1. Intro
- 단어가 간 관계 파악의 필요성
- RNN의 한계
- Self-Attetntion의 등장 배경과 의미
자연어 문장은 단어들 사이의 복잡한 관계로 구성되어있다. 예를 들어 “The animal didn’t cross the street because it was too tired.” 에서
it이 가리키는 대상은 “animal” 이다 이러한 장기 의존성(long-term-dependency)을 파악하기 위해 RNN과 LSTM 모델을 사용되었으나, 순차적 구조로 인해병렬처리가 어렵고 장기 의존성 처리에 한계를 가졌다.

2. Background
- RNN / LSTM 구조 개요 및 한계(기울기 문제, 병렬화 어려움)
기존의 RNN 계열 모델(RNN, LSTM, GRU)은 입력 시퀀스를 순차적으로 처리하면서 과거 정보를 기억하는 방식으로 작동
입력이 길어질수록 초기 입력 정보가 후반부에 전달되지 않는 현상이 발생(기울기 소실) 즉,장기 의존성발생
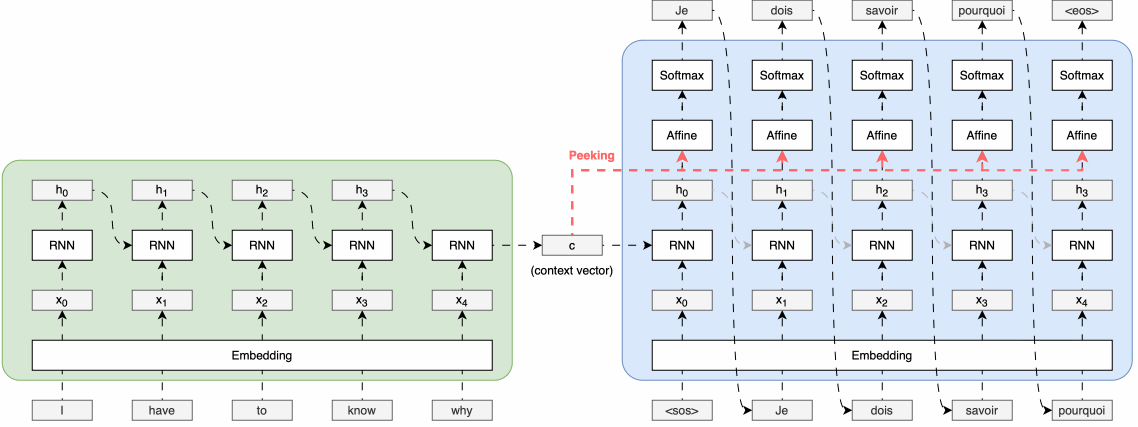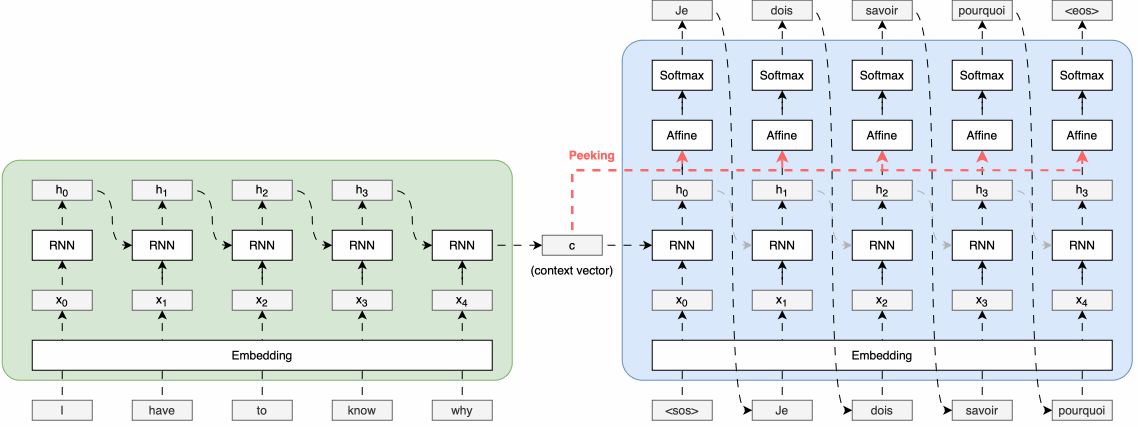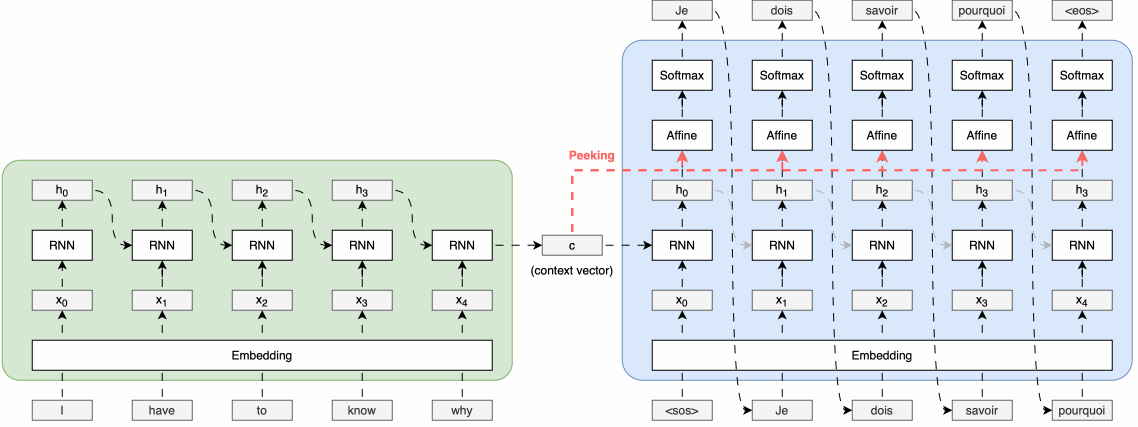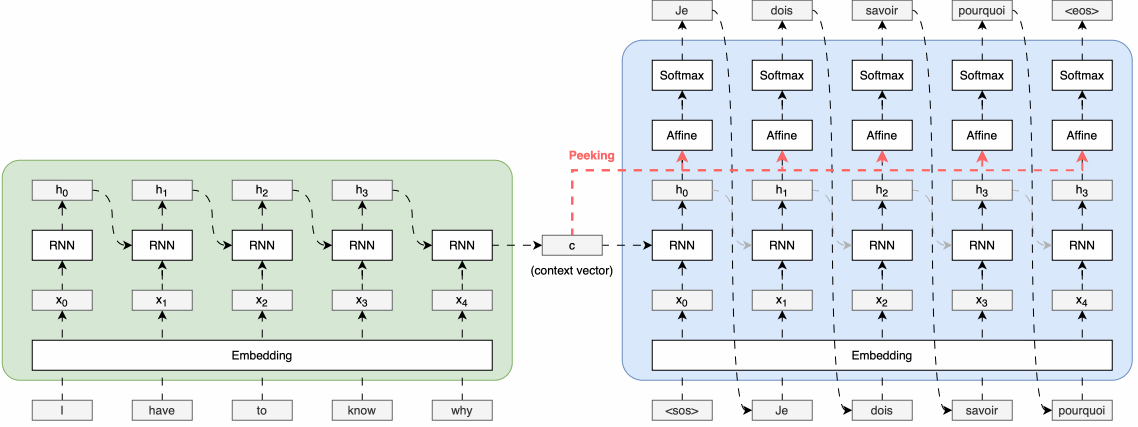
