.png)
개요
이번 포스팅에서는 일상생활에서도 많은 응용으로 쓰이는, 그래프의 최단 경로 탐색에 대해서 다루어 보려고 합니다. 그래프를 이용해서 알고리즘 문제를 해결 할 때, 최소의 비용을 사용해서 결과까지 도달하는 문제들을 많이 볼 수 있습니다. 직접적으로 그래프 문제가 아니더라도, 문제의 상황을 상태공간으로 하는 그래프를 그릴 때, 문제에서 요구하는 것이 해당 그래프의 임의의, 또는 특정한 최단경로인 상황도 상당히 많죠.
그래프의 최단 경로 탐색 알고리즘은 여러가지가 있지만, 우선은 상대적으로 많이 쓰이고, 난이도가 그렇게 어렵지 않은 알고리즘인 다익스트라, 벨만-포드, 플로이드, BFS를 이용한 알고리즘을 설명해 보고자 합니다.
사족으로, 이제 소개할 알고리즘들은 플로이드 알고리즘을 제외하면, 인접 리스트 방식으로 그래프를 표현했을 때, 코드가 좀 더 깔끔해 집니다. 그래서, 밑에서 소개할 알고리즘 에서의 그래프 표현 방식은, 인접 리스트 방식으로 표현할 것입니다.
그래프에 가중치가 없을땐 BFS
BFS는 너비 우선 탐색(Breadth First Search)의 약자로, DFS 처럼 그래프에서 쓰일 수 있는 탐색 알고리즘 입니다.
DFS에 대해서는 포스팅을 세개나 써가면서 어떤 응용이 있는지를 여러가지 소개 했지만, BFS는 가중치가 없는 그래프의 최단경로를 찾는 경우의 응용 말고는, 잘 쓰이는 응용이 없는듯 합니다. 아래의 코드는 BFS를 이용한 가중치가 없는 그래프에서의 start 정점에서의 나머지 정점으로의 최단거리를 알아내는 알고리즘의 구현입니다.
vector<vector<int> > adj;//그래프의 인접 리스트 표현
vector<int> distance(adj.size, -1); //각 정점의 최단 거리
vector<int> bfs(int start){
queue<int> q;
vector<int> order;//정점의 방문 순서
distance[start] = 0;
q.push(start);
while(!q.empty()){
int here = q.front();
q.pop();
order.push_back(here);
for(int i = 0 ;i < adj[here].size(); ++i){
int there = adj[here][i];
if(distance[there] == -1){
q.push(there);
distance[there] = distance[here] + 1;
}
}
}
return order;
}당위성의 증명
이 알고리즘을 통해서 실제로, 가중치가 없는 그래프에서, 올바른 최단거리가 실제로 구해지는지 알아봅시다. 아래의 내용은 위의 알고리즘에서 최단거리를 계산하는 방식입니다.
너비 우선 탐색 과정에서 간선 를 통해서, 정점 를 처음 발견해 큐에 넣었다고 합시다. 이때, 시작점에서 까지의 최단 거리
distance[v]는, 시작점에서 까지의 최단 거리distance[u]에다가 1을 더한것 입니다.
위와 같은 내용이 성립함을 간단히 증명할 수 있습니다.
distance[v]가distance[u] + 1보다 클 수 없음은 분명합니다. 시작점부터u까지의 경로에서 (u,v) 간선 하나를 더 붙이면distance[u] + 1길이의 경로가 나오기 때문입니다.
distance[v]가distance[u] + 1보다 작을 수 없음은 귀류법으로 증명 할 수 있습니다.
시작점에서v까지의 최단경로가distance[u] + 1보다 짧다고 가정합시다. 이 경로 상에서v바로 이전의 정점은 거리가distance[u]보다 작아야만 합니다.(큐에는 시작점에 가까운 순서부터 들어가므로) 그럴려면v는u보다 이전에 방문되었어야 하고, (u,v)를 통해서v를 방문했다는 가정과 모순이 됩니다.
