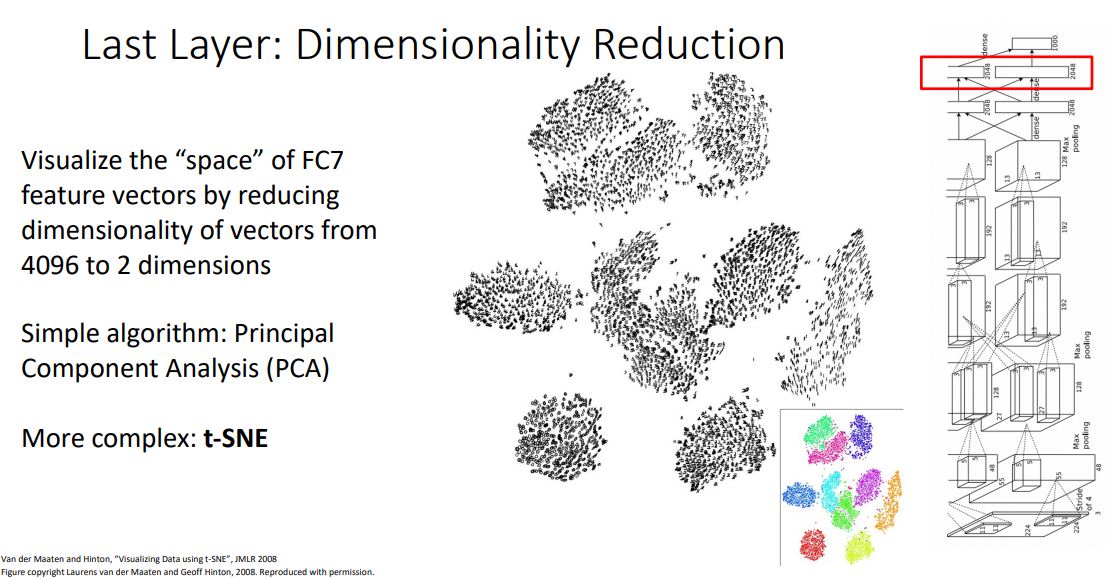
Last Layer : Dimensionality Reduction
-
이러한 feature space에서 적용해볼수있는 또다른 방법으로는 몇몇의 dimensionality reduction algorithms을 사용해보는 것 이다.
-
FC-7의 4096-dimesional를 2-dim과 같이 low-dim space로 변환시켜 우리가 구분할수 있게끔 만들어준다.
-
ML에서 흔히 볼 수 있는 algorithm인 PCA를 적용하여 선형적으로 dimesion을 축소해볼 수 있다. (또다른 인기있는 dimensional reduction algorithm인 t-SNE를 적용해 볼 수도 있다(non-linearity reduction 방법))
-
위 그림은 10class를가진 MNIST를 학습한 model에서 모든 test-set image를 t-SNE를 적용하여 2-dim에 point로 나타낸 모습이다.
- 이때 reduction결과가 10개의 cluster로 나눌수 있는 모습을통해 학습을 통한 model의 feature space가 일종의 identity of the class를 encoding하였다고 생각해 볼 수 있다.

-
위 그림은 MNIST를 학습시킨 model이 아닌 ImageNet을 학습시킨 model의 feature space를 dimensional reduction시킨 모습이다.
-
위 그림으론 이해하기 어렵지만 아래 링크의 high-resolution version을 통해 살펴보면 different sorts of semantic categories에 대응하는 differnet region of space를 살펴볼 수 있다고한다.
-> high-resolution version으로 줌해서 살펴보면 각각 class들이 cluster를 이루는 것을 볼 수 있다.
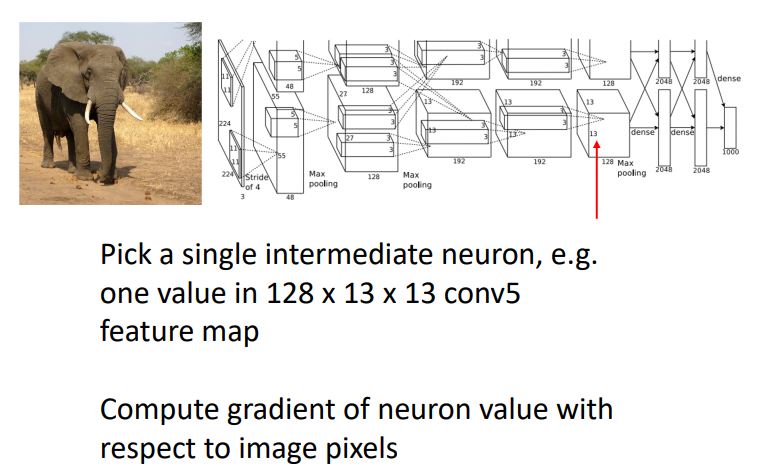
Visualizing Activations
- Neural net model 중간 layer의 weights를 시각화하는 것은 어렵기 때문에 다른 방법으로 CNN의 중간 conv layer의 activation map을 시각화 해 볼 수 있다.
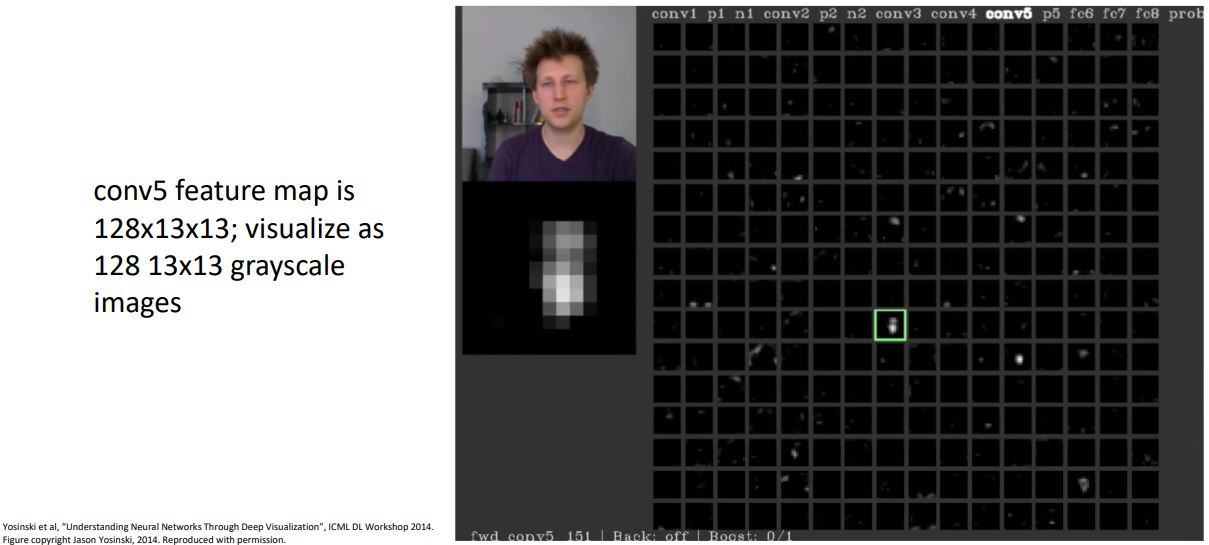
-
위 그림은 conv5 layer의 128x13x13 activation map을 각 channel별로 gray scale로 시각화 한 것으로 이들중 가운데 초록색 박스로 나타낸 activation map을 살펴보게되면 각 positional 값들이 input image의 얼굴에 대해서 높은 activation값을 갖는것으로 보여지며
-
위와같이 다른 이미지 별로 각 layer의 activation map을 살펴봄 으로서 각각의 layer의 filter들이 무엇을 나타내고 있는지에 대한 직관을 살펴볼 수 있다.
-
여기서 대부분 filter의 값들이 black에 가까운 이유는 ReLU non-linearlity를 거쳤기 때문이라고 한다.
-
Maximally Activating Patches
-
또 다른 방법으로 위 처럼 random image 혹은 random filter에 대해서 visualize해보는 것이 아닌 neural net내부의 다른 filter간 Maximally activation값을 찾는 것이다.
-
한 layer의 한 filter를 선택해 모든 training set, 모든 test set이미지의 patch를 기록하고 highest responses를 찾는 것이다.