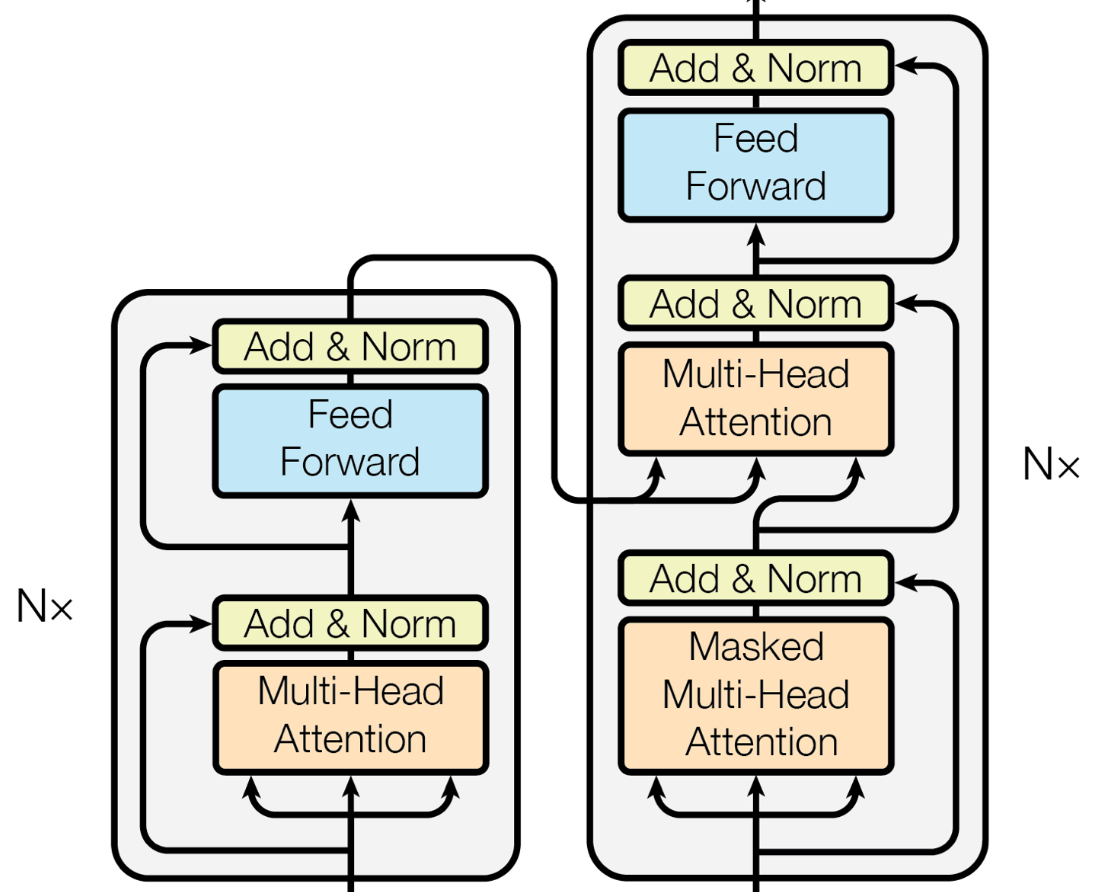
Transformer
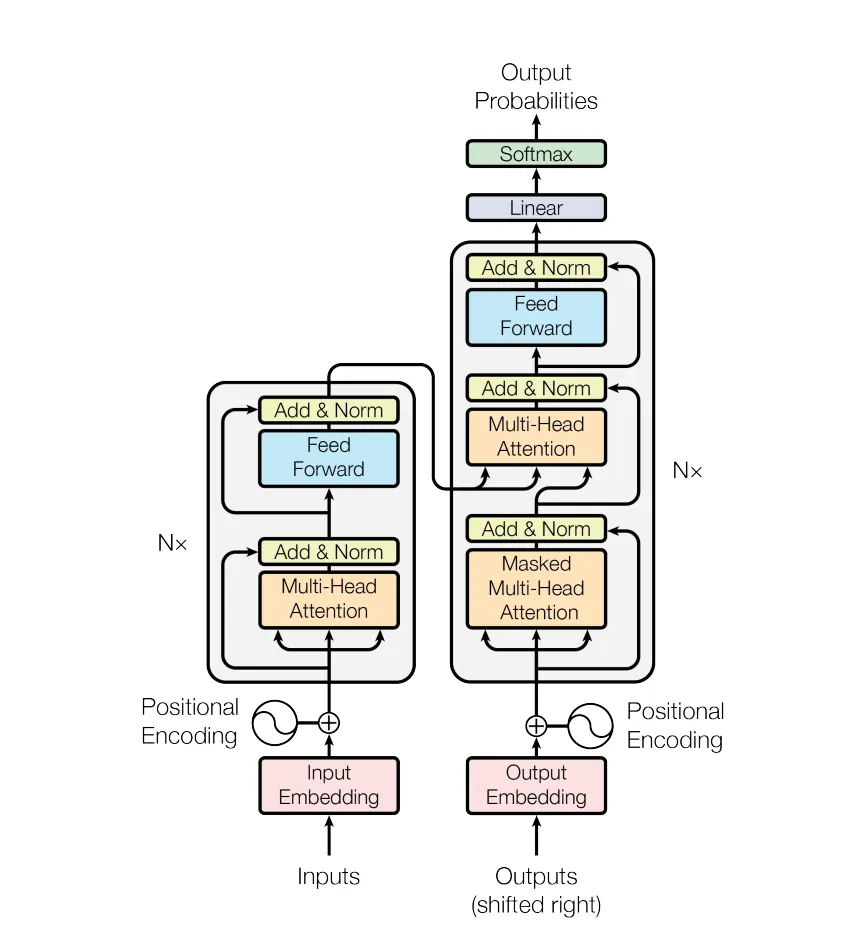
The Transformer - model architecture.- Attetnion의 매커니즘 기본 원리 (논문에서 embedding dim= 512)
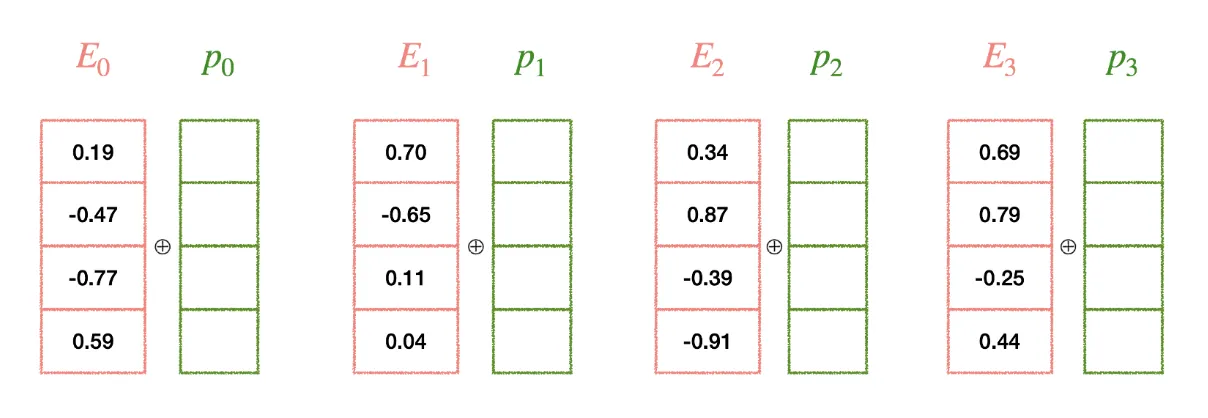
Positional Encoding
Transformer는 RNN과 달리 순차적인 처리 구조가 없기 때문에, 단어의 순서를 모델에 알려주기 위해 포지션 인코딩을 사용
수식
포지션 인코딩은 사인(sin)과 코사인(cos) 함수를 이용하여 각 위치에 대한 고유한 벡터를 생성합니다.
여기서:
- 는 단어의 위치를 나타냅니다.
- 는 임베딩 차원의 인덱스입니다.
- 은 임베딩의 차원 수입니다.
이러한 포지션 인코딩은 단어 임베딩에 더해져 입력으로 사용되며, 모델이 단어의 순서를 인식할 수 있도록 도와줍니다.
① Although I did not get 95 in last TOEFL, I could get in the Ph.D program.
② Although I did get 95 in last ToEFL, I could not get in the Ph.D program.