실제 경로 찾기
BFS를 이용해 실제 최단 경로가 어떻게 구성되어 있는지 알아보려면, 위에있는 코드를 살짝만 변형하면 됩니다. 정점 u를 방문했을 때, 다른 정점v 를 넣었을 땐, 간선 (u,v)를 이용한다고 위에서 언급한 바 있지요. 이는 곧, BFS 스패닝 트리에서 v의 부모는 u라는 의미와 동치입니다. 이런 식으로 BFS 스패닝 트리에서의 부모를 알 수 있으므로, 스패닝 트리에서의 부모를 별도의 배열로 기억합시다. 그리고, 그 배열을 바탕으로, 실제의 경로를 계산해내면 됩니다.
vector<vector<int> > adj;//그래프의 인접 리스트 표현
vector<int> distance(adj.size(), -1); //각 정점의 최단 거리
vector<int> parent(adj.size(),-1);
vector<int> bfs(int start){
queue<int> q;
vector<int> order;//정점의 방문 순서
distance[start] = 0;
q.push(start);
while(!q.empty()){
int here = q.front();
q.pop();
order.push_back(here);
for(int i = 0 ;i < adj[here].size(); ++i){
int there = adj[here][i];
if(distance[there] == -1){
q.push(there);
distance[there] = distance[here] + 1;
parent[there] = here; //부모에 대한 정보를 추가
}
}
}
return order;
}
vector<int> shortestPath(int v){//위의 정보를 바탕으로 경로를 계산해 내는법
vector<int> path(1,v);
while(parent[v] != v){
v = parent[v];
path.push_back(v);
}
reverse(path.begin(),path.end());
return path;
}시간 복잡도
BFS의 시간 복잡도는 DFS와 크게 다르지 않습니다. 모든 정점을 검사하고, 그 정점들을 검사하면서 인접한 간선들을 검사하기 때문에, 인접 리스트 형태로 그래프가 이루어져 있을 경우에는 , 인접 행렬 형태로 이루어져 있을때는 가 됩니다.
가중치가 다르고, 음수간선이 없을땐 다익스트라
그래프의 각 간선의 가중치가 서로 차이가 없는 그래프의 경우에는 BFS를 이용해서 시작점으로부터 각 정점의 최단거리를 알 수 있었습니다. 하지만, 각 간선의 가중치가 다 같지만은 않다면 어떨까요?
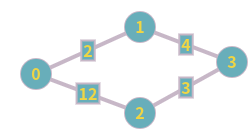
BFS로는 최단경로를 찾을 수 없는 그래프
위 그림에서 나타내는 그래프가 위에서 말한 상황을 표현합니다. 그리고 이 그래프는 BFS 로는 0번 정점에서 2번 정점으로 가는 최단경로를 찾을 수 없습니다. 0번 정점에서 2번 정점으로 가는 최단 경로는 우리 눈으로 쉽게 볼 수 있듯, 0→1→3→2 이지만, BFS가 방문하는 순서는, 0→(1,2 번 정점 방문)→3 이기 때문에, BFS로는 해결할 수 없는것이 확실합니다.
현실에서도 모든 도로의 이용시간, 이용요금이 다 같지는 않으니, 위의 BFS만 가지고는 많은 현실속 문제를 해결하긴 힘듭니다. 이번 장에서는, 그런 상황속에서 쓸 수 있는 다익스트라 알고리즘에 대해서 알아보겠습니다.
하지만, 이 다익스트라 알고리즘을 사용하는데 유의해야할 사항이 있습니다. BFS가 가중치가 다른 그래프에서 올바른 결과를 보증 못하듯, 그래프의 간선의 가중치에 음수가 있을 경우, 특히 음수 사이클이 있을 경우 다익스트라 알고리즘이 올바르게 동작하지 않습니다. 이러한 경우에는 밑에서 소개할 벨만-포드 알고리즘을 사용해야 합니다.
