BERT , GPT에 대해서
- 지난시간 복습
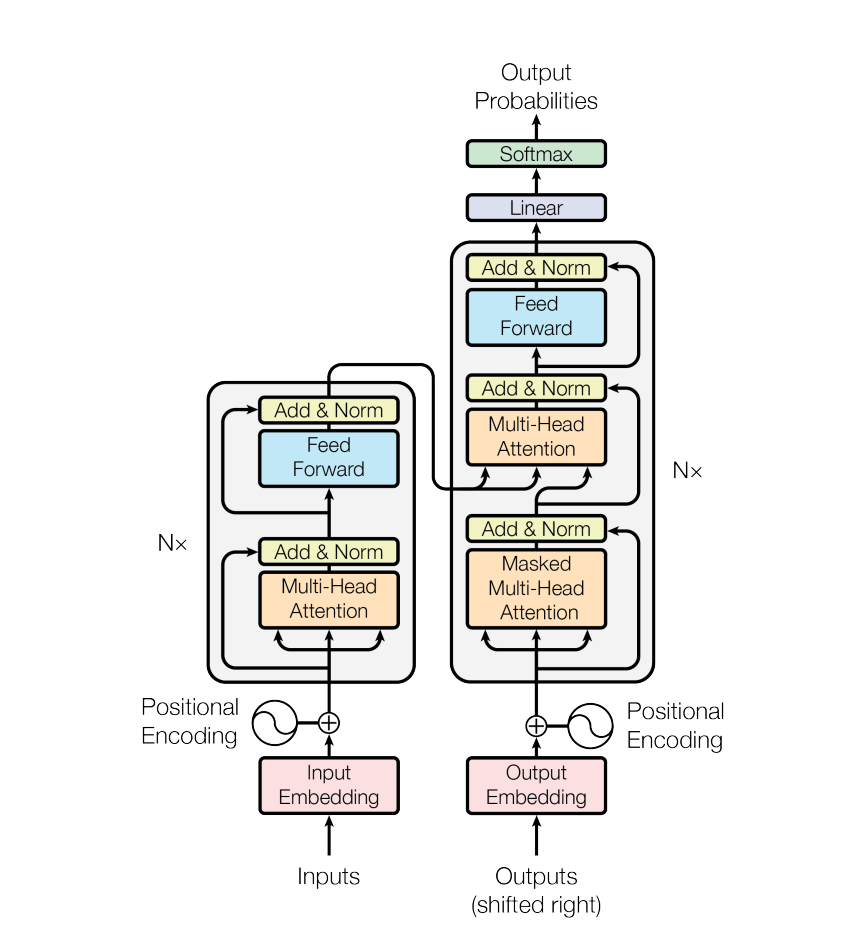
-
Encoding
- 입력(Token + Positional Encoding) → N개의 블록 만큼 반복
- 각 블록:
Multi-Head Attention→Add & Norm→Feed Forward→Add & Norm
-
Decoder
- 출력(Token + Positional Encoding, 오른쪽으로 시프트된 형태) → N개의 블록 반복
- 각 블록:
Masked Multi-Head Attention(자기 자신만 보도록 제한, 단어를 예측방지)Multi-Head AttentionFeed Forward→Softmax로 예측
BERT(Bidirectional Encoder Representaions form Transformers)
- 2018년도 구글이 공개한 사전 훈련된 모델
- Encoder 기반 Transformers
- 위키피디아(25억 단어)와 BookCorpus(8억 단어) 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델