- Self-Attention
Self-Attention에서 Query(Q), Key(K), Value(V)는 각각
단어가 무엇을 알고 싶어하는지(Q),자신이 어떤정보를 갖고 있는지(K) 그리고그정보를 실제로 제공할 내용(V) 즉 Q와 K의 유사도를 통해 얼마나 중요한지를 판단하고, 이를 가중치를 바탕으로 V를 종합하여 각 단어의 문맥을 동적으로 재구성
Self-Attention Architecture
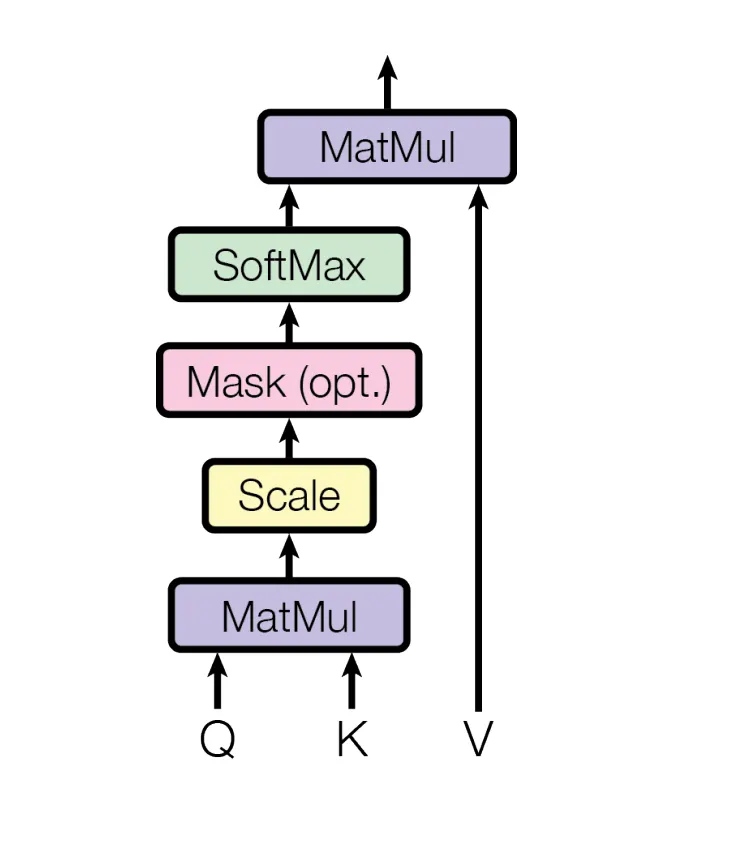
Self-Attention Scaled Dot-Product Attention 이라고 불림
-
입력: 시퀀스 벡터 X
-
Q, K, V로 선형 변환
-
: 단어 간 유사도 점수 계산
-
: 점수 안정화를 위한 스케일링
-
softmax: 가중치로 변환
-
softmax 결과 × V: 최종 attention output 생성
-
MultiHeadAttention
MultiHead Attention에서는 각 단어가 다른 단어를 얼마나 참고하는지
가중치 행렬로 표현 예시로 “love”가 “you” 에 높은 가중치를 준다면 “love”가 “you”와의 관계를 중요하게 여긴다는것을 의미 가중치는 다양한 head에서 서로 다른 관점으로 계산하며, 문장의 복잡한 의 구조를 모델링하는데 기여
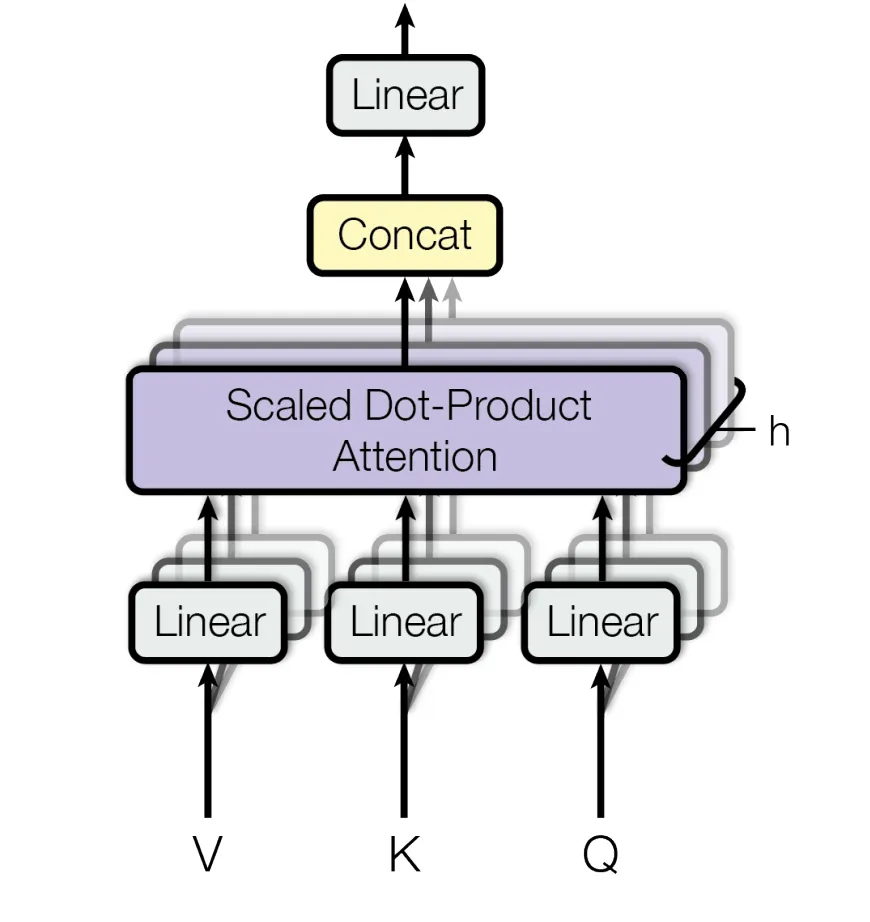
Multi-Head AttentionMultiHead는 Self-Attention을 여러개 생성하여 Concat으로 만들 수 있다.
여러개의 Self-Attention을 병렬로 실행해서 다양한 관점에서 정보를 얻는다.
| Head | 집중하는 내용 예시 |
|---|---|
| Head 1 | 문법 구조 (“I” → “love”) |
| Head 2 | 의미 연결 (“love” → “you”) |
| Head 3 | 대명사 참조 (“you” → “I”) |
| Head 4 | 위치/순서 (“all” → “you”) |
- Masked Attention
“미래를 보지 못하게 막는” 어탠션
Transformer 디코더는 문장을 왼쪽부터 오른쪽으로 생성
예: “ I love ___ “ —> 다음 단어 예측
Self-Attention은 모든 단어를 동시에 참고하므로, 아직 생성되지 않은 미래 단어도 미리 참고해버릴 수 있다.
3. Practice
“I love all you” —> [”I”, “love”, “all”, “you”]
“I” 단어를 기준으로 Q : 어떤 단어와 중요한지 알고 싶음 ”I”, “love”, “all”, “you” 는 각각의 K, V를 가진다
만약에 “I” 가 “love”와 유사하면 V에 높은 가중치
- attetntion (논문 식과 코드 기준으로)
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, embedding_dim, attention_dim):
super(SelfAttention, self).__init__()
self.q = nn.Linear(embedding_dim, attention_dim) # embeding, embeding
self.k = nn.Linear(embedding_dim, attention_dim)
self.v = nn.Linear(embedding_dim, attention_dim)
def forward(self, x):
q = self.q(x)
k = self.k(x)
v = self.v(x)