기본 아이디어
위에서 BFS로 해결할 수 없는 그래프를 잠깐 언급했었습니다. 위 그래프에서 BFS는 방문한 순서대로 정점들을 방문 하기 때문에, 거리가 더 짧은 간선이 발견되어도 큐에서 "새치기"를 할 수 없습니다. 하지만, 위 상황속에서 우리는 간선이 좀 더 늦게 발견되어도, 길이(가중치)가 짧다면 발견된 순서를 좀 무시하고 "새치기"할 필요가 있음을 알 수 있습니다.
그렇다면 "새치기"를 할 수 있는 큐를 도입해서, BFS를 한다면 이와 같은 문제도 풀어낼 수 있지 않을까요? 이러한 아이디어에서 시작하는 알고리즘이, 우선순위 큐를 사용하는 다익스트라 알고리즘 입니다.
다익스트라 알고리즘의 기본 구성은 아래와 같습니다.
- 각 정점까지의 최단 거리를 배열하는
dist[]를 만듭니다. 맨 처음에는 시작점을 제외한 최단경로를 알지 못하므로, 시작점은 0, 나머지는 그래프에서의 거리로 나오지 않을 충분히 큰 값으로 초기화 합니다. - BFS에서는 큐에 정점의 번호를 넣었지만, 다익스트라 알고리즘에서는 정점의 번호와, 해당 정점까지의 최단거리를 한 쌍으로 넣습니다. 물론 큐는 우선순위 큐 입니다.
- BFS 처럼 반복문을 돌면서, 큐에서 원소 하나를 꺼내서, 간선으로 연결된 다른 정점들을 검사합니다.
dist[]를 참고해서, 이때까지 알고 있던 해당 정점까지의 최단경로보다,현재 검사중인 정점까지의 최단거리 + 간선의 가중치가 더 작다면,dist[]를 갱신합니다. 그리고, BFS 처럼 해당 정점의 이름과 거리를 큐에다가 넣습니다. 기존까지 알고있던 값보다 더 짧은 경로를 찾지 못했다면, 굳이 큐에 넣을 필요는 없죠.
기본 구성은 간단합니다만, BFS에서는 생기지 않는 상황이 다익스트라 알고리즘에서 생김을 알 수 있습니다. 위에서 언급한 그래프에서도 생기는데, 마우스 스크롤을 다시 올리기는 귀찮으니, 그림을 다시 한번 첨부하겠습니다.
큐에 정보를 넣을 때, (정점의 번호, 해당 정점까지의 최단 거리) 형태로 정보를 넣는다고 합시다.
시작점을 방문하고 나서는 (1,2), (2,12)가 우선순위 큐 내에 들어갑니다. 계속해서 탐색을 하다보면 (2,9) 또한 들어갑니다. dist[]는 올바르게 갱신되지만, 이미 큐 속에 들어가있는 (2,12)를 어떻게 하는게 좋을까요? (2,9)를 추가할 떄, (2,12)를 찾아서 (2,9)로 바꾸는 방법도 있겠지만, 그러한 연산은 C++ STL에서 지원해주지 않고, 구현하는것도 상당히 까다롭습니다. 간단한 방법은 (2,9)를 꺼내서 연산을 수행하고, (2,12)가 꺼내 졌을때 이를 무시하는 것입니다. 큐에서 꺼낸 정보가 무시해도 되는 정보인지 판단하는 것은 매우 간단합니다. 큐에서 방금 나온 정보보다 더 짧은 경로가 이전에 발견되었다면(즉 무시해야 하는 정보라면) dist[]가 갱신되어서, dist[]에 있는 최단 거리 정보보다 더 큰 최단거리의 정보를 담고 있겠지요.
구현
이러한 아이디어를 실제로 코드로 옮겨봅시다. 구현을 직접 보면 알겠지만, BFS의 구현과 크게 다르지 않습니다. 다른 점은 위에서 말했듯, 일반 큐 대신 우선순위 큐를 쓴다는 것과, 한 정점에 대해 여러개의 정보가 큐 안에 들어갔을때 이를 처리하는 코드가 추가된것 뿐입니다.