- 양뱡향(Bidirectional) : 문맥을 왼쪽 - 오른쪽 모두에서 이해
- 문장의 의미를 잘 이해하고자 할 때 사용 (이해 중심)
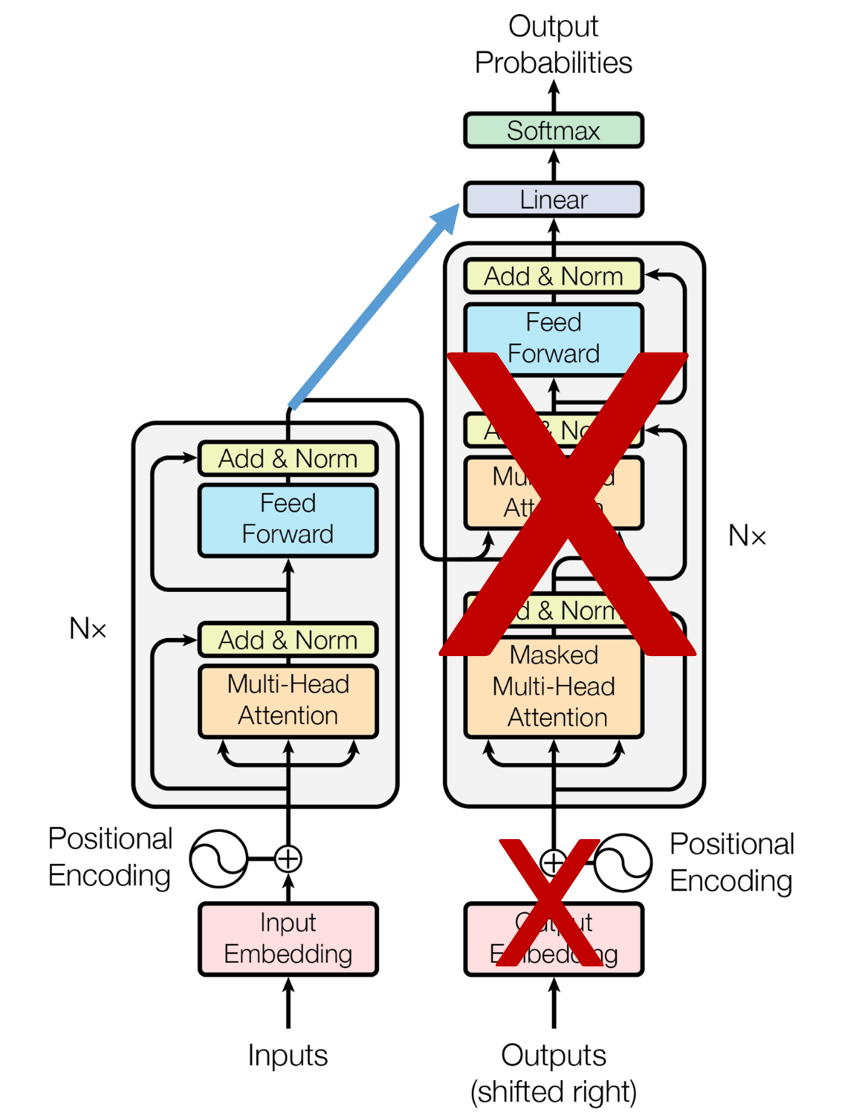
BERT 구조
BERT 문맥을 반영한 임베딩(Contextual Embedding)
d_model 768, CLS : 초기 입력을 가르키는 벡터
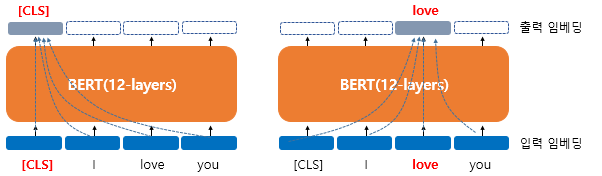
Masked Language Model (MLM)
BERT는 사전 훈련을 위해서 인공신경망의 입력으로 들어가는 입력 텍스트의
15%의 단어를 랜덤으로 마스킹Masking처리 해당 MASK된 단어를 예측
ex) ‘나는 [MASK]에 가서 그곳에서 빵과 [MASK]를 샀다’ 예측 : 슈퍼, 우유
랜덤으로 선택된 15%의 단어들은 Rule-Base를 통해 적용
- 80%의 단어들은 [MASK]로 변경한다.
ex) The man went to thestore→ The man went to the[Mask] - 10%의 단어들은 랜덤으로 단어가 변경한다.