attention_scores = torch.matmul(q, k.transpose(-2, -1))
attention_scores = attention_scores / (k.size(-1) ** 0.5) # scaling
attention_weights = F.softmax(attention_scores, dim=-1)
return torch.matmul(attention_weights, v), attention_weights
# 입력 문장
tokens = ["I", "love", "you", "all"]
vocab = {token: idx for idx, token in enumerate(tokens)}
# 임베딩 차원과 어텐션 차원 설정
embedding_dim = 20
vocab_size = len(vocab)
embedding_layer = nn.Embedding(vocab_size, embedding_dim)
input_indices = torch.tensor([[vocab[token] for token in tokens]]) # shape (1,4)
embedded_input = embedding_layer(input_indices)
# Self-Attetnin 적용
attention_dim = 5
model = SelfAttention(embedding_dim, attention_dim)
output, attention_weights = model(embedded_input)
# 결과 출력
print("입력 임베딩 shape:", embedded_input.shape)
print("어텐션 출력 shape:", output.shape)
print("어텐션 가중치 shape:", attention_weights.shape)
# Attention weights 출력 (해당 단어가 어떤 단어에 집중하는지 확인)
print("\n 어텐션 가중치:", attention_weights)
for i, token in enumerate(tokens):
print(f"{token}의 어텐션 가중치: {attention_weights[0, i].detach().numpy()}")
# Out Put
어텐션 출력 shape: torch.Size([1, 4, 5])
어텐션 가중치 shape: torch.Size([1, 4, 4])
어텐션 가중치: tensor([[[0.1484, 0.3170, 0.2334, 0.3012],
[0.1705, 0.2226, 0.2197, 0.3872],
[0.2564, 0.2368, 0.2226, 0.2841],
[0.2576, 0.2333, 0.2866, 0.2225]]], grad_fn=<SoftmaxBackward0>)
I의 어텐션 가중치: [0.14839762 0.3170038 0.2334257 0.30117288]
love의 어텐션 가중치: [0.17047001 0.22259612 0.21974151 0.38719246]
you의 어텐션 가중치: [0.25643694 0.23684639 0.22258951 0.28412715]
all의 어텐션 가중치: [0.25756836 0.23327933 0.28660533 0.22254698]- MultiHead Attention (논문 식과 코드 기준으로)
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super().__init__()
assert embed_dim % num_heads == 0, "embed_dim must be divisible by num_heads"