아래 코드에서 INF는 위에서 말했던 충분히 큰 수 입니다.
int V;//정점의 개수
vector<pair<int,int> > adj[MAX_V];//그래프 인접 리스트. (연결된 정점 번호, 간선 가중치) 형태로 저장
vector<int> dijkstra(int src){
vector<int> dist(V, INF);
dist[src] = 0;
priority_queue<pair<int, int> > pq;
pq.push(make_pair(0,src));
while(!pq.empty()){
int cost = -pq.top().first;
int here = pq.top().second;
pq.pop();
//지금 꺼낸 정점이 무시해야 하는 정보인지 확인한다
if(dist[here] < cost) continue;
for(int i = 0; i < adj[here].size();++i){
int there = adj[here][i].first;
int nextDist = cost + adj[here][i].second;
if(dist[there] > nextDist){
dist[there] = nextDist;
pq.push(make_pair(-nextDist, there));
}
}
}
return dist;
}위의 코드에서 특이한 부분이라면, 우선순위 큐 pq에 거리 정보를 넣을 때, 부호를 뒤집어서 넣는 점입니다. C++ STL에서 제공하는 우선순위 큐 priority_queue는 숫자가 큰게 우선순위를 높게 매겨서 큐 앞쪽에 배치되게 하지만, 우리는 반대의 순서를 원하기 때문이죠. 만약에 부호를 뒤집어서 넣지 않고 위의 코드와 같은 일을 하는 코드를 작성하기 위해서는, 우선순위 큐 pq의 정의가 다음과 같이 되어야 합니다.
priority_queue<pair<int,int>, vector<pair<int,int> >,greater<pair<int,int> > > pq;당위성의 증명
다익스트라 알고리즘은 우리가 알고 있던 BFS의 일종의 변형이기에 최단거리를 정확히 계산할거라는 예감은 들지만, 확실하게 이 알고리즘이 최단거리를 찾아준다는 증명은 되지 못합니다.
알고리즘의 정당성에 대한 증명을 귀류법을 이용해서 해봅시다. 즉, 알고리즘이 올바르게 작동하지 않을 수 있다고 가정을 해보자는 것입니다.
최단거리를 올바르게 계산하지 못하는 점이 있다고 해봅시다. 그런 점이 여러개가 있다면 그 중 알고리즘이 제일 먼저 방문하는 점을 u라고 합시다. u는 알고리즘이 올바르게 최단거리를 발견하지 못한다고 가정하였으니, 알고리즘이 찾는 경로보다 더 짧은 최단경로가 존재한다는 뜻입니다.
우선 u는 시작점이 될 수 없습니다. 시작점의 최단경로는 0으로, 알고리즘이 시작할 때, 정확하게 알고 있기 떄문이죠. 알고리즘이 u를 방문할때의 상황을 생각해 봅시다. u를 방문하기 전에, 적어도 시작점은 알고리즘이 방문했습니다. 알고리즘이 u를 방문하기 전에 방문했던 정점들의 집합을 A 집합 이라고 하고, 아직 방문하지 않은 정점들의 집합을 B 집합이라고 합시다.
시작점에서 u까지의 최단 경로는 어떻게 구성되어 있을까요? 최단경로를 구성하는 정점들에 대해서 확실히 알 수 있는것은, A 집합에 속해있는 정점들로만 구성 될 수 없다는 것입니다. 그렇게 되면, 알고리즘이 정확하게 최단경로를 짚은게 되고, 앞의 가정이 틀리게 되니까요. 따라서 B 집합에 속한 정점들을 반드시 포함해야 합니다. 시작점은 반드시 경로에 포함되니 A 집합에 속한 정점 또한 포함됨을 알 수 있지요.
그 "최단 경로"에 포함된 마지막 A 집합에 포함된 정점은 라고 하고, 처음으로 나타나는 B 집합에 포함된 정점을 라고 합시다.
는 큐 안에 있을 것입니다. 왜냐하면, 정점을 방문하면서 정점은 정점에 인접한 정점이기 때문이죠.(경로 상에서 인접해 있잖아요)
정점은 u보다는 빨리 큐에서 나오지 못한것 같습니다. 만약에 u 보다 빨리 큐에서 나왔다면, 는 A 집합에 있을거니까요.