-
쉽게말해 위 그림처럼 fix된 layer에서 fix된 channel의 가장큰 activation이 큰 neuron을 모아 visualization해보니 각 카테고리별로 해당 layer의 각각의 channel이 image에서 중요하게 생각하는 부분이 비슷하다는 것을 알수있다.(sequence data에서 attention이 적용되는 mechanism과 어느정도 비슷하다고 생각이 든다)
-
이때 위 visualization grid의 한 row의 각 column인 element는 patch에서 매우 높은 responce를 보인 것들이다.
-
결국 어떤 neruon에서 큰 activation을 보이는지는 중요하지 않고 각 layer의 각 channel에서 카테고리별로 attention하는 부분이 비슷하다 라는 것을 생각해 볼 수 있다.
-
아래의 grid는 좀더 깊은 network에서 visualize한 못습으로 한 neuron의 receptive field 가 크니 input image에서 넓은 영역을 보고있다.
* 아직 명확한 intuition을 얻지 못한 것 같아 추후에 해당 논문을 찾아봐야 할 것 같다.
-
Which Pixels Matter?
- 또 다른 방법으로는 input image에서 어떤 pixel이 실제로 model이 중요하게 생각하는지 알아보는 것이다. 다시말해 이미지의 어떤 부분이 network가 분류를 위한 결정의 근거가 되는지 알아보는 것이다.

-
위 그림처럼 이미지의 특정 부분을 gray값 등으로 변환시키는 masking을 모든 position별 shifting시켜 (sliding window마냥) score(probability)를 구하여 Saliency map을 도출하고 이를통해 어떤 부분의 pixel들이 가장 판단에 영향을 미치는가를 볼 수 있다.
-
이때 특정 부분을 masking하면 score(softmax에서 probability)가 급격히 떨어지는 (붉은색) 부분을 heat map을 통해 살펴 볼 수 있고 이러한 부분들이 중요한 부분임을 나타낸다.
Saliency via Backprop

-
또다른 Saliency map을 도출하는 방법은 한 image의 class score값을 backprop시켜 어떤 pixel에서 activation이 있는지 살펴보는 것이다.
- 이미 학습된 weights 값들은 변하지 않지만 test image를 backprop시켜보면 어떤 pixel의 activation이 살아나는지 볼 수 있다.
-
여러 이미지에대해 살펴보면 다음과같이 나타난다.

- 해당 예시는 단순히 이러한 테크닉이 있다라는 것만 소개하기 위함이고 실제 example에서는 위와같은 의미있는 결과를 보이지는 않는다고 한다.

