.png)
음수간선이 있을땐 벨만-포드
위에서 소개한 다익스트라 알고리즘의 한계는, 음수간선이 있을 때, 사용이 불가능 하다는 것이었고, 특히 음수 가중치를 가진 사이클이 나왔을 때, 정상적인 작동을 보장하지 못한다는 것입니다.
벨만-포드 알고리즘의 경우에는 다익스트라 알고리즘과 다른 접근법을 택하여 그래프에서 시작점에서 임의의 정점까지의 최단거리를 계산하기 때문에 음수 간선이 있더라도 올바르게 사용할 수 있습니다. 그리고, 최단거리 알고리즘의 정상적인 작동을 방해하던 음수 사이클을 탐지하여, 의마가 없는 값을 반환하는 것이 아닌, 음수 사이클이 있음을 알려주는 출력을 내게 할 수 도 있습니다.
기본 아이디어
다익스트라 알고리즘의 기본 아이디어가, BFS를 참고했다면, 벨만-포드 알고리즘의 기본 착안 아이디어는 최단거리와 간선의 가중치에 대한 명백한 부등식에서 출발합니다.
는 시작점에서 최단거리를 저장하는 배열이고, 는 (u,v) 간선의 가중치를 의미합니다.
이 부등식이 성립하는 것은 상당히 직관적으로 다가옵니다. 시작점에서 v 까지 가는 경로가, 시작점에서 u를 거쳐서, (u,v) 간선을 타고 오는 경우에는 dist[v]가 dist[u] 에다가 w(u,v)를 더한 값이 되겠지요. 만약에 시작점에서 v까지 가는 최단경로가 u를 경유해서 오는것보다 짧으면, dist[v]가 더 짧을 수 도 있겠지요.
벨만-포드 알고리즘은 위 부등식이 반드시 성립함에 착안해서, 최단거리를 찾아냅니다. 벨만-포드 알고리즘의 간단한 구성은 아래와 같습니다.
- 시작점에서 한 정점까지의 최단 거리의 상한치를 저장하는 배열을 만듭니다. 아래 설명에서는
upper[]라는 이름으로 이 배열을 쓰겠습니다. 초기화는 충분히 큰 값INF로 합니다. - 그래프의 모든 간선에 대해서 와 를 비교합니다. 만약, 라면, 위에서 소개한 부등식에 의해서, 로 설정 할 수 있습니다. 이 작업을 완화(Relaxiation)이라고 합니다.
- 위에서 말했던 완화 작업을 정점의 개수 - 1 만큼 실행합니다.
upper[]에는 시작점에서 각 정점까지의 최단거리가 저장되어 있습니다.
당위성의 증명
위에서 말했던 부등식이 성립하는 것은 자명하고, 이를 여러번 반복하면 최단경로에 가까워 질 것 같다는 생각은 들지만, 과연 이 완화라는 작업이 끝이 날지, 끝이 난다면, 과연 실제 정확한 값이 upper[]에 저장되어 있을 지는 확실하지가 않군요. 이제 알고리즘의 당위성을 알아봅시다.
시작점을 s라고 하고, 그래프상의 임의의 정점을 u라고 합시다. u는 임의의정점 이라고 하였으니, 어떤 정점이어도 좋습니다. s=u여도 상관 없습니다. 정말로 임의의 정점이니까요.
s에서 u로 가는 최단경로가 아래와 같다고 합시다.
처음에는 upper[s]만이 실제의 최단 경로를 저장한것이 확실합니다. 모든 간선을 다 돌면서 완화 작업을 하면 upper[a1]에 실제의 최단 경로가 저장 되겠지요, 그 다음 완화 작업을 할 때에는 upper[a2]에, 그 다음은 upper[a3]에... 결국 upper[u] 까지 실제의 최단 경로가 저장된다고 할수 있을 것입니다. u가 임의의 정점이라고 하였으니, 그래프 상의 모든 정점에 대해서 이를 적용한다면, 몇번의 완화 작업 후에는 upper[]에 최단 거리가 올바르게 저장될 것이라고 예측할 수 있지요.
그렇다면 완화 작업을 몇번 해야 하는걸까요? 최단 경로가 올바르게 정의되는 그래프. 즉 음수 사이클이 없는 그래프(음수 사이클이 있다면, 그 사이클만 계속 돌면 최단거리가 계속 줄어들어서, 최단거리가 올바르게 나올 수 없겠지요?)에서는 한 정점을 두번 방문하는 경우가 없으므로, 가장 많은 정점을 방문하는 경우는, 모든 정점을 한번씩 방문하는 경우가 되겠습니다. 그리고, 시작점은 알고리즘이 시작하기 전부터 최단거리가 올바르게 계산되어(0) 있으므로, 완화 작업은 정점의 개수 - 1 만큼만 수행하면 됩니다.
음수 사이클 탐지
위에서 알고리즘의 개요에 대해서 논할 때, 벨만-포드 알고리즘은 음수 사이클을 탐지할 수 있다고 하였습니다. 이를 손쉽게 구현하는 방법의 힌트는, 알고리즘의 당위성 증명 파트에 있습니다.
최단 경로가 올바르게 정의되는 그래프에서는, 최단경로에서 한 정점을 두번 방문하는 경우가 없으므로... 완화 작업은 정점의 개수 - 1 만큼만 수행하면 됩니다.