이 이야기를 왜 하냐고요? u가 보다 빨리 큐에서 나왔다는 것은 우선순위 큐의 특성상dist[u] < dist[β]를 의미합니다. 를 통해서 u로 가는것이 알고리즘이 찾아준 시작점에서 u까지 가는 경로보다 더 짧을수는 없을것 같군요. 음수 길이 간선이 없다면 말이죠(이래서 음수 길이 간선이 없을때 라는 전제조건이 붙었습니다)
실제 경로 찾기
다익스트라 알고리즘은 BFS 알고리즘의 변형이기 때문에 실제 경로를 찾는것도 BFS를 활용할 떄의 실제 경로를 찾는것과 유사하게 찾을 수 있습니다. dist[]가 갱신될 때, 그 정점을 갱신시켜준 정점을 부모로 저장하고, 그 부모에 대한 정보를 통해서 실제 경로를 복원해올 수 있습니다.
아래는 위의 설명을 실제 코드로 옮긴 것입니다. BFS의 그것과 유사하다는 점을 참고해보세요
int V;//정점의 개수
vector<pair<int,int> > adj[MAX_V];//그래프 인접 리스트. (연결된 정점 번호, 간선 가중치) 형태로 저장
vector<int> parent(adj.size(),-1);
vector<int> dijkstra(int src){
vector<int> dist(V, INF);
dist[src] = 0;
priority_queue<pair<int, int> > pq;
pq.push(make_pair(0,src));
while(!pq.empty()){
int cost = -pq.top().first;
int here = pq.top().second;
pq.pop();
//지금 꺼낸 정점이 무시해야 하는 정보인지 확인한다
if(dist[here] < cost) continue;
for(int i = 0; i < adj[here].size();++i){
int there = adj[here][i].first;
int nextDist = cost + adj[here][i].second;
if(dist[there] > nextDist){
dist[there] = nextDist;
pq.push(make_pair(-nextDist, there));
parent[there] = here;
}
}
}
return dist;
}
vector<int> shortestPath(int v){//위의 정보를 바탕으로 경로를 계산해 내는법
vector<int> path(1,v);
while(parent[v] != v){
v = parent[v];
path.push_back(v);
}
reverse(path.begin(),path.end());
return path;
}시간 복잡도
다익스트라 알고리즘의 시간 복잡도를 계산하기 위해서 위의 코드를 잠깐 분석해 봅시다.
- 각 정점마다 인접한 간선을 탐색하는 과정
- 우선순위 큐에서 원소를 넣고 꺼내는 과정
이렇게 두가지의 과정으로 이루어 져있음을 알 수 있습니다. 우선 간선에 대해서는, 모든 간선은 한번씩만 검사되므로, 간선을 검사하는 데에는 의 시간이 걸림을 알 수 있습니다.
우선순위 큐에 대해서도 살펴봅시다. 모든 정점이 큐에 한번씩만 들어가므로 큐의 최대 크기는 O(|V|) 입니다. 하지만, dist[]가 갱신될 때, 원래 큐에 있던 원소를 다시 한 번 더 큐에 넣을수도 있지요. 최악의 상황으로, 모든 간선이 검사할 때 마다 dist[]가 갱신되어, 큐에 정보가 들어 가는 상황을 생각해봅시다. 이때 추가는 각 간선마다 최대 한번 일어나기 때문에, 우선순위 큐에 추가되는 최악의 상황은 O(|E|)가 됩니다. 우선순위 큐에서 원소를 추가하거나 삭제할때는 의 시간복잡도가 필요하므로, 우선순위 큐에서의 최악의 시간 복잡도는 가 되겠습니다.
이 두 작업에 걸리는 시간을 더하면 가 됩니다.
대부분의 경우 그래프의 간선의 개수 는 보다 작으므로, 라고 해도 얼추 맞습니다. 정점의 수가 매우 많거나, 간선의 수가 작을떄는, 우선순위 큐를 사용하지 않고 구현을 하여서 로 구현을 할 수도 있습니다.
번외 : 다익스트라 알고리즘은 생각보다 어렵지 않다!
