Diary
오늘은 텐서를 직접 다뤄보는 작업이랑, 논문을 직접 보면서 이해하는 작업을 좀 했다. 그동안은 책 속의 내용이나 블로그 중심으로 봤다면, 이제 좀 더 논문을 보고 실제 구현해보는 연습들을 조금씩 해보려고 한다. 이번 논문은 사실 코드랄게 없어서, 내용 이해와 개념 정리 정도만 했는데 다음부터는 좀 더 정리해보려고 한다.
Learn
- Big Transfer BiT) General Visual Representation Learning 정리
- Deep Learning for Coders with fastai & PyTorch 100페이지
- 어도비 AI 관련 티타임즈 영상
Detail
- Torch Tensor
-
파이썬 사용시 이 빠른 속도의 이점을 누리려면 반복문 사용보다는 array나 tensor에 직접적으로 작동하는 명령어를 사용해야한다.
- 파이토치나 넘파이는 모두 파이썬으로 짜여진게 아니라 저차원의 코드로 해서 속도를 높인 라이브러리라서 파이썬보다 매우 빠르다.
- 그 중 파이토치는 GPU에 텐서를 적재할 수 있어 병렬 계산을 할 수 있고, 자동 미분해준다는게 큰 장점 -
torch.stack은 torch.stack([a,b])하면, (2,3,4) shape을 만들어준다.(a,b모두 3,4 텐서라고 했을 때)
-
concat은 인자로 Dim을 지정해줄 수 있어서 6,4나 3,8로 만들어줄 수 있음
seven_tensors = [tensor(Image.open(o)) for o in sevens] stacked_sevens = torch.stack(seven_tensors).float()/255 stacked_sevens.shape *torch.Size([6131,28,28])
-
-
torch.mean
import torch arr = torch.FloatTensor([[[1, 2,3], [3, 4,1]], [[5, 6, 7], [7, 8, 9]]]) print(arr.mean(dim = 0).shape) print(arr.mean(dim = 0))결과값 torch.Size([2, 3]) tensor([[3., 4., 5.], [5., 6., 5.]])주어진 dim에 대해서 mean을 한다는 건, 해당 차원을 제거한다와 같다고 보면 될듯
print(arr.mean(dim = 1).shape) print(arr.mean(dim = 1))결과값 torch.Size([2, 3]) tensor([[2., 3., 2.], [6., 7., 8.]])print(torch.mean(arr, dim = (0,1)).shape) print(torch.mean(arr, dim = (0,1)))결과값 torch.Size([3]) tensor([4., 5., 5.])
- Big Trnafer(BiT) : General Visual Representation Learning
- 이전까지의 연구 트렌드는 특정 테스크의 문제를 해결하기 위해 모델을 어떻게 복잡하게 설계하고 더 큰 데이터를 쏟아부었을 때 어떤 성능을 보여주는지에 대해서 연구했었다.
- 위와 같은 방식은 결국 per-task one specific model이기 때문에 많은 학습 비용과 fit된 데이터셋이 필요했다.
- 하지만 충분히 generic한 데이터셋과 큰 모델을 학습시키고 나서 해당 모델의 가중치들을 활용해, 특정 테스크에 적합한 데이터를 일부 학습시킨다면 특정 테스크만을 학습시킨 모델보다 성능이 좋다는 것을 논문을 통해 밝혔다.
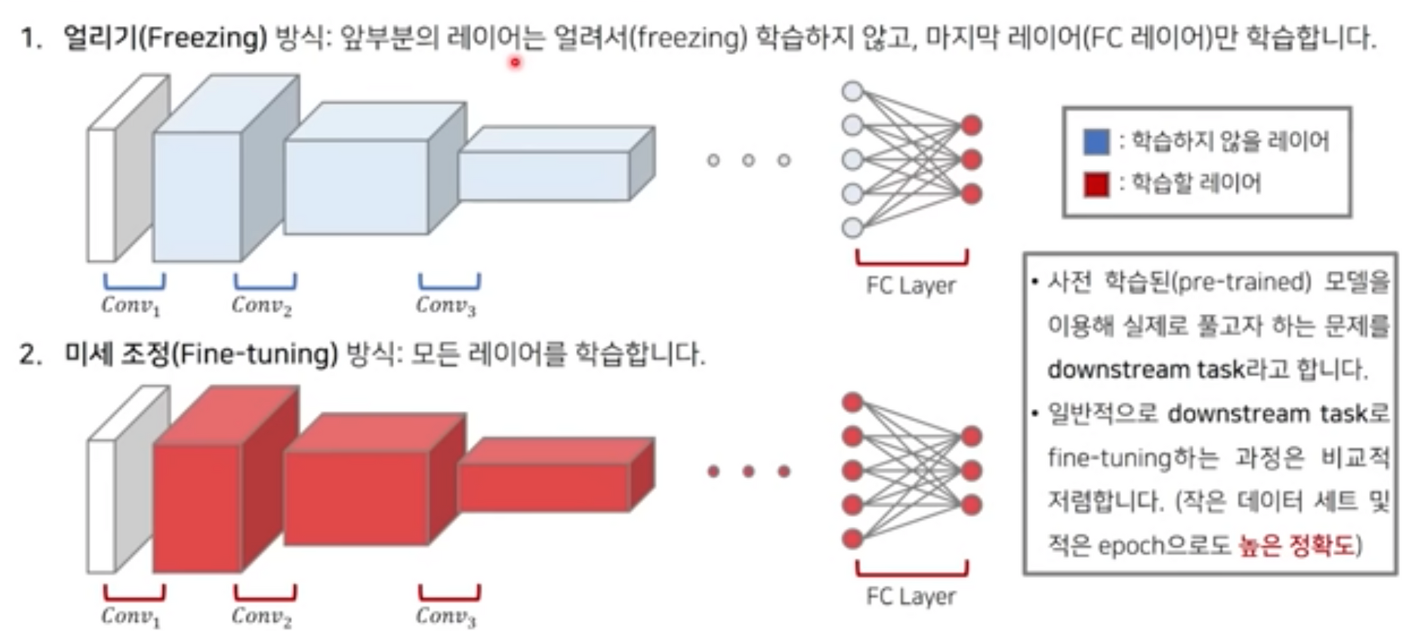
출처 : 나동빈님 유튜브 (링크)
- 결국 Deep Learning의 비용은 “데이터 확보”와 학습 비용에 달려있는데 결국 다양한 테스크를 수행할 수 있는 하나의 모델이 scalable하다고 볼 수 있을 것 같다.(LLM 모델도 결국 비슷한 접근)
Link

Lean, Learn, Lesson