[EECS 498-007 / 598-005] 3. Linear Classifiers

Lec3. 에서는 이 전 단원에서 다뤘던 다양한 image classification problems을 해결하기 위하여 다양한 타입의 linear classifier들을 다룬다.
linear classifiers는 보기에는 간단해 보이지만 NN, CNN을 구성하는 가장 기본적인 알고리즘이기에 정확히 이해하는 것이 중요하다.
Parametic Approach
-
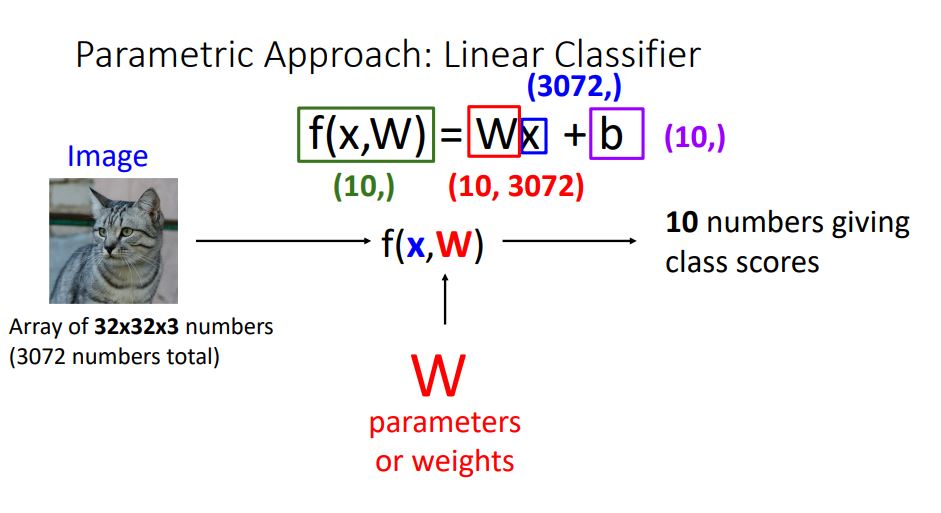
f(x,W) = Wx + b 는 linear classification의 가장 기본적인 함수 형태이다.
이 함수는 image의 pixel값인 x에 parameter W를 곱하여 각 클래스의 socre를 갖는 10개의 숫자를 반환해주는 형태이다. -
x 는 CIFAR10 dataset을 사용하는 input image를 뜻하고 (32x32x3) 형태를 가졌기에 총 pixel수인 3072의 스케일을 갖는다.
-
W는 learnable wights인 parameter들로 각 픽셀들에 곱해줄 값들 이다.
-
b 는 bias라고 부르며 Wx의 결과에 더해주기 위해 10 element를 가지는 벡터이다.
간단한 예시를통해 위의 개념을 살펴보려한다.
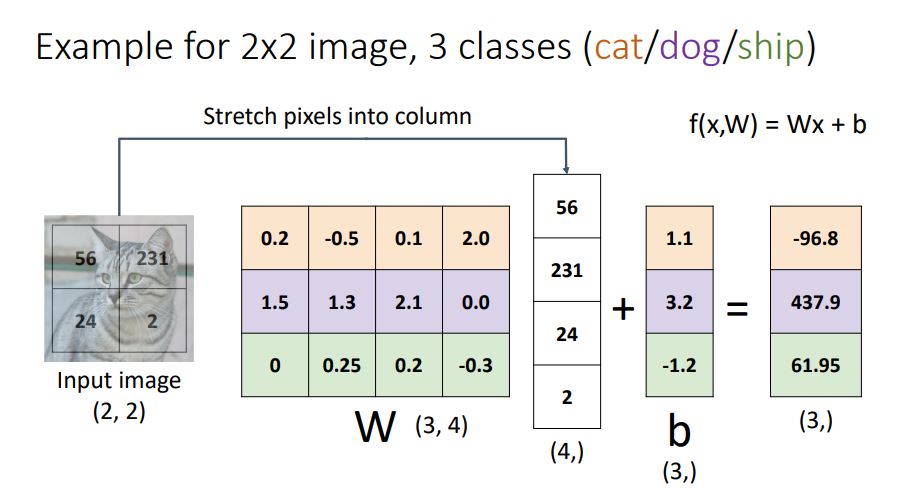
그림의 예시를 3가지 viewpoint를 통해 살펴보자.