- 위 그림처럼 Saliency map에서 GrabCut방법을 사용하면 따로 label을 주지 않고도 un-supervised로 segmentation 작업을 학습할 수 있다는 장점이 있다고 한다. 하지만 역시 supervised보단 정확도가 매우 떨어진다고 한다.
Intermediate Features via (guided) backprop
- Backprop을 통해 살펴보는 또다른 방법으로 guided backprop이 있다.
- 이전에 class score를 backprop시킨 것과 다르게 intermediate feature를 backprop시켜 image의 어떤 부분이 class score가 아닌 선택한 singel neuron에 영향을 주는지를 살펴보는 것 이다.
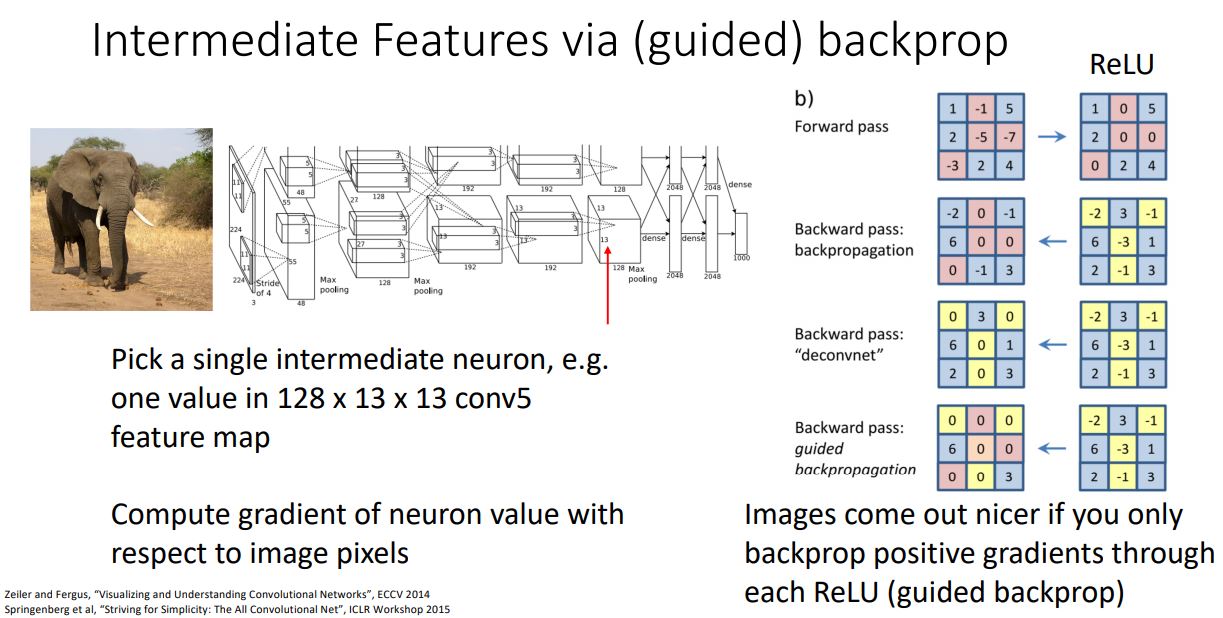
-
이때 backpro과정에서 일반적인 backprop을 수행하는 것이 아니라 조금 다른 과정을 거치게 된다.
-
위 그림처럼 forward pass과정에서 ReLU를 거치면 negative값들이 zero가 되기 때문에 backprop에서도 negative upstream gradient를 죽여 zero로 만든다. (upstream gradient에 forward pass와 같은 masking을 하겠다는 것)
- 이러한 과정을 통해 깔끔한 visualize가 된다고 한다.
-
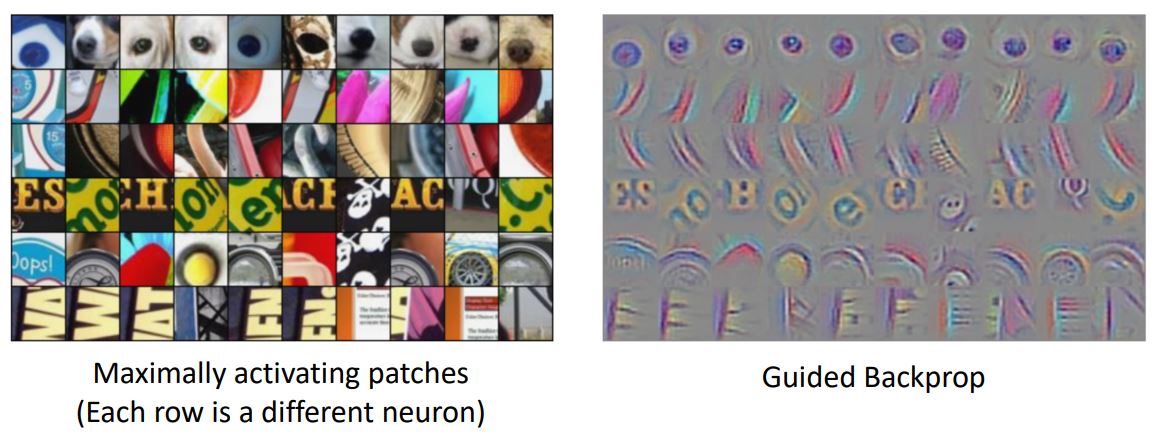
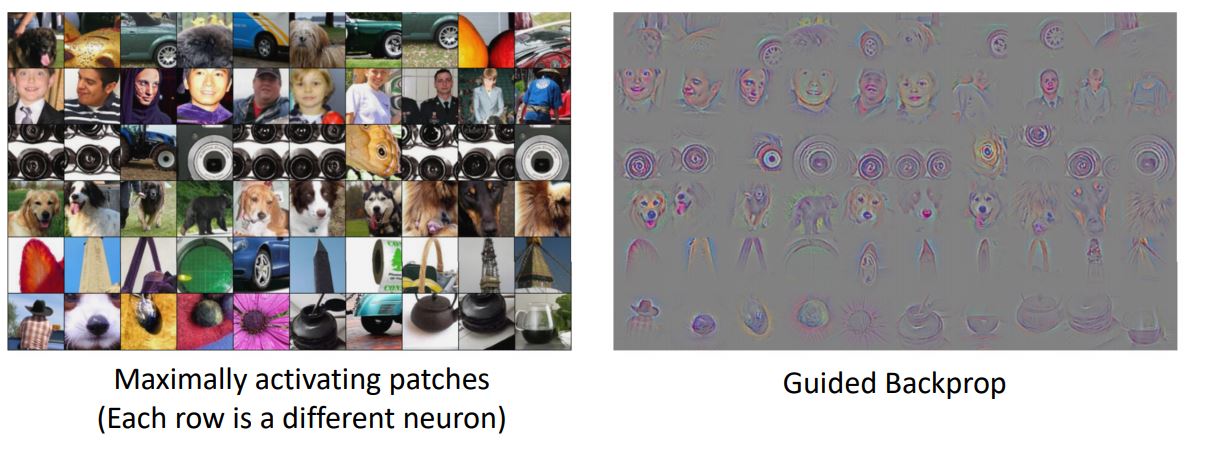
-
위 결과를 살펴보니 Maximally activating patches에서의 각 neuron이 어떤 pixel에 영향을 받는지를 살펴보면 동일한 부분을 살펴보고 있다는 것을 알 수 있다.
-
이러한 방법은 test image 혹은 input patch의 제한된 부분이 (or pixel이) 특정 neuron에 얼마나 영향을 미치는가를 나타낼 뿐이다.
-
그렇다면 모든 possible image에서 어떤 image가 해당 neuron을 maximally activate시키는지를 알수있는 방법은????
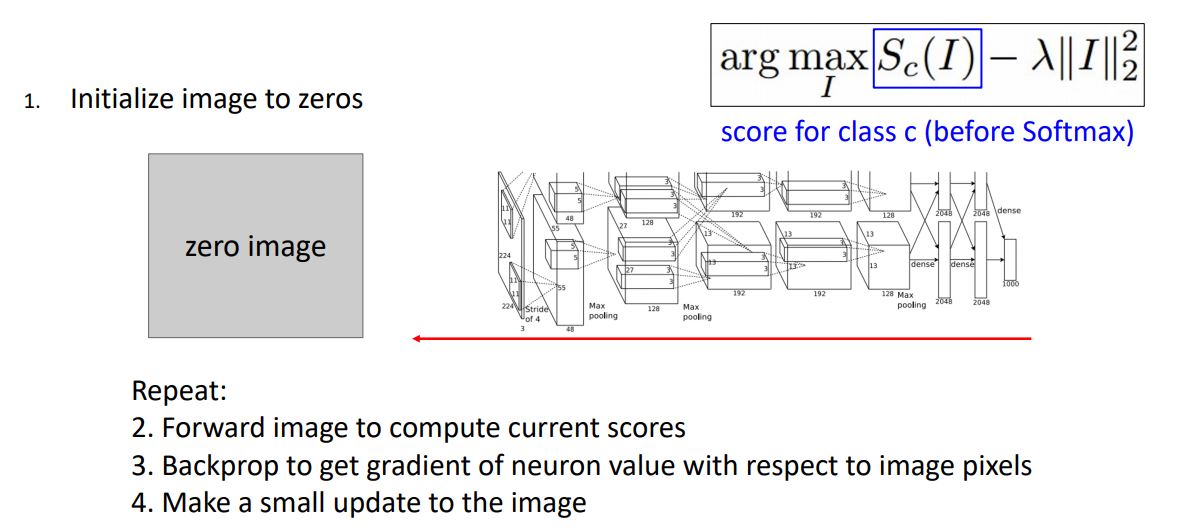
Gradient Ascent

-
우리가 원하는 것은 특정 neuron이 maximized value를 갖게하는 새로운 synthetic image를 생성하는 것이다.
-
위 그림의 수식에서 는 우리가 선택한 neuron이 maximally activate값을 갖게하는 image이며
-
f(I)는 우리가 선택한 neuron의 value이고
-
R(I)는 일종의 regularizer로 이미지를 생성할 때 natural하게 만들어주게된다.
-
- 이러한 Gradient Ascent는 weights를 훈련하는 것이 아닌 선택한 neuron이 maximally activation 값을 갖는 혹은 클래스 스코어를 최대화 시키는 image(의 pixel)을 학습하는 것 이다.
-
Gradient ascent를 통해 이미지를 생성하기 위해 일단 input 이미지를 zeros, random noise등으로 initialize시킨다.
-
그리고선 image를 network에 forward시켜 하나의 neuron값 혹은 score를 구하고 각 pixel에 대한 해당 neuron 혹은 score의 gradient를 계산하기 위해 backprop시킨다.
-
이러한 과정을 반복하여 score 혹은 neuron의 activation값을 최대화 시키게끔 pixel을 update한다.

-
이때 일반적인 gradient descent에서는 weights가 overfit하는 것을 막기위해 penelty를 주는 방식으로 regularization term을 사용하는 반면에 Gradient ascent에서는 반대로 생성되는 이미지들이 학습된 model에 overfit하는 것을 막기 위함이다.
-
하지만 위와같은 결과는 natural해보이지 않는다. 그래서 regularizer를 변형하여 이용해 보면 다음과 같다.

- 사람들은 생성되는 이미지가 좀더 네츄럴해 보이도록 여러 regularizer들을 연구해왔고 그 방법 중 하나가 위와같이 l2 norm 에다가 주기적으로 Gaussian blur를 적용하고 pixel 을 cliping하는 방법이다.

-
이 전 그림처럼 socre에 대해 gradient ascent를 하는 것이 아닌 network 내부에서 각 layer, neuron에 maximally activation을 위한 gradient ascent를 해주면 위 그림과같다.
-
위 같은 방법 이외에 여러 논문들에서 효과적인 regularizer를 연구하여 훨씬 네츄럴한 이미지를 생성하기위한 방법들이 제시되고 있음을 아래그림을 통해 볼 수 있다.



