Diary
이제 공부하면서 조금씩 반복되는 개념들이 보이곤 하는데 그래도 아직은 뭔가 깊이가 부족한 느낌이 든다. 너무 다양한걸 공부하고 있나 싶기도 해서, 좀 하루에 공부하는 갯수를 좀 줄여봐도 좋을것 같다.하나만 진득하게 하는걸로.
Learn
- JinCoding 실무형 NLP Course 6강: NLG (Natural Language Generation) & LLM (Large Language Model)
- Machine Learning Yearning Book 21~30 정리
- Deep Learning for coders with fastai & Pytorch 50페이지
Detail
- 프롬프트 엔지니어링 & GPT
-
NLG(Natural Language Generation)은 결국 어떤 테스크인지에 따라서 기준이 매우 다르다. 또한 대화라는 것은 목적을 충족함과 동시에 자연스러운 것까지도 중요하기 때문에 정확한 Metric을 정의하는 것도 매우 어렵다.
-
chatGPT는 트랜스포머를 쌓아올린 것으로만 이해해서, 인코더와 디코더 모두 있는 것으로 이해했지만 실제로는 디코더로 이루어진 모델이라고 한다. 이해하기로는 다음 단어 예측을 하는거니까, encoder는 필요가 없음.(번역 모델에서만 앞의 맥락이 필요한건데, decoder는 사실 input만 질문으로 주면 되니까 굳이 인코더까지 만들 필요는 없음. 그래서 프롬프트 자체에 대한 제한을 걸어두는 이유도 정보 손실 때문이지 않을까 하는 생각이 들었다.)
-
NLG의 발전 방향
(smaller size model) Transfer learning → (Larger size model) Few shot Learning- task-specific dataset → 현업에서 데이터 모아서 파인튜닝하기까지 시간 & 노동이 많이 듬
- Fine-tuning은 pre-trained model의 general language understanding을 최대치로 활용하지 못함 → parameter 가중치 변경 X, 오로지 input에 컨텍스트를 제공 (In-Context Learning)
-
주요 파라미터
a. 단어 선택 방식
1) Greedy Decoding : 다음 단어로 가장 확률이 높은 단어를 무조건 선택하는 알고리즘
2) Random Sampling : 확률적으로 다음 단어를 선택해서, 다음 문장의 다양성을 주는 알고리즘b. Temperature : 토큰들의 확률 분포들을 조정하는 방식으로, 낮을수록 Greedy하게 만들고, 높일수록 Random하게 만들어준다.
1) low temperature : reproducible(재현가능)하기 때문에 실용적인 서비스에서는 이를 조정해주는게 좋다. 너무 낮추다보면, 문장이 생성안되고 이상한 단어들만 나열될 수 있다.
2) high temperature : reproducible하지 않기 때문에 좀 더 창의적인 업무와 연관되어 있다.c. top_p : sum(token_prob) <= top_p
문장 다음에 들어갈 단어로 모든 단어를 후보로 선정할 수 없기 때문에, 모델이 뱉어내는 단어별 확률에서 높은 애들 순부터 더했을때 top_p보다 낮을때까지의 단어들만 후보군으로 추출하는 작업
- 프롬프트 엔지니어링
다양한 전제나 예외처리를 해주는 프롬프트도 있는데, 결국 개발하는 것처럼 실제 서빙하려면 다양하게 처리를 해주는 작업은 필요해보인다.