ex) The man went to thestore→ The man went to thedog - 10%의 단어들은 동일하게 둔다.
ex) The man went to the store → The man went to the store
My dog is cute. he likes playing MLM 적용 —> ['my', 'dog', 'is' 'cute', 'he', 'likes', 'play', '##ing']
- 'dog' 토큰은 [MASK]로 변경
- 'he'는 랜덤 단어 'king'으로 변경
- 'play'는 변경되진 않았지만 예측에 사용
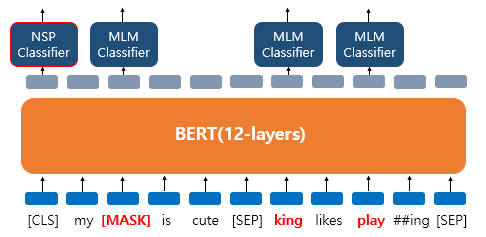
NSP(Next Sentence Prediction)
BERT의 사전학습 중 하나로, 두문장이 연속된 문장인지 예측하는 방법
- 문장 간 관계 이해 능력을 학습
- 질의응답(QA), 문장 유사도, 자연어 추론(NLI)등 문맥 이해가 중요한
downstream task에 강점을 가짐
학습 방법
두개의 문장을 준 후에 이 문장이 이어지는 문장인지 아닌지 맞추는 방식으로 훈련
50 : 50 비율로 실제 이어지는 두 개의 문장과 랜덤으로 이어붙인 두개의 문장을 주고 훈련 시킴
SEP 라는 특별 토큰을 사용해서 문장을 구분 : 문장 시작과 끝에 삽입
- 이어지는 문장의 경우 Sentence A : The man went to the store. Sentence B : He bought a gallon of milk.
Label = IsNextSentence
- 이어지는 문장이 아닌 경우 경우 Sentence A : The man went to the store. Sentence B : dogs are so cute.
Label = NotNextSentence
GPT(Generative Pre-trained Transformer)
- 2022년 OpenAI에서
ChatGPT란 인공지능 모델을 공개 - 미래 단어를 못 보게 마스킹 (auto-regressive)
- Decoder 기반 Transformer
- 단방향(Left - to - Right) : 왼쪽에서 오른쪽으로만 문맥을 이해
- 이전 토큰만 보고 다음 단어 예측
- 챗봇, 텍스트 생성, 코드 생성, 요약 등에서 활용 됨