- 위 그림처럼 여러 paper에서 좀더 realistic한 이미지를 생성해내는 모습을 볼 수 있지만 network이 무엇을 하는지 visualize하기 위한 본질에서 벗어나 굳이 이렇게까지 해야하나 싶다.
Adversarial Examples
-
Adversarial(fooding) image를 생성하는 방법은 아래와 같다.
- 임의의 이미지를 골라
- 해당 이미지의 다른 카테고리를 선택 후
- 선택한 카테고리의 class score를 gradient ascent를 통해 maximize 시켜 이미지를 약간 변형시킨다.

- 이러한 adversarial 기법을 통해 위 그림과같이 코끼리를 코알라로 자신있게 classify 하게끔 network를 속일 수 있는데 이때 pixel을 아주 약간 변형하였기에 거진 차이가 없다.
Feature Inversion
- Gradient ascent를 활용하여 network가 뭘하고 있는지 이해하는 또 다른 방법으로 Feature Inversion이 있다.

-
Feature Inversion은 Gradient ascent를 통해 test set으로부터 주어진 Image를 forword하여 얻은 feature()와 새로운 image의 feature vector()간의 차이를 줄이는 image를 생성하는 것 이다.
- 이때 두 feature는 동일한 layer의 feature representation끼리 연산한다.
- 또한 수식을 보면 이전에 Gradient ascent에서 본 maximally activation을 위해 argmax를 사용하는 것이 아닌 두 feature의 거리를 최소하 하기 위하여 argmin을 사용한다.

-
위 예제를 통해 우리는 두 이미지를 Feature Inversion시키면 각 layer에서 ReLU를 통해 어떤 feature information이 보존되거나 버려지는지 살펴볼 수 있다.
- 낮은 layer일 수록 raw input image와 유사하다는 것을 볼 수있는데 뭔가 와 닫지는 않는다...
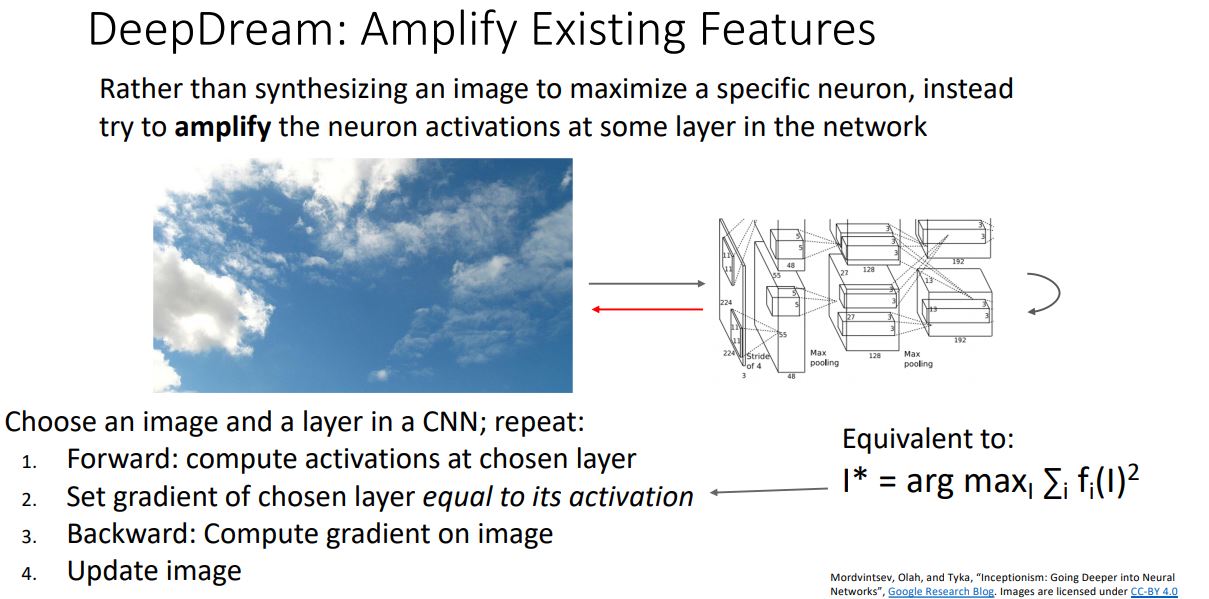
DeepDream
- DeepDream은 이미지의 특정 feature를 maximize하는 대신 amplify 시키는 것 이다
-
DeepDream은 다음과 같은 메커니즘을 갖는다.
- 이미지를 CNN에 forwarding시켜 특정 layer에서 feature를 추출한다.
- 해당 layer의 gradient를 해당 activation value로 설정해준다.
- 설정된 gradient를 backprop시키고 image를 update시킨다.
-
위와같은 과정을 통해 특정 feature의 activation을 훨씬 크게 작용하도록 image를 변형하는 것 이다.
- 위 왼쪽하단 수식에서 볼 수 있듯이 해당 layer의 feature의 l2 norm이 maximize되도록 이미지를 synthesizing하는 것 이다.
- 위 그림의 하늘 이미지를 실제로 DeepDream network에 집어넣어 보자

- 위 그림은 shallow layer의 feature를 amplifing시킨 것 으로 보다시피 edge 정보로 보이는 feature가 amplify된 것을 볼 수 있다.

- 좀더 higher layer의 feature를 살펴보면 해당 network가 동물 dataset을 학습한것 처럼 보인다.
- 실제로 ImageNet을 학습시킨 model이라고 한다.

