
0. 개요
현재 저는 교내 임베디드 관련 연구실에서 학부연구생으로 근무하고 있습니다. 이번에 새로 진행할 프로젝트에서 real-time object detection을 수행하기 위해 YOLOv5 모델을 적용 가능할지 검토하기 위해 개발환경을 구성하고 제공되는 샘플 데이터로 훈련 및 직접 사진과 영상을 넣어 예측해보았습니다.
1. YOLO 모델이란
YOLO(You Only Look Once) 모델은 real-time object detection을 수행하기 위해 만들어진 딥러닝 모델입니다.
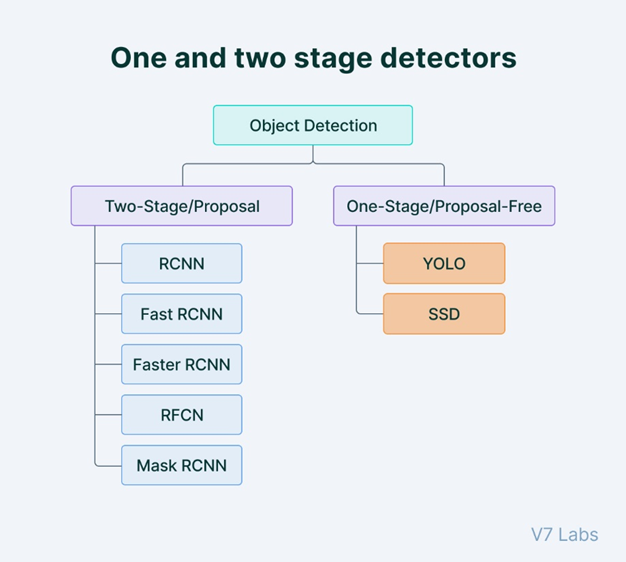
일반적인 RCNN, Fast-RCNN 같은 모델은 Two-step Algorithm으로, region-proposal과 clasisfication의 두 단계로 나누어집니다.
반면 YOLO 모델은 1-Stage Detection으로, proposal과 classification이 동시에 이루어지는 방식입니다. 이 때문에 real-time object detection에 더 유리합니다.
2. YOLO 모델의 버전별 차이
YOLO의 각 버전
- YOLOv3 : YOLO를 만든 Josept Redmon이 YOLOv3까지 발표하고 업데이트하였으나, 이후 더 이상 개발하지 않는다고 합니다. Darknet 프레임워크로 구현되어 있습니다.
- YOLOv4 : 다른 개발자가 2020년 4월에 출시하였으며 v3에 비해 약 10% 정도의 성능 향상이 있습니다. 다양한 딥러닝 기법을 통해 성능이 향상되었습니다.
- YOLOv5 : 2020년 6월에 출시되었고, v4와 비교하여 비슷한 성능, 낮은 용량, 빠른 속도를 가집니다. 이전 버전과 다르게 PyTorch 기반으로 구성되었습니다.
저는 YOLOv4, YOLOv5를 비교한 끝에 개발환경을 구성하기 더 쉽고, PyTorch로 인해 적응하기 쉬울 것으로 예상되는 v5를 선택했습니다.
단 추후에 훈련 데이터가 확보되면 각 모델의 성능 비교 후에 더 좋은 모델을 선택할 것입니다. 어쩌면 이 YOLO 모델보다 Faster RCNN 등의 모델이 더 좋은 결과를 보여줄 수 있기 때문에 YOLO 모델을 선택하지 않을 수도 있습니다.
YOLOv5의 다양한 모델
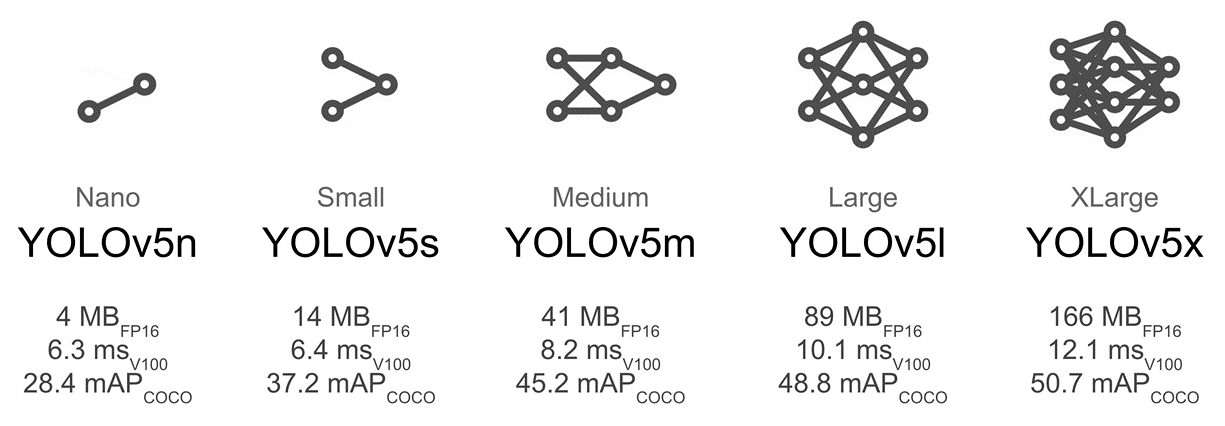
한편, YOLOv5에도 다양한 모델들이 존재합니다.
Nano 부터 XLarge까지 다양한 모델을 선택할 수 있는데, 오른쪽 모델로 갈수록 성능은 좋아지지만, 모델이 무거워지고 검출 가능한 fps가 감소합니다. 이는 결과적으로 real-time object detecting에 유리하지 않기 때문에 각각을 비교하며 좋은 모델을 찾아야 합니다.
3. 리눅스 서버 환경 구성 및 YOLOv5 설치
개발환경 구성
먼저 개발환경부터 구성합니다. 교내 인공지능센터의 서버를 대여하여 진행하였습니다.
운영체제는 Ubuntu 20.04.3 LTS 이며, i9-10940X, Quadro RTX 8000 * 2 로 구성되어 있습니다.
Python 3.8.11, CUDA 9.1 버전에서 진행하였습니다.
PuTTY의 SSH로 서버와 원격 통신을 진행하였으며, FileZilla로 서버와 파일을 주고받고 VsCode의 ftp-simple 플러그인으로 모델의 코드를 수정하였습니다.
YOLOv5 설치
YOLOv5의 깃허브 Readme에서 튜토리얼을 확인할 수 있습니다.
YOLOv5 GITHUB : https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
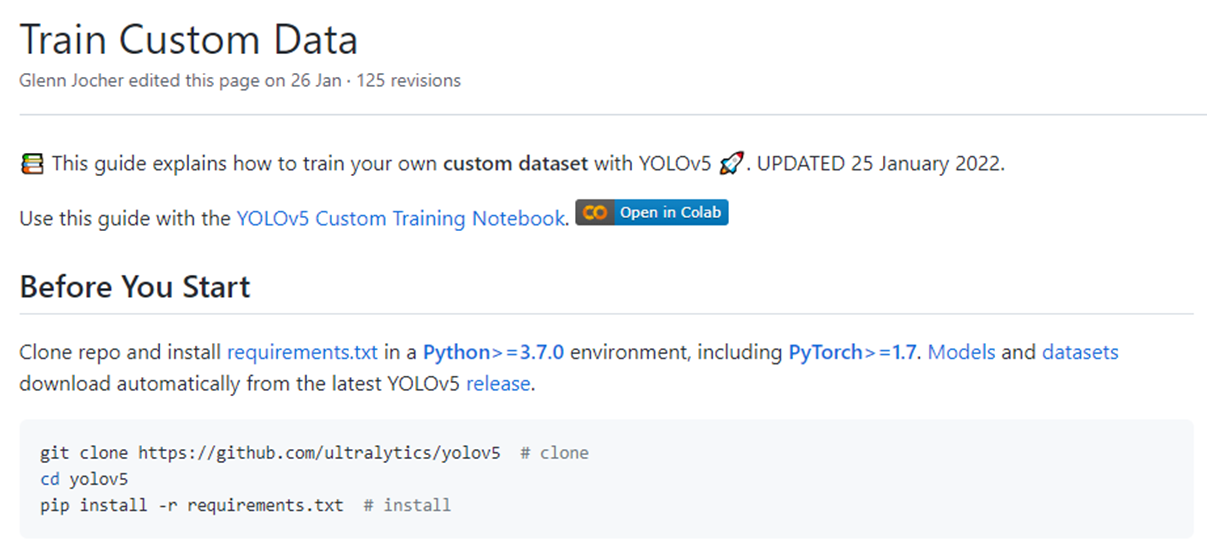
git clone 후 requirements.txt를 pip로 설치해준다면 자동으로 모든 개발환경이 구성됩니다.
YOLOv5s 모델 훈련
샘플 데이터 또한 준비되어있습니다.
python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt
coco128.yaml 파일에는 각종 하이퍼파라미터와 훈련 데이터 다운로드 링크 등이 들어있습니다.
이미지의 크기나 배치 개수, 에포크 횟수, 모델 선택이 가능합니다.