1. Algebric Viewpont
input image는 2 by 2 형태의 grayscale 이미지로 4개의 pixel을 갖는데 이것을 4개의 element를 갖는 column vector 형태로 펼쳐준다.
3개의 category에 대해 분류하기 위하여 x에 곱하여줄 3 by 4 matrix가 필요하며 그림에서 색으로 표현되는 class들은 각각 고양이, 개, 배를 나타낸다.
각 class들의 weights와 input image의 pixel값들을 각각곱한후 더해주기위하여 3x4 matrix인 W와 4x1 vector인 x를 dot poduct시켜 나온 3x1 vector에 동일한 형태의 3x1 vector인 b 를 더해주어 각class의 score를 elements로 가진 3x1 vector를 구해주는 형태이다.
*cat score인 -96.8 을 구하는 방법
W의 첫번째 row 와 image의 각 pixel 값을 곱하여 더해준다
: (0.2 * 56) + (-0.5 * 231) + (0.1 * 24) + (2.0 * 2) + 1.1 = -96.8

위의 그림처럼 (bias를 무시하고 보았을때) image에 scalar scaling을 취하면 score도 동일한 scalar곱이 취하여 나오는 형태임을 보았을때 linear classifier는 linear하게 예측한다는 것을 알 수 있다.
2. Visual Viewpoint
이전의 Matrix dot product와 bias를 합해주어 3x1 score vector 를 뽑아낸 형태를 각각의 클래스 관점에서 살펴본다.
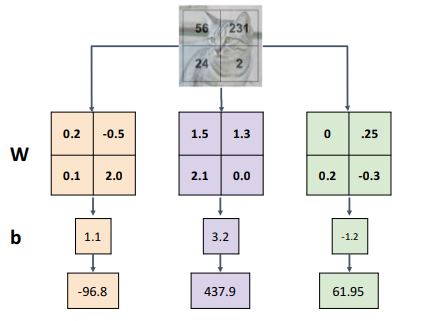
이전의 W matrix의 각 클래스 별 weights를 나타내는 row들을 input image와 동일한 2x2 matrix 로 reshape 하여 dot product하고 bias vector도 element를 뽑아서 각각 더해주어보자.
이때 w 에해당하는 matrix를 visualize 하게되면 template matching과 같은 형태로 해석할 수 있고 아래 그림과 같이 보여질 수 있게 된다 .

이때 각 class별 classifier들은 각 카테고리별 이미지 템플릿을 학습한 형태라고 볼 수 있다.
이렇게 visualize한 template들은 좀더 우리가 각 classifier들을 직관적으로 바라볼 수 있게하는데, 위 그림의 템플릿들을 보게되면 horse class의 템플릿이 말의 머리가 두개로 나오는등 linear classifier는 각 클래스별 단 하나의 template만 가지기때문에 각 이미지의 여러 다양한 상황들을 대표하지 못한다는 것을 알 수 있다.