- 이러한 deepdream을 엄청나게 많이 돌리면 original image에서 많이 벗어나 위와같은 요상한 그림이 나타나게 된다.
Texture Synthesis
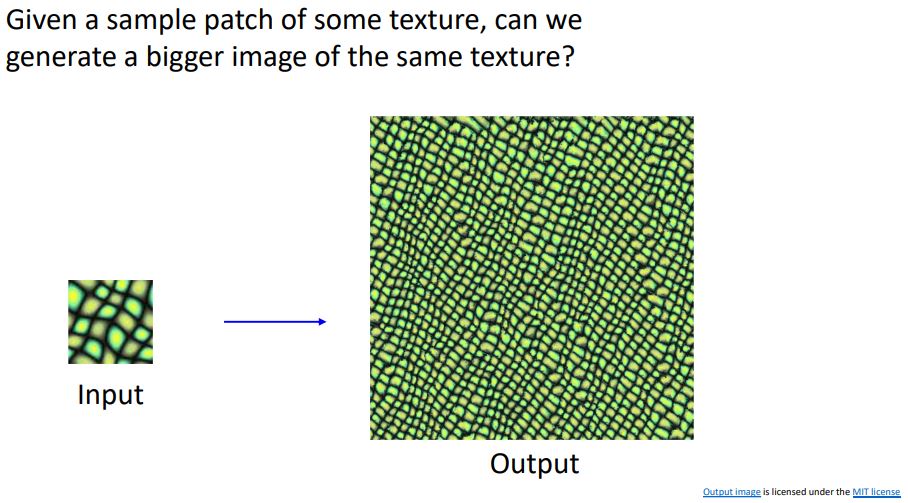
- Texture Synthesis는 computer graphics분야의 classical한 idea로 규칙적인 texure를 가진 작은 input image로 동일한 texture구조를 갖는 큰 output image를 만드는 것 이다.
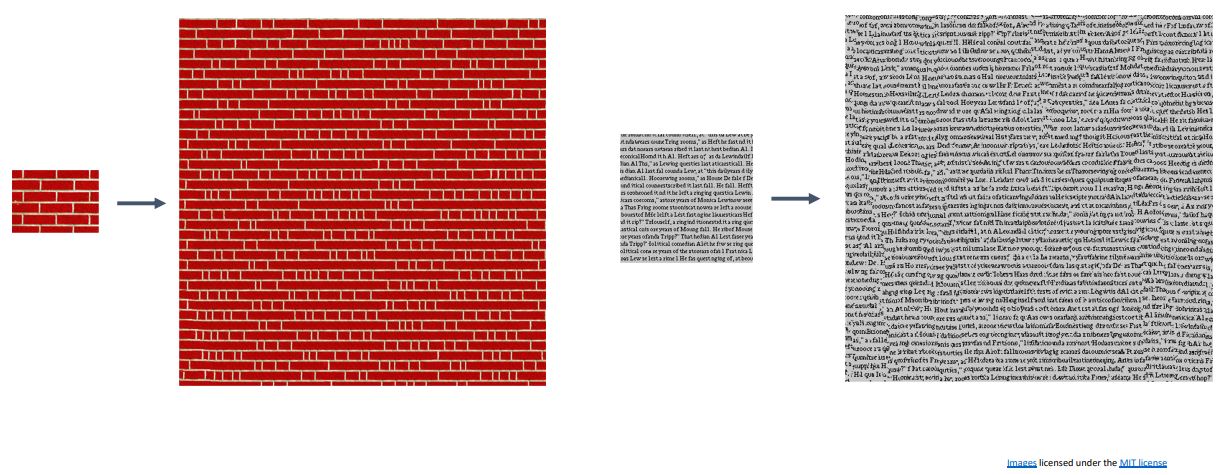
-
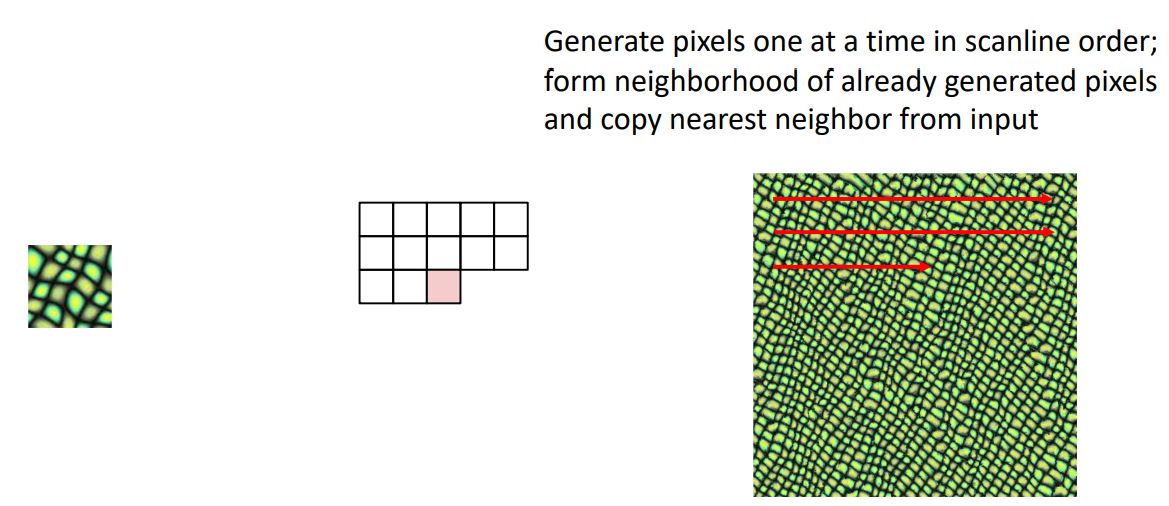
Nearest Neighbor algorithms을 활용하여 texture synthesis를 통해 위와같이 neural net없이 좋은 성능을 내는 것을 볼 수 있다.
-
이러한 texture synthesis problem을 neural net에 적용시켜보자.
Gram Matrix
- Gram Matrix 를 도입하여 texture synthesis problem을 해결한? 방식은 gradient ascent를 활용한 Feature Inversion 괴 비슷한 idea를 갖는다 한번 살펴보자.
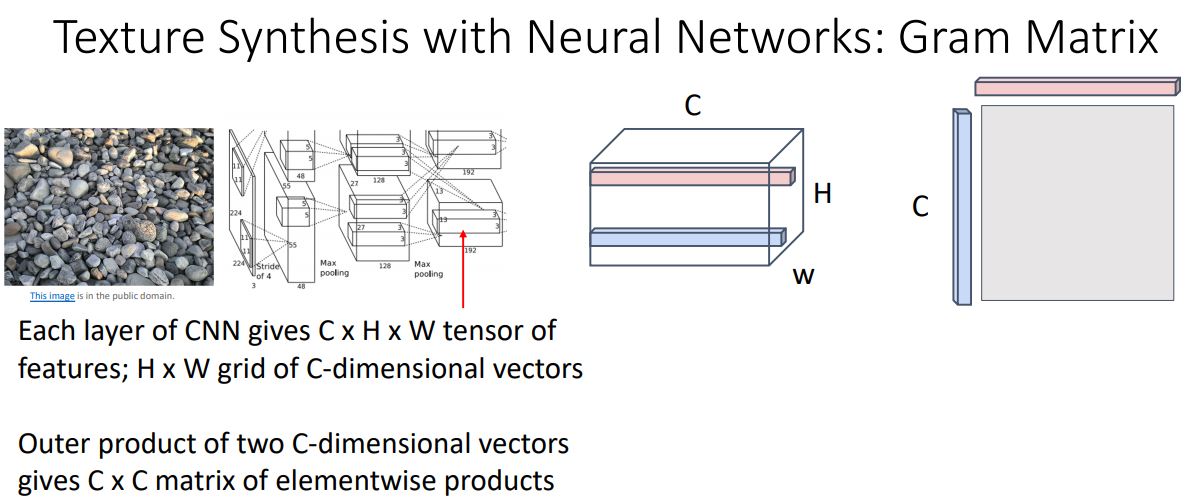
-
Local texture information을 capture하는 Gram matrix는 다음과 같은 구조로 얻어진다.
- 우선 target image를 CNN에 forwarding시키고 특정 layer의 특정 3-dim feature volume((CxHxW)의 activation map)을 추출한다.
- 이 feature volumn에서 두개의 다른 point를 선택해 두 vector(위 그림에서 분홍색 파랑생)을 outer product를 계산하여 CxC matrix를 만든다.
- 모든 가능한 blue and pink pairs들에 대해 위와같이 반복한다.
- 이 모든 outer product의 결과인 matrix에 평균때려 CxC Gram Matirx 를 얻는다.
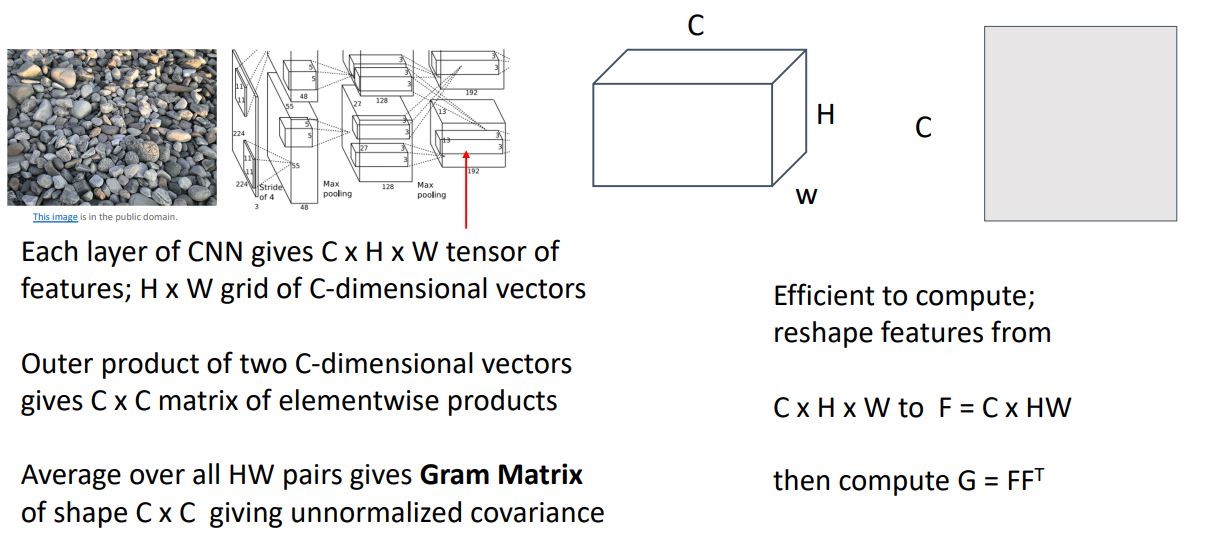
-