맨 처음에 학교에서 다익스트라 일고리즘을 접한것은, 알고리즘에 관해서 무지하고, 자료구조 수업을 듣지 않은 1학년 시절 들은 "소셜 네트워크" 라는 과목에서 였다. 스택, 큐와 같은 간단한 자료구조도 직접 짜보지도 않은, 거의 아무것도 모르는 어린아이와 같은 기분으로 처음 들은 다익스트라 알고리즘에 관한 설명은 너무나 어려운 것이었다. 그때, 들을 수업에 소셜이라는 이름이 붙었다고 수업을 들으러온 사회학과 친구들 또한 모르기는 매한가지였다. 그래서 그 수업에서는 교수님이 다익스트라 알고리즘에 관한 내용은 그렇게 심도 있게 다루지는 않았고, 그때의 나는 다익스트라 알고리즘이 정말로 신성하고 복잡한 무언가인줄만 알았다.
하 지 만 지금의 자료구조 수업을 듣고, 종만북을 여러번 읽으면서 공부를 해보니, 다익스트라 알고리즘은, 알고리즘의 제안자 다익스트라씨가 차 마시다가 노트에 끄적거린거 몇번으로 나올 수 있을만큼 나름 심플한 알고리즘임을 알았다. 진짜 멀리 갈 필요 없다. BFS를 구현 하되, BFS에서는 큐를 쓰지만, 간선의 가중치에 따라서 우선 탐색을 해야하니, 우선순위 큐를 쓰면 되는 것이었다. 진짜 그게 끝이다. 그래서 BFS와 함께 다익스트라 알고리즘을 한 글에다 담아 본 것이다.
BFS, 다익스트라 알고리즘을 쓰면 좋을 때
위에서 말했듯이, 이 두 알고리즘은 가중치가 없거나, 음수 가중치가 없는 그래프라면 속도가 뒤에서 설명할 알고리즘 보다는 빠르기 때문에 쓰기 유용합니다. 단순히 속도 에서만 유리한것이 아닙니다.
뒤에서 설명할 알고리즘들은 그래프 전체가 주어져야지 제 기능을 할 수 있는 반면, 위 두 알고리즘은, 그래프의 일부분들을 이용해서 문제를 해결할 수 있습니다. 정확하게 말하자면 정점과, 그 정점에 이웃한 정점들, 그리고 그 정점들로 향하는 간선의 정보만 정확히 알고 있으면 됩니다.
이 글을 읽으면서 고개를 갸우뚱 하실 수 있습니다. 아무튼 그런 정보를 정확히 얻는것과, 그래프 전체의 정보를 가지고 있는것의 차이가 뭔지 몸으로 잘 와닫지 않을 수 있으니까요.
이 장점이 크게 두드러 질 때는, 그래프가 무한할 때 입니다. 문제 상황을 상태 정점과, 그 정점을 잇는 간선들의 상태 그래프로 나타낼 때, 가능한 상태가 무한히 많은 경우가 있습니다. 그러한 예시를 잘 보여주는 문제 중 하나가, BOJ 12851 : 숨바꼭질 2입니다. 문제에서 수빈이가 있을 수 있는 위치는 말 그대로 무한합니다. 시간을 들여서 가지 못할 곳이 없으니까요. 그래서 이 문제를 풀 때는, 뒤에서 설명할 플로이드 알고리즘, 벨만-포드 알고리즘을 쓰지 않고, BFS 를 이용해서 풉니다.
이 문제의 후속 문제라고 할 수 있는 BOJ 13549 : 숨바꼭질 3에서는, 이동 방법에 따라서, 시간이 달라지므로, 즉 간선마다의 가중치가 달라지므로, 단순 큐를 사용한 BFS가 아닌, 큐를 우선순위 큐로 바꾼 알고리즘, 즉 다익스트라 알고리즘을 문제를 풀이 할 수 있습니다.
참고한 글
프로그래밍 대회에서 배우는 알고리즘 문제 해결 전략(구종만 저)
위키백과 플로이드-워셜 알고리즘 항목


너비우선탐색입니다