이 점에 착안해보는 것입니다. 음수 사이클이 존재하면, 완화 작업이 정점의 개수 - 1 보다 더 많이 수행될거 같다는 예상을 할 수 있지요.
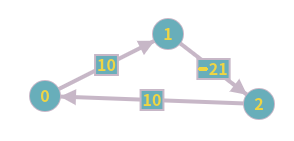
음수 사이클이 있는 그래프
위의 그래프는 음수 사이클이 있는 그래프의 한 예입니다. 알고리즘의 기본 아이디어에서 소개한 부등식을 이 그래프에 적용 시키면 다음과 같이 되지요.
이 세 부등식의 좌변과 우변을 각각 더해봅시다. 위 부등식이 동시에 성립할 수 있다면, 좌변과 우변을 합한 부등식 또한 성립하는 부등식이겠지요. 그런데 왠걸, 그렇게 연산을 하니 아래와 같은 식이 나옵니다.
이를 정리하면, 이고, 이는 결코 성립할 수 없는 부등식임을 알 수있지요. 완화 작업은 위의 부등식이 성립하지 않을 때 일어나고, 음수 사이클에 대해서 위의 부등식은 언제나 실패하므로, 완화 작업을 필요한 만큼보다 한번 더 해도, 완화는 성공하겠군요. 알고리즘 내에서 완화 작업의 성공 여부를 기록하고, 한번 더 완화를 실시하고, 그 완화가 성공했으면 그래프 내에 음수 사이클이 있음을 알 수 있겠습니다.
구현
int V;//정점의 개수
vector<pair<int,int> > adj[MAX_V];
vector<int> bellmanFord(int src) {
vector<int> upper(V,INF);
upper[src] = 0;
bool updated;
for(int iter = 0; iter < V;++i){
updated = false;
for(int here = 0; here < V; ++here)
for(int i = 0; i < here.size(); ++i){
int there = adj[here][i].first;
int cost = adj[here][i].second;
//(here,there) 간선을 이용해서 완화를 시도한다
if(upper[there] > upper[here] + cost) {
upper[there] = upper[here] + cost;
updated = true;
}
}
//완화가 실패했을 경우 더 할 필요가 없다
if(!updated) break;
}
//V-1번 완화만으로 충분한데, V번까지 완화가 성공했다면 음수사이클이 존재
if(updated) upper.clear();
return upper;
}주의사항
벨만-포드 알고리즘을 이용해서, 시작점에서 임의의 정점까지의 경로가 존재하는지 판별할때, 주의사항이 있습니다. upper[u] == INF를 이용해서 탐색하면 안된다는 것인데요, 다익스트라 알고리즘과는 다르게, 벨만-포드 알고리즘이 허용하는 그래프에는 음수 간선 또한 허용하므로, 음수 간선이 존재하는 그래프에서는 완화를 거치면서 upper[]가 줄어들 수 있습니다. 그러므로, 임의의 정점으로 가는 경로가 있는지 확인하기 위해서는 적당히 큰 값 M 에 대해서 upper[u] < INF - M인지 확인해 봐야 합니다.
실제 경로 찾기
벨만-포드 알고리즘에서의 실제 경로 찾기는 BFS나 다익스트라 알고리즘에서 하듯이 할 수 있습니다. 완화를 성공시켜주는 간선의 출발점을 부모로 잡는 것입니다. 그리고 그 부모 정보를 통해서 그래프에서의 실제 경로를 역추적 할 수 있지요. 직접 코드로 봅시다.
int V;//정점의 개수
vector<pair<int,int> > adj[MAX_V];
vector<int> parent(adj.size(),-1);
vector<int> bellmanFord(int src) {
vector<int> upper(V,INF);
upper[src] = 0;
bool updated;
for(int iter = 0; iter < V;++i){
updated = false;
for(int here = 0; here < V; ++here)
for(int i = 0; i < here.size(); ++i){
int there = adj[here][i].first;
int cost = adj[here][i].second;
//(here,there) 간선을 이용해서 완화를 시도한다
if(upper[there] > upper[here] + cost) {
upper[there] = upper[here] + cost;
parent[there] = here;//부모를 저장한다
updated = true;
}
}
//완화가 실패했을 경우 더 할 필요가 없다
if(!updated) break;
}
//V-1번 완화만으로 충분한데, V번까지 완화가 성공했다면 음수사이클이 존재
if(updated) upper.clear();
return upper;
}
vector<int> shortestPath(int v){//위의 정보를 바탕으로 경로를 계산해 내는법
vector<int> path(1,v);
while(parent[v] != v){
v = parent[v];
path.push_back(v);
}
reverse(path.begin(),path.end());
return path;
}시간 복잡도
벨만-포드 알고리즘의 수행시간은 모든 간선을 검사하는 중첩 반복문에 의해 좌우됩니다. 가장 밖에 있는 반복문은 번 수행되고, 안의 두 반복문은 모든 간선을 순회하므로 라고 볼 수 있지요. 따라서 벨만-포드 알고리즘의 전체 시간 복잡도는 라고 할 수 있겠습니다.
참고한 글
프로그래밍 대회에서 배우는 알고리즘 문제 해결 전략(구종만 저)
위키백과 플로이드-워셜 알고리즘 항목