이러한 Gram Matirx 는 feature vector간 unmormalized covariance을 나태내게 되고, 기본적으로 spatial information을 날려버린다(이미지의 saptial point에 평균때렸기 때문).
-
그래서 Gram Matirx 는 feature들이 서로 correlated되었는지를 나타내게 된다(co-occurrence를 나타낸다고도 함).
-
Gram Matirx를 사용하는 이유는 위 그림 의 오른쪽 아래의 수식에서 보다시피 matrix mutiplication을 통한 computationally efficient를 위함이라고 한다.
-
Texture discrptor인 Gram Matirx 는 image의 다른 position에서 어떤 feature들이 tend to co-occur인지를 말해준다.
- 쉽게말해 서로 다른 position에서 동시에 활성화되는 특징이 무엇인지 나타내준다.
- 이러한 Texture discrptor를 가지고 target image에 match하기 위해 gradient ascent를 사용하여 texture synthesis을 수행해 보자.
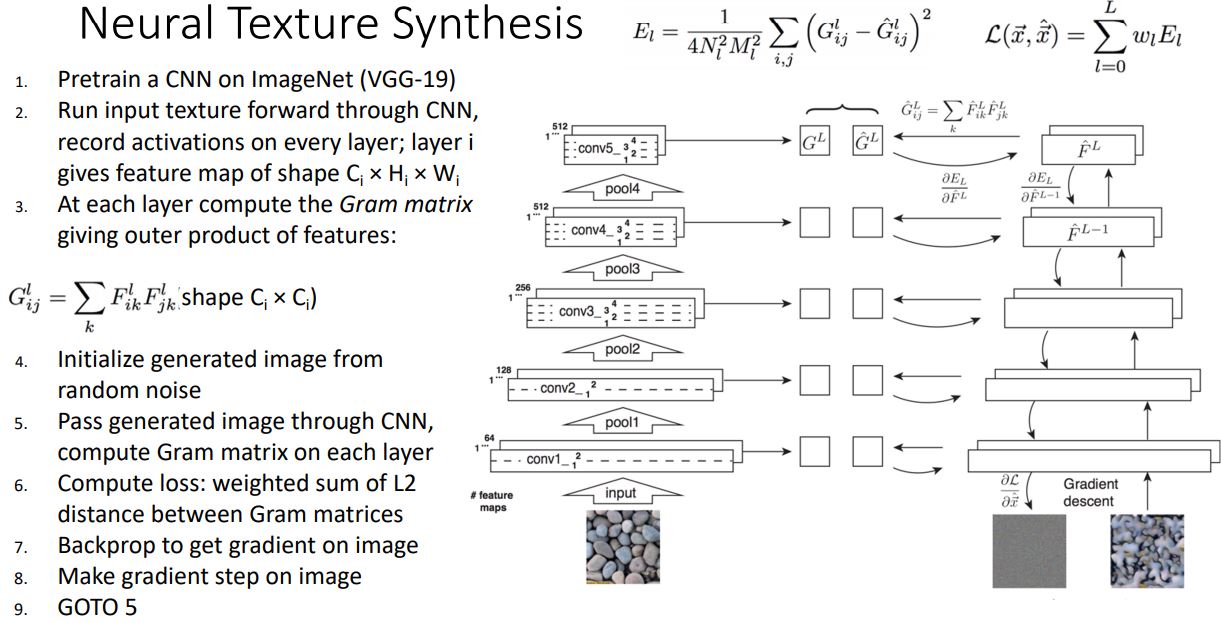
-
실제로 neural net을 통해 어떻게 동작하는지 살펴보자.
-
- VGG와 같은 pre-trained CNN을 가죠온다
-
- Target texture image를 forwarding시켜 매 layer에서 feature map을 기록하고
-
- 이 map들을 가지고 gram matrices를 계산한다.
-
- 생성할 image를 random noise로 초기화 시키고
-
- 이 nosie 이미지를 동일한 network에 forwarding시켜 마찬가지로 매 layer에서 Gram matrix를 계산한다.
-
- 같은 layer의 target image와 생성된 image의 Gram matix간의 euclidean distances(L2)를 weighted sum해주어 loss를 구해준다.
-
- 계산된 scalar loss를 backprop시켜 pixel별 gradient를 계산하고 update시켜준다(gradient ascent).
-
- Repeat
-