3. Geomatric Viewpoint
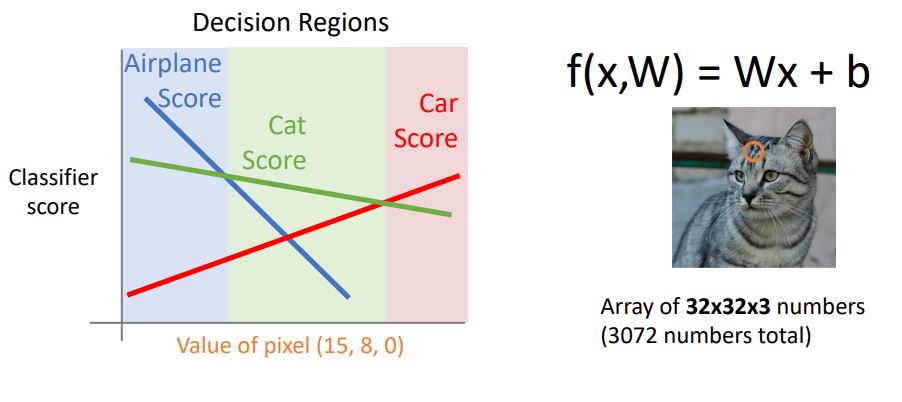
위 그래프의 x축은 image의 single pixel 값을 나타내고 y축은 그에따른 classifier socre를 나타낸다.
linear classifier 가 Wx + b 형태의 linear function이니 classifier score가 각각의 pixel 값들에 따라 linear하게 변하게된다.
위의 예시와같은 single pixel에 대한 관점을 2개의 pixel로 넓혀 살펴보자.
![]()
위의 그래프에서 각 class의 socre는 그려진 해당 line에서 orthognal하게 증가 할 것이며 그 안에 template이 있을 것이다.
이 그래프를 Hyperplanes상에 표시하면 아래와같다.
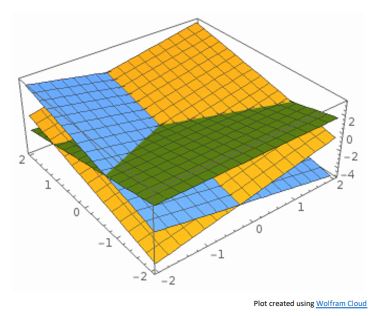
처럼 2개의 pixel에대한 socre space도 직관적으로 다가오지 않는데 linear classifier에 전체 이미지를 취해준다면 매우 큰 high-demensional space로 template이 표현 될것이고 매우 복잡해질 것이다.
지금까지 linear classifier를 세가지 관점애서 대략적으로 공부해보았다. 여태까지는 주어진 특정 weights 값을 통한 각 클래스들의 socre를 따져보았는데, 사실 임의로 주어진 W값이 좋은결과를 가져오는지 아닌지 모르기에 현재의 W값이 좋은지 나쁜지 정량화 할 방법이 필요하다.
Loss Funtion
loss function은 classifier가 얼마나 좋은지 나쁜지 정량적으로 나타내주는 역할을 한다. 이때 low loss 는 좋은 상태를 나타내며 high loss는 나쁜 상태를 나타낸다.
머신러닝에서의 loss function의 목표는 loss를 낮추는 것이다
* loss function 은 object function 혹은 cost function등 으로 표현하기도 한다.
위와같은 dataset이 주어졌을때 single image에 대한 loss는 다음과같이 표현할 수 있다.
이에따라 전체 dataset의 loss는 아래와 같이 각 image에 대한 loss의 평균으로 아래와같은 식으로 표현 할 수 있다.
* 이는 loss funtion의 한 종류 중 하나로 추상적인 형태이다.
1. Multiclass SVM Loss
Image classification에서 사용되는 loss function의 첫번째 예시로 multi-class SVM loss이 있다.
multiclass svm loss 를 직관적으로 설명하면 다음과 같다.