self.num_heads = num_heads
self.attention_dim = embed_dim // num_heads
self.attentions = nn.ModuleList([
SelfAttention(embed_dim, self.attention_dim) for _ in range(num_heads)
])
self.fc = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
# 각 head에서 Self-Attention 실행
head_outputs = [attention(x)[0] for attention in self.attentions] # [0] = value output
concatenated_heads = torch.cat(head_outputs, dim=-1) # shape: (batch, seq_len, embed_dim)
output = self.fc(concatenated_heads)
return output
# Output
tensor([[[-0.2003, -0.1201, 0.3481, 0.5369, -0.2922, -0.1561, -0.1494,
0.4596, -0.5094, 0.0197, 0.3359, -0.2807, 0.1158, 0.1626,
-0.1988, 0.1339, -0.2524, -0.3809, -0.0888, 0.1803],
[-0.1896, -0.1498, 0.3792, 0.5216, -0.2832, -0.1687, -0.1483,
0.4906, -0.5168, 0.0142, 0.3519, -0.3113, 0.1066, 0.1975,
-0.1607, 0.1380, -0.2534, -0.3944, -0.1130, 0.1653],
[-0.2223, -0.2454, 0.3515, 0.6065, -0.2738, -0.1776, -0.3031,
0.3989, -0.6282, -0.0211, 0.3914, -0.3266, 0.1656, 0.2542,
-0.2040, 0.1105, -0.3431, -0.4163, -0.0710, 0.1652],
[-0.1552, -0.1206, 0.4888, 0.5004, -0.1537, -0.2338, -0.1291,
0.6104, -0.4732, -0.0474, 0.2155, -0.1733, 0.0678, 0.1401,
-0.0938, 0.1488, -0.1917, -0.3793, -0.2657, 0.2403]]],
grad_fn=<ViewBackward0>)
torch.Size([1, 4, 20])참고자료
Attention Is All You Need.pdf
blog
https://velog.io/@jhbale11/어텐션-매커니즘Attention-Mechanism이란-무엇인가
https://exupery-1.tistory.com/210
youtube
https://www.youtube.com/watch?v=8E6-emm_QVg&ab_channel=혁펜하임|AI%26딥러닝강의
https://www.youtube.com/watch?v=DdpOpLNKRJs&ab_channel=코드없는프로그래밍
https://www.youtube.com/watch?v=aaxaKxUzLk8&ab_channel=코드없는프로그래밍
Code
https://colab.research.google.com/drive/1N8wsIjkKqjgBxxuavrNervAvcfJu8iCm?usp=sharing