- 위 그림의 예제를 통해 Texture Synthesis가 higher layer에서는 input textue의 큰 feature(texture)들을 잘 재구성하는 것을 볼 수 있다.
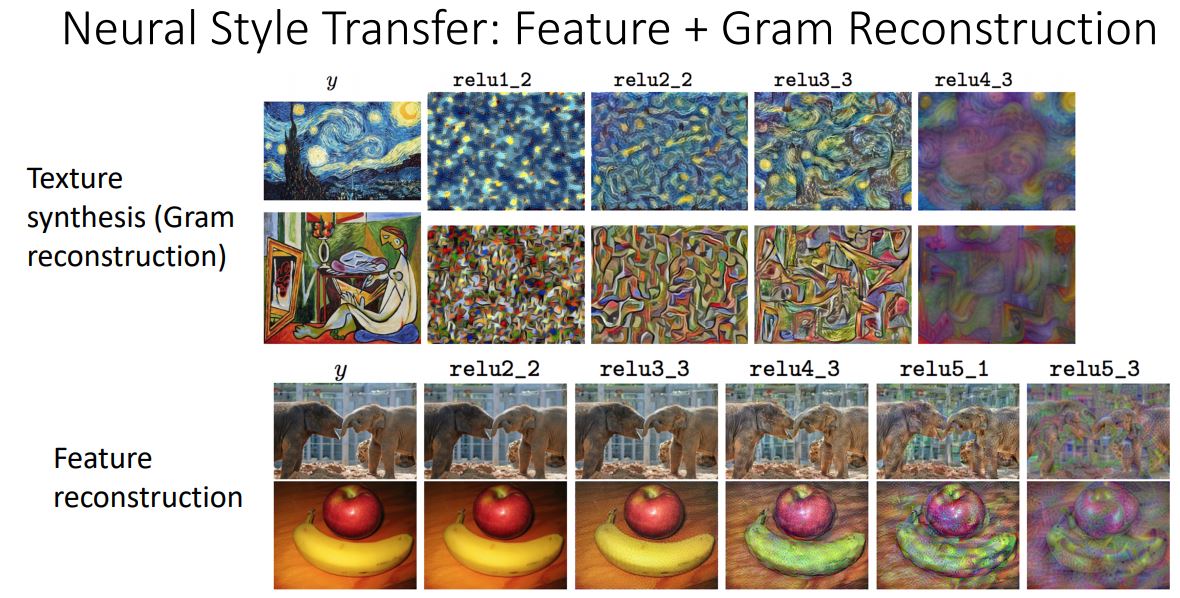
- 이러한 Texture Synthesis를 artwork에 활용하여 이들을 Feature Inversion(Feature Recinstruction)에 접목하면 어떤 결과가 나올까?
Neural Style Transfer
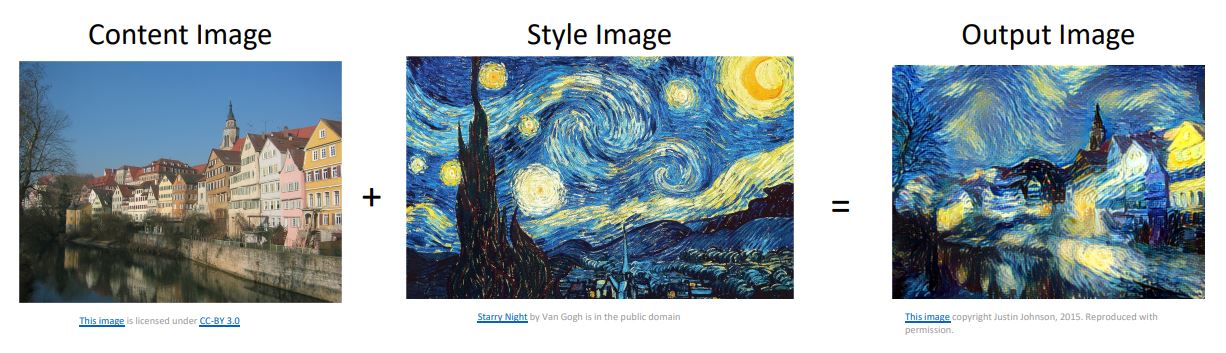
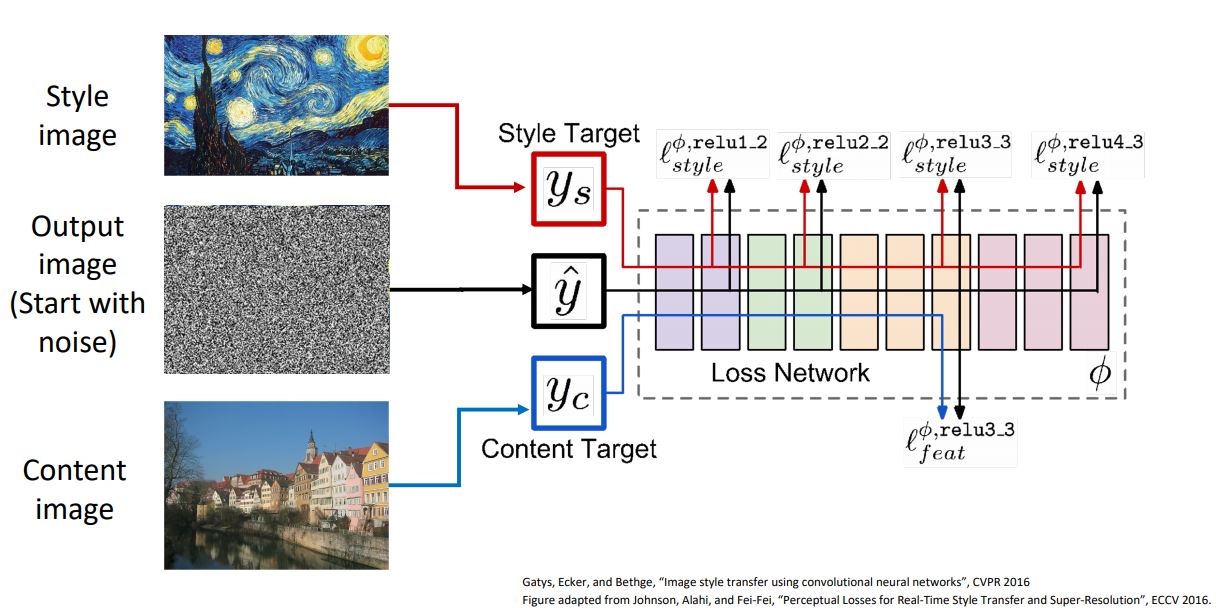
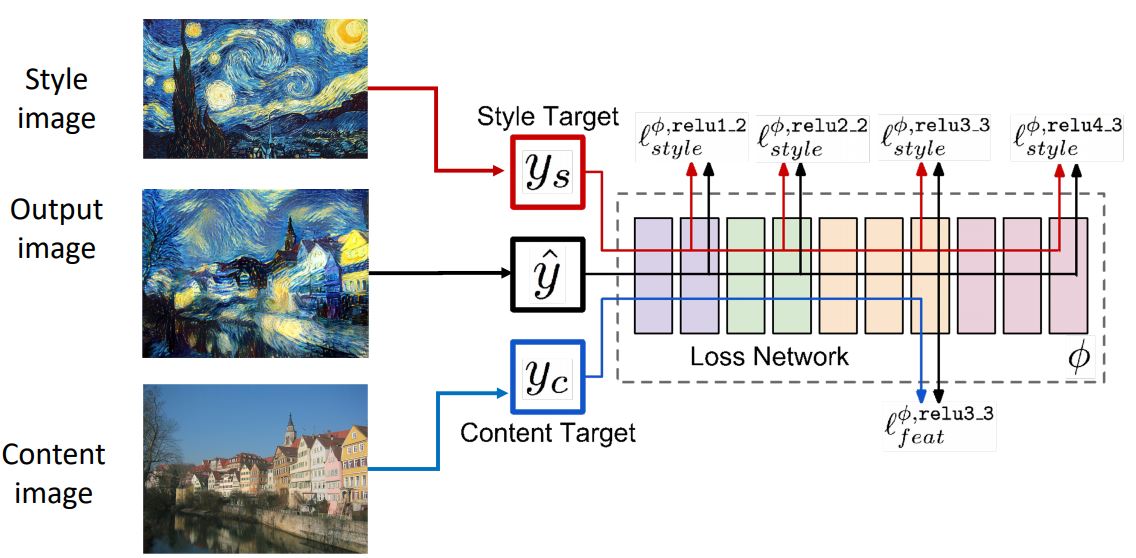
- 위 그림처럼 content image의 (high layer의)feature와 style image(artwork image)의 Gram matirces를 matching시켜 새로운 output image를 생성할 수 있다. 이러한 것을 Style Transfer라고 한다.
-
위 그림에서 Content Image는 네트워크에게 output 이미지가 어떻게 생겨야하는지를 말해주고 Style Image는 output 이미지의 텍스쳐가 어때야하는지를 말해준다.
-
이때 Style image 의 gram matrix loss와 content image 의 feature reconstruction loss 두가지 loss를 사용하는데 이 두가지 loss를 어떻게 조합하여 gradient ascent를 통해 output image를 생성할지가 중요하다.
-> Object Detection에서의 multitask loss와 동일한 문제.