: "input data에 대한 올바른 클래스의 점수는 다른 모든 점수보다 높아야 한다"
SVM loss에서 correct class의 score에 따른 Loss를 그래프로 그리면 다음과 같다
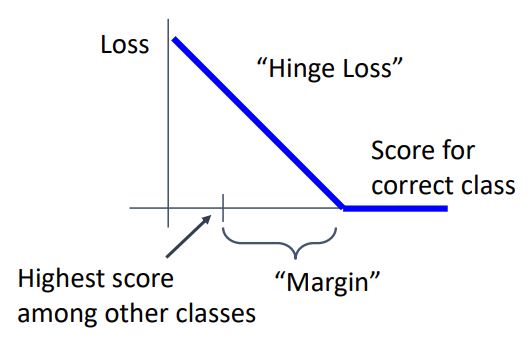
multi-calss svm loss는 correct class의 score가 증가하면서 loss가 0이 될때까지 linear 하게 감소하는형태로 그래프에서와 같이 파란 선으로 나타난다.
correct class의 score를 추적하다 보면 다른 class 중 highest score를 찾을 수 있는데, 그때의 highest score와 correct score의 차이가 margin 이상이 되면 loss가 0이 된다. 즉 score의 차가 margin보다 커지면 good classifier라고 볼 수 있다.
이러한 형태의 loss는 다른 machine learning context에서도 많이 나타나는데 이것을 hinge loss라고 한다
svm loss 를 수식으로 표현하면 다음과 같다
correct class 가 other class 에 1을 (앞서 나온 margin) 더한 것 보다 크면 loss에 영향없는 0으로 계산되고, correct class 가 other class 에 1을 더한 것 보다 작으면 positive값이 loss에 누적되는 함수이다.
말로는 이해하기 어려우니 밑의 간단한 예를 통해 이해하자.
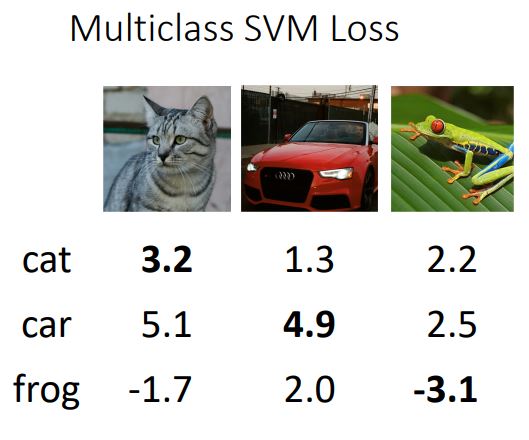
위의 그림에서 3개의 class에 대한 score가 주어진 상태에서 각 input image의 svm loss를 구해보자
먼저 고양이 class에 대한 loss를 구해보면
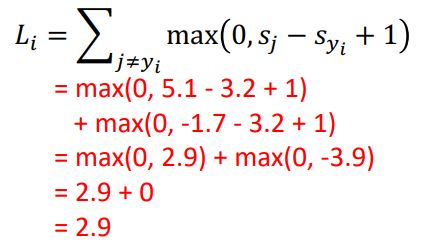
위와같은 과정으로 loss를 구할 수 있다.
다른 calss의 loss를 구하는 과정은 생략하고 총 결과는 아래와 같다.
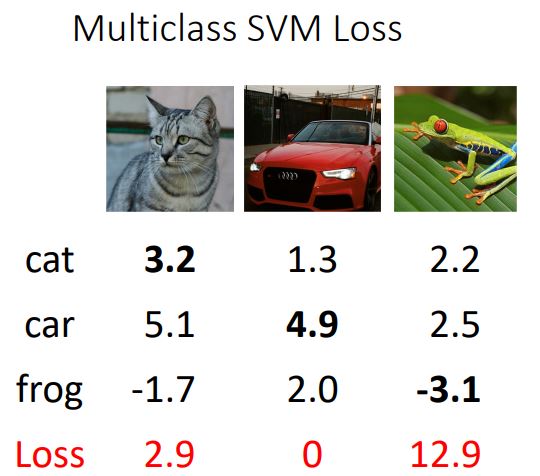
총 loss는 각 class에 average를 계산하여 구해준다.
Q1. 만약 car score가 약간 변하면 무슨 일이 일어날까?
: score를 약간 변화 준다고 하여도 car score가 다른 score보다 훨씬 높기 때문에 margin은 유지될 것이고, 결국 loss는 변하지 않을 것 이다.