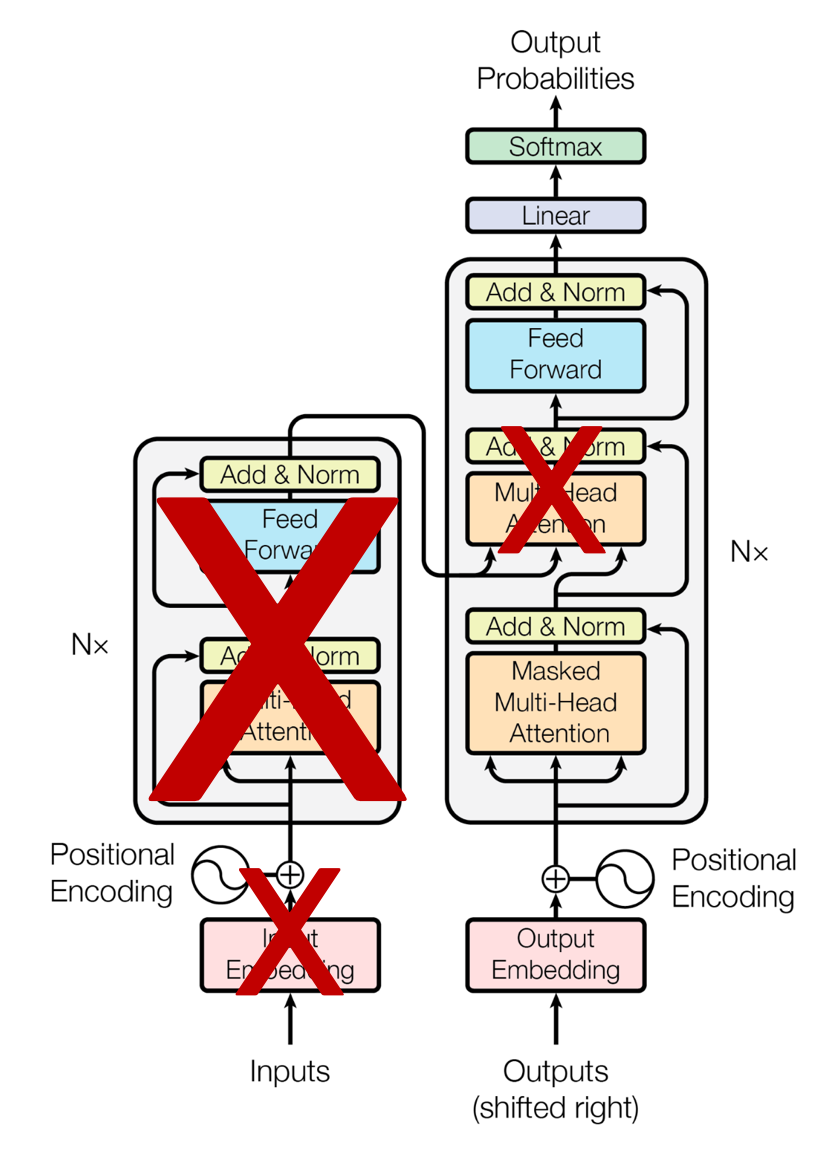
GPT 구조
실습
1. BERT
https://huggingface.co/google-bert/bert-base-uncased
from transformers import pipeline
from pprint import pprint
unmasker = pipeline('fill-mask', model='bert-base-uncased')
result = unmasker(" The man went to the [MASK]")
pprint(result)
# OutPut
[{'score': 0.9374873638153076,
'sequence': 'the man went to the.',
'token': 1012,
'token_str': '.'},
{'score': 0.04775523021817207,
'sequence': 'the man went to the ;',
'token': 1025,
'token_str': ';'},
{'score': 0.0038847781252115965,
'sequence': 'the man went to the?',
'token': 1029,
'token_str': '?'},
{'score': 0.002510115737095475,
'sequence': 'the man went to the!',
'token': 999,
'token_str': '!'},
{'score': 0.0006421132129617035,
'sequence': 'the man went to the...',
'token': 2133,
'token_str': '...'}]결과가 좋지 않은 이유
- BERT 사전학습 corpus 문제
- BERT는 확률이 높은 단어부터 예측
- 토크나이저에 의해 나뉘는 서브워드로 쪼개질 수 있음 store —> sto + ##re
일반 텍스트로 학습되어 있는 RoBERTa가 좋음
from transformers import pipeline
from pprint import pprint
unmasker = pipeline('fill-mask', model='roberta-base')
result = unmasker("The man went to the <mask>.")