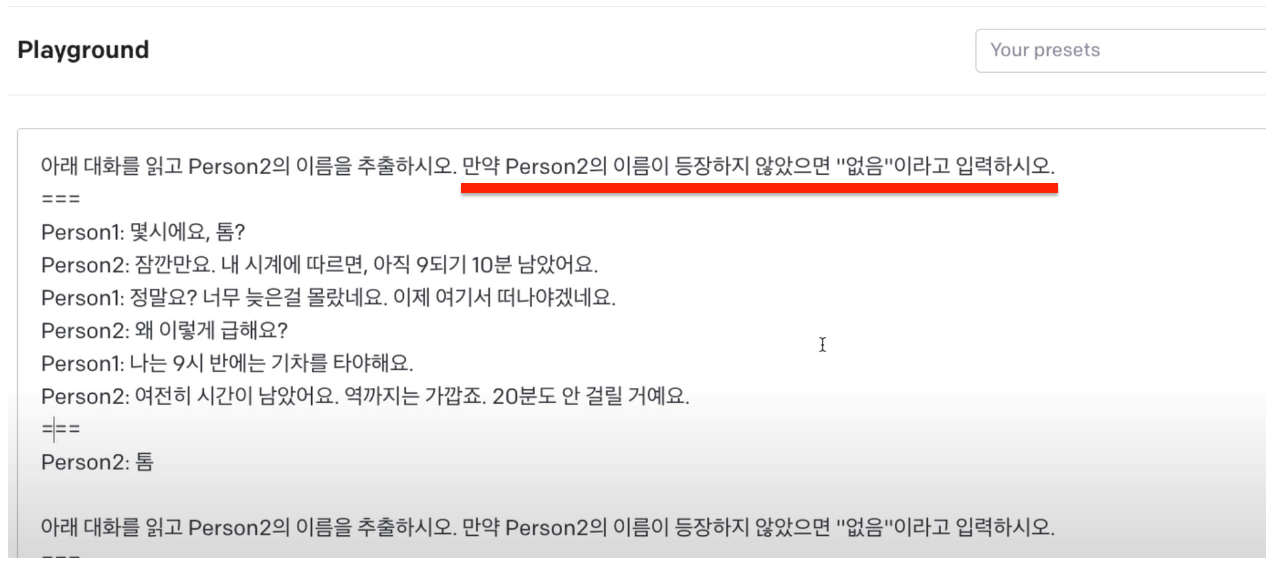
- machine learning yarning book 21~30강
- 모델을 개선하기 위해서 수동적으로 오류 케이스들을 뜯어보는걸 error analysis라고 하는데 이 때 랜덤으로 뽑아서 보기 보다는 eyeball dataset(직접 뜯어볼 애)과 blackbox dataset(절대 에러케이스를 뽑지 않고 놔둘 데이터셋)을 나누고 eyeball dataset의 케이스를 보면서 모델을 개선하는 것을 권장한다. 이렇게 두가지 데이터셋의 성능을 평가해봄으로써, Outfitting되지 않았는지 살펴볼 수 있다. 물론 데이터셋이 충분하지 않다면(약 100개 이상의 에러가 있는 Eyeball dev dataset이 이상적이다.) 전체 개발 데이터셋을 eyeball dev dataset으로 보는 것이 좋다.
- 머신러닝 모델을 만드는데 있어서 완전한 모델을 만들어낼 수는 없다. 특히 딥러닝에서는 결국 데이터와 결과값을 주고 최적화를 시키는 것이기 때문에 그 내부를 디테일하게 tuning하거나 설계하는 것은 불가능하다. 빠르게 모델을 이터레이션하는 방법을 지향한다.
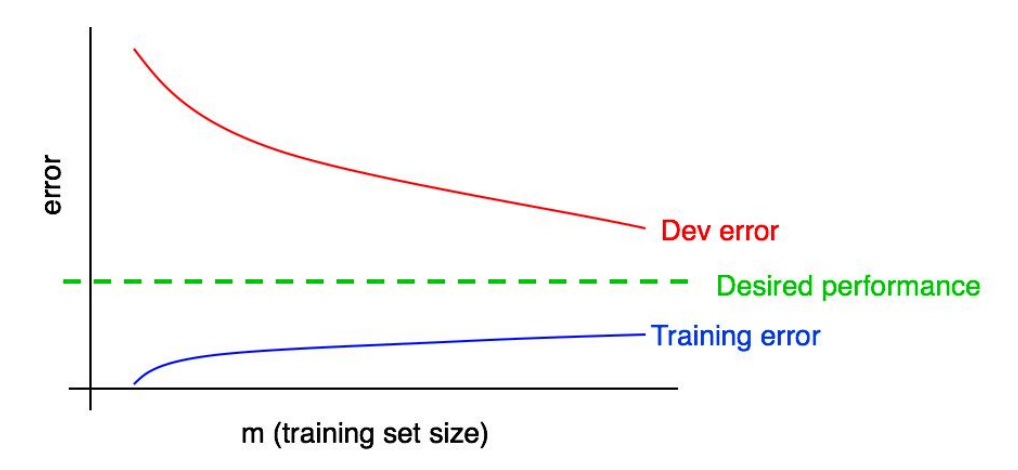
- Learning Curve란, 트레이닝 데이터셋의 크기에 따른 Error를 측정한 커브로 dev error와 Training error가 수렴하는 지점을 보면서 이 모델이 우리가 목표로 하는 성능(Desired performance)에 도달 가능한지를 가늠할 수 있는 지표다.
Link
- 업스테이지 프롬프트 엔지니어링 블로그글
- 찐코딩 유튜브 NLP 6강