Q2. SVM loss가 가질 수 있는 최대/최소값은?
: correct class의 score가 가장 크게되는 경우 모든 training data 에서 loss가 0이 되기에 min값은 0이되고, correct class의 score가 엄청 낮은 음수가 될 수 있기에 max값은 무한대가 될 것 이다.
Q3. 만약 모든 score가 0에 가까운 small random value로 initialize되면 무슨 일이 일어날까?
: 모든 score가 0에 가까운 값을 가지면 correct class의 score와 other class의 score간의 차가 0에 가깝게 될 것이고 svm loss function 에 따라 각각의 loss는 1이 될것이며 correct class 자기 자신을 제외한 다른 모든 class와 loss를 구하였으니 최종 loss는 *class개수(C) -1 이 될 것이다.
Q4. 만약 loss에서 전체의 sum 을 구하는 것이 아닌 mean 값을 구한다면?
: 평균값을 구한다는 것은 손실 함수를 rescale할 뿐이고 score값이 몇인지는 중요하지 않기에 영향을 미치지 않는다.
Q5. 만약 아래와 같이 loss 값에 제곱을 취해준다면?
: loss에 제곱을 취해주게 되면 loss fuction 자체가 바뀌는 것 이기 때문에 loss값 자체가 바뀌게 된다. 0에 가까운 좋은 loss는 더 좋게 바뀌며 값이 높은 좋지 않은 loss는 더 나쁘게 될 것이다.
* 우리가 문제에 따라 error에 대해 얼마나 신경쓰는가, 그것을 어떻게 정량화 할 것인지에 따라 어떤 loss function을 사용할 것인지는 매우 중요하다.
앞서 보았던 3 classes 예시를 다시 보자.
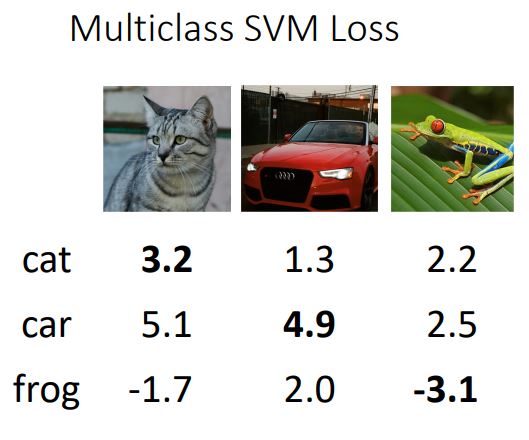
이 예시는 car에 해당하는 두번째 input image의 loss를 보았을때 loss를 0으로 만드는 W는 unique 하지 않고 여러가지가 있을 수 있다는 것을 보여준다.

위 그림은 car class의 original W에 대한 loss와 2W에 대한 loss가 둘다 0이된다는 것을 보여준다.
이처럼 두개의 다른 weight matix가 같은 training data에서 동일한 loss를 가지는 경우가 있는데 이때 두개의 matrix는 test data에서 다른 성능을 보일 수 있기에 training data에 상관없는 추가적인 메커니즘이 필요하다.
Regularization
regularization이란 모델이 training data에서 지나치게 잘 동작하지 않고 test data에 좀더 잘 동작하게 하기 위한 것이다.