pprint(result)
# OutPut
[{'score': 0.1833825707435608,
'sequence': 'The man went to the hospital.',
'token': 1098,
'token_str': ' hospital'},
{'score': 0.10685282945632935,
'sequence': 'The man went to the police.',
'token': 249,
'token_str': ' police'},
{'score': 0.042112916707992554,
'sequence': 'The man went to the house.',
'token': 790,
'token_str': ' house'},
{'score': 0.03826417401432991,
'sequence': 'The man went to the car.',
'token': 512,
'token_str': ' car'},
{'score': 0.03082439862191677,
'sequence': 'The man went to the store.',
'token': 1400,
'token_str': ' store'}]BERT를 감성 분석(Sentiment Analysis) 파인튜닝
from datasets import load_dataset
from transformers import BertTokenizer
from transformers import DataCollatorWithPadding # 데이터 포맷 설정
from transformers import BertForSequenceClassification
from transformers import Trainer, TrainingArguments
from sklearn.metrics import accuracy_score
# IMDB 감성분석 데이터 로딩
dataset = load_dataset('imdb')
train_data = dataset['train'].shuffle(seed=42).select(range(2000))
test_data = dataset['test'].shuffle(seed=42).select(range(1000))
# 전처리 및 토크나이징
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased") # Bert
def tokenize(example):
return tokenizer(example['text'], padding='max_length',
truncation=True, max_length=256)
train_tokenized = train_data.map(tokenize, batched=True)
test_tokenized = test_data.map(tokenize, batched=True)
train_tokenized.set_format("torch", columns=["input_ids", "attention_mask", "label"])
test_tokenized.set_format("torch", columns=["input_ids", "attention_mask", "label"])
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
# 모델 정의
model= BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# 훈련설정
training_args = TrainingArguments(
output_dir="./results",
eval_strategy='epoch',
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size= 8,
num_train_epochs=3,
weight_decay= 0.03,
logging_dir ='./logs'
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_tokenized,
eval_dataset=test_tokenized,
tokenizer=tokenizer,
data_collator=data_collator,
) # Bert 훈련 셋팅
trainer.train()
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = logits.argmax(axis=-1)
acc = accuracy_score(labels, predictions)
return {"accuracy": acc}
trainer.compute_metrics = compute_metrics
results = trainer.evaluate()
print(results)
# output
trainer = Trainer(
{'eval_loss': 0.28193923830986023, 'eval_runtime': 3.1325, 'eval_samples_per_second': 319.23, 'eval_steps_per_second': 39.904, 'epoch': 1.0}
{'loss': 0.3157, 'grad_norm': 38.011207580566406, 'learning_rate': 6.693333333333334e-06, 'epoch': 2.0}
{'eval_loss': 0.5200415849685669, 'eval_runtime': 3.1338, 'eval_samples_per_second': 319.098, 'eval_steps_per_second': 39.887, 'epoch': 2.0}
{'eval_loss': 0.5156381130218506, 'eval_runtime': 3.0169, 'eval_samples_per_second': 331.462, 'eval_steps_per_second': 41.433, 'epoch': 3.0}
{'train_runtime': 84.0017, 'train_samples_per_second': 71.427, 'train_steps_per_second': 8.928, 'train_loss': 0.2445567677815755, 'epoch': 3.0}
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 750/750 [01:24<00:00, 8.93it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 125/125 [00:03<00:00, 41.35it/s]
{'eval_loss': 0.5156381130218506, 'eval_accuracy': 0.887, 'eval_runtime': 3.0512, 'eval_samples_per_second': 327.742, 'eval_steps_per_second': 40.968, 'epoch': 3.0}Accelerate란?
Accelerate는 Hugging Face가 만든 분산 학습, GPU 활용 최적화 도구
쉽게 말하면, "Trainer 없이도 PyTorch 모델을 빠르고 쉽게 GPU/TPU에서 학습할 수 있도록 도와주는 도구"
특징
- GPU 자동 감지 (CPU, 1-GPU, 다중 GPU, TPU 모두 지원)
model.to(device)같은 복잡한 코드 없이 학습 가능- Trainer 없이도 깔끔한 PyTorch 코드로 빠른 학습 가능
예시
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_loader = accelerator.prepare(model, optimizer, train_loader)
for batch in train_loader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
PEFT (Parameter-Efficient Fine-Tuning)란?
PEFT는 BERT나 LLM 같은 큰 모델을 효율적으로 학습하기 위한 방법
모든 파라미터를 업데이트하지 않고, 일부 핵심 부분만 훈련해서 훨씬 빠르게 fine-tuning하는 기법
예시
from peft import get_peft_model, LoraConfig
peft_config = LoraConfig(
r=8, target_modules=["query", "value"], lora_alpha=16
)
model = get_peft_model(base_model, peft_config)참고 문서
- 🤗 Hugging Face PEFT 공식 문서: https://huggingface.co/docs/peft
- 🤗 Accelerate 문서: https://huggingface.co/docs/accelerate
