
[혼자 공부하는 머신러닝+딥러닝] 책에 기반한 정리글입니다.
전체 소스코드는 아래 Github 링크에서 확인할 수 있습니다.
0. 개요
책의 본격적인 시작과 함께 머신러닝 알고리즘 중 하나인
scikit-learn의 K-최근접 이웃을 소개합니다.
데이터 시각화 도구인 matplotlib으로 데이터의 특성을 확인하고
사이킷런으로 2개의 종류를 분류하는 머신러닝 모델을 훈련합니다.
1. 두 개의 산점도를 그래프로 시각화하기
1-1. 각각 도미와 빙어의 길이, 무게 리스트만들기
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]1-2. 두 개의 산점도를 한 그래프로 표현
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()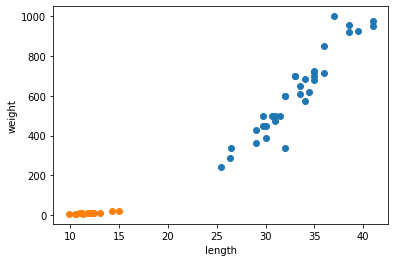
여기서 빙어와 도미의 특성을 파악할 수 있습니다.
- 빙어는 도미에 비해 길이와 무게가 매우 작다.
- 빙어는 무게가 길이에 영향을 크게 받지 않는다.
2. 사이킷런으로 모델 훈련하기
K-최근접 이웃 알고리즘으로 빙어와 도미를 구분하는 모델을 훈련합니다.
2-1. 각 생선의 길이와 무게를 합친 2차원 리스트 만들기
# 리스트 합치기
length = bream_length + smelt_length
weight = bream_weight + smelt_weight
fish_data = [[l,w] for l, w in zip(length, weight)] #2차원 리스트를 만드는 list comprehension(리스트 내포)
fish_target = [1] * 35 + [0] * 14 #도미를 1로, 빙어를 0으로 놓은 정답 리스트2-2. K 최근접 이웃 알고리즘 이용
K 최근접 이웃 알고리즘
어떤 데이터에 대한 답을 구할 때 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용함.
데이터를 모두 가지고 있어야 하고, 새로운 데이터에 대해 예측할 때 가장 가까운 직선거리에 어떤 데이터가 있는지 파악한다.
단, 데이터가 크기 때문에 메모리가 많이 필요하며 직선거리 계산에 많은 시간이 소요된다.
from sklearn.neighbors import KNeighborsClassifier
# K 최근접 이웃 사용
kn = KNeighborsClassifier() #import한 클래스의 객체생성
kn.fit(fish_data, fish_target) #사이킷런 모델을 훈련할 때 사용하는 메서드, 두 매개변수로 훈련에 사용할 특성, 정답 데이터 전달
kn.score(fish_data, fish_target)
#훈련된 사이킷런 모델 성능 측정
#두 매개변수로 특성과 정답 데이터를 전달함
#먼저 predict()메서드로 예측을 수행한 후 정답과 비교하여 올바르게 예측한 개수의 비율을 반환함출력 1.0
매개변수로 주어진 fish_data를 훈련된 모델에 따라 완벽하게 분류했다.
kn.predict([[30, 600], [12,3]])출력 array([1, 0])
print(kn._fit_X) #fish data 반환
print(kn._y) #fish target 정답데이터 반환각각 주어진 데이터와, 정답데이터를 반환한다.
kn49 = KNeighborsClassifier(n_neighbors=49) #참고 데이터를 49개로 한 모델, 기본값은 5
kn49.fit(fish_data, fish_target)
kn49.score(fish_data, fish_target)
#데이터 49개 중 도미가 35개이므로, 어떤 데이터를 넣어도 도미로 예측함
#따라서 기본값인 5가 더 좋음출력 0.7142857142857143
주어진 모든 데이터를 참고하므로, 모든 값을 도미로 예측한다.
정확도가 떨어지기 때문에 현 모델에서는 기본값인 5가 더 좋다는 것을 알 수 있다.
기본 참고 데이터 값은 5지만, n_neighbors 인자를 통해 값을 조절할 수 있다.

어제보다 성장한 오늘
멋있으시네요😎