- 앞서 설명하였던 것 처럼 두가지 loss에 대한 trade-off가 존재하는데 weight를 어떻게 조정하냐에 따라 위와같이 output이 어디에 fit되는지를 조절할 수 있다.

- 우리가 tuning해야하는 또다른 hyperparameter로 style image를 어떻게 resize하냐에 따라 위와같이 output에 다른 style image의 다른 feature가 적용될 수 있다.

- 우리는 또한 위 그림처럼 multiple style imags를 적용해 볼 수 있다.
-
하지만 이러한 style transfer는 gradient ascent하기위한 forwarding과 backwarding이 매우 많이 일어나기 때문에 매우 느리다.
-
이러한 문제를 해결하기위해 VGG가 아닌 style transfer를 위한 새로운 network가 필요한데 Justin Johnson이 논문을 통해 제시했다고 한다 ...ㅎㅎ
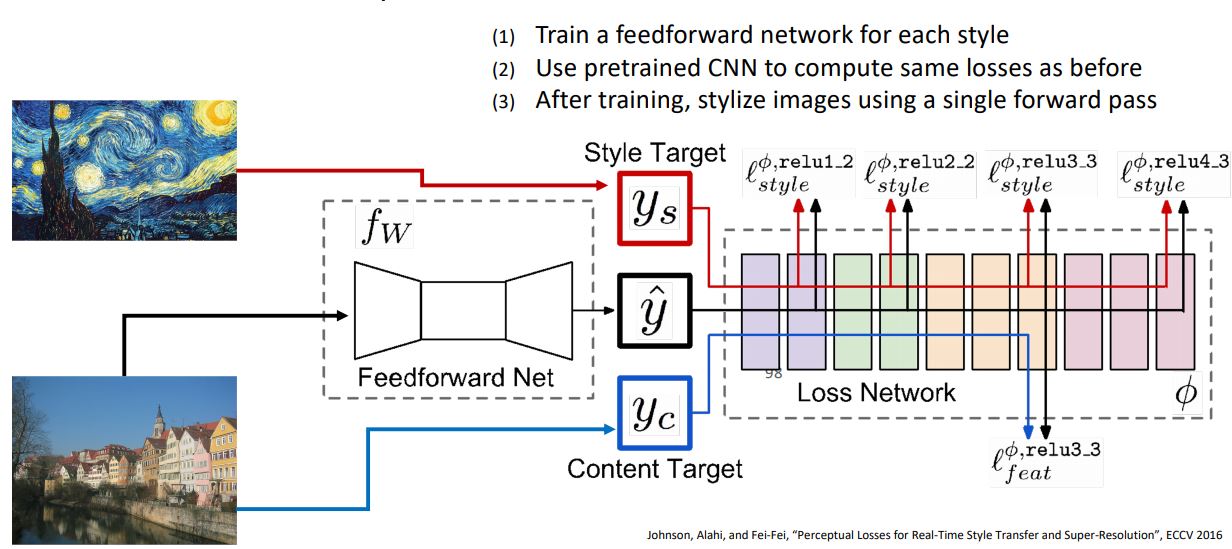
- 자세한 설명은 생략하지만 위와같은 단일 network를 통해 학습은 오래 걸릴 수 있으나 스마트폰을 통한 실시간 영상에서도 적용할 수 있을 정도로 빠르다고 한다.
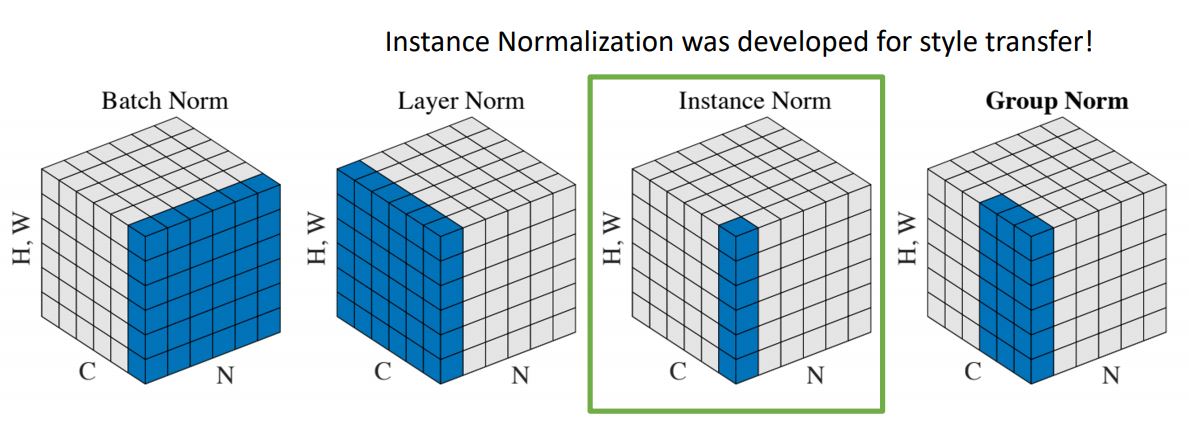
- 또한 Instatnce normalization을 BN대신에 사용하면 더 좋은 결과를 낸다고 한다.
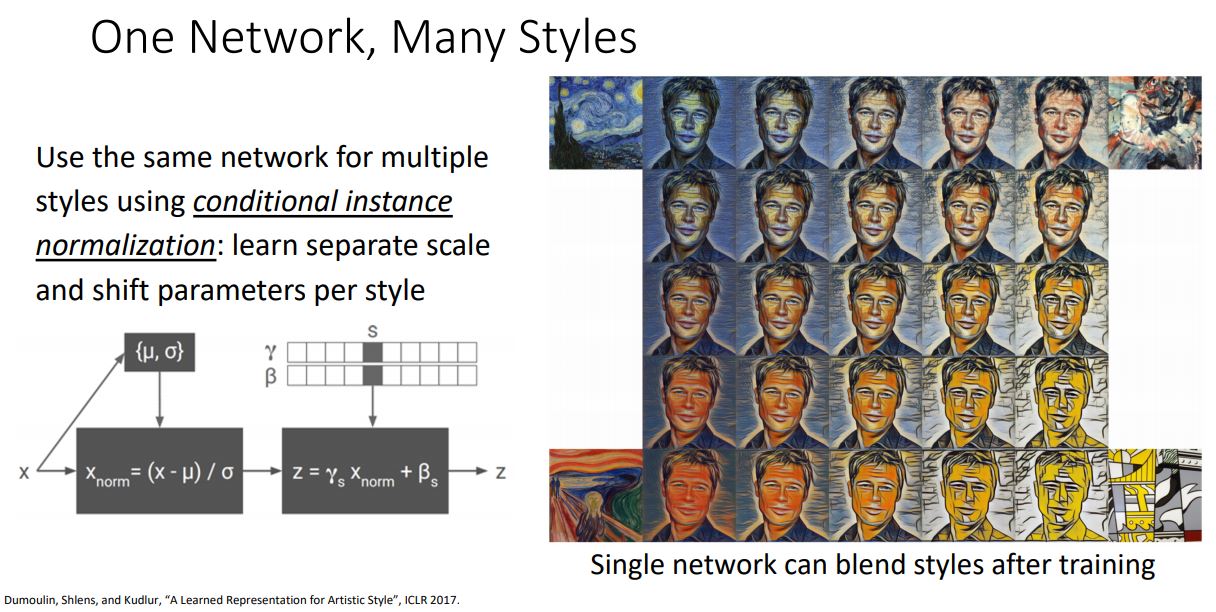
- 또한 contitional instance normalization을 통해 하나의 network에 여러 style image를 집어넣어 style blending 할 수 있다고 한다.
Outro
-
이번 강의에서는 Neural Net(CNN) 내부의 feature들을 여러 방식으로 visualization하여 network가 무엇을 학습하여 기억하게 되는지 이해함 으로서 상당한 Intuition을 얻게 되었고
-
또한 이러한 테크닉들을 deep dream, style transfer와 같은 application으로 활용하는 것을 살펴 봄 으로서 이제야 딥러닝을 하는구나 라는 생각이 들었다.

언제 이런걸 다 보고 정리하셨나요...대단합니다