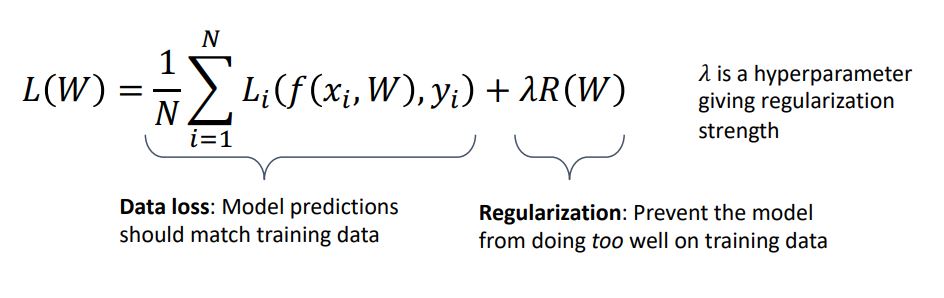
여러 종류의 regularization은 람다라는 하이퍼 파라미터를 갖는데 model이 얼마나 training data에 적합해야 하는지와 얼마나 이 모델이 regularization loss를 잘 따라야하는지에 대한 trade-off를 이 람다를 통해 잘 조정해야 한다.
* 이렇게 model이 training data 에서 지나치게 잘 작동하지만 보지못한 data에 대해선 좋지못한 성능을 보일때 이것을 overfitting되었다고 한다.
이러한 regularization는 아래와 같은 종류들이 있다.

* 추후에 이런 regularization을 좀더 잘 이해할 수 있는 regression 문제를 정리하면서 함께 설명하고자 합니다.
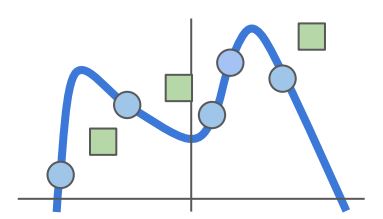
위의 그림에서 파란 점이 training data, 초록 박스가 test data 혹은 unseen data라고 했을때 다항식으로 표현된 파랑색 그래프가 training data 에 과하게 적합되었고 보지 못한 data에 나쁜 성능을 보일때 이것을 overfitting 되었다고 하고, 이런 현상을 방지하고자 loss function에 regularization 을 추가하여 model에 penalty를 주게된다.
2. Cross-Entropy Loss
이전의 SVM loss 에서는 score 자체에 대한 해석은 하지 않고 correct class가 other class보다 score가 높은지 낮은지에만 관심이있었다.
SVM loss와는 다르게 cross-entropy loss 에서는 확률론적인 해석을 통해 score 자체에 추가적인 의미를 부여한다.
아래의 수식을 이용하여 class별 확률분포를 계산하는데 이때 softmax라는 함수가 사용된다.
이떄 cross-entropy loss 를 구하는 방법은 다음과 같다.

1. 주어진 각 class별 score에 exponential을 취하여 양수값을 갖게한다.
2. 각 지수들을 softmax function을 통하여 nomalize시켜 확률분포를 구해준다.
* 여기서 normalize된 값들은 확률이기 때문에 모든 값들의 합은 1이 된다
3. 이 probablility distribution 의 correct class 값에 -log를 취하여 loss를 구해준다.
* 이때 loss function은 log-likelihood function이라고 한다. 자세한 내용이 궁금하다면 아래 링크를 살펴보아도 좋다.
cross-entropy loss
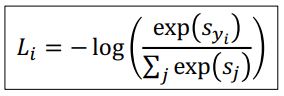
Q1. cross-entropy loss가 가질 수 있는 최대/최소값은?
: loss의 min 값은 0이 될 것이고 max값은 무한대가 된다. -log를 취하기 전 확률 분포를 생각해 보았을때 우리는 correct class의 확률은 1이되길 원하고 다른 클래스의 확률은 0이되길 원한다. 그렇기에 correct class를 완벽하게 분류했다면 -log(1) 이되어 loss는 0이 될 것이다.
Q2. 모든 score가 0에 매우 근접한 random value로 initialize 되었을때 loss값은?
: score가 0에 근접하다면 exp를 취했을때 1이 되므로 loss는 -log(1/C) 즉, log(C) 가 된다 (여기서 C는 클래스의 개수를 뜻한다)
Reference

CS231n과 내용이 비슷하군요 이 강의가 더 이해가 잘 되나요? 강의 설명이 잘 되어있어서 이해가 잘 되었어요~