validation set의 레이블링 예측 결과입니다. s 모델인데도 불구하고 좋은 정확도로 나온 것을 볼 수 있습니다.
4. 실제 환경에서의 오브젝트의 예측
YOLOv5s 모델에서의 오브젝트 예측

직접 찍은 사진의 예측 결과입니다. 좋은 정확도를 보여줍니다.

고고도에서 촬영한 영상입니다. 달리는 차를 좋은 정확도로 예측할 수 있습니다.
YOLOv5s와 YOLOv5xl의 성능 비교
두 모델을 샘플데이터로 훈련하여 각각 데이터를 예측해보았습니다.
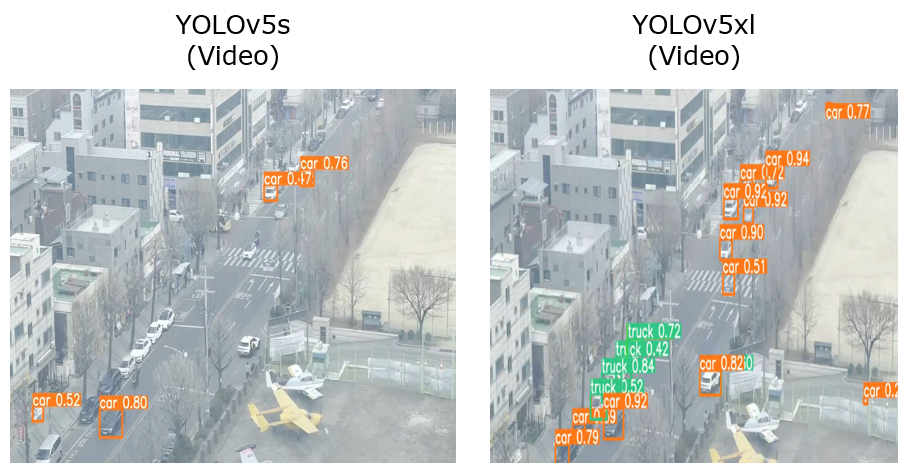
확실히 s 모델보다는 xl모델이 더 좋은 정확도와 많은 오브젝트 디텍팅이 가능한 것을 확인할 수 있습니다.

마찬가지의 결과입니다. 더 좋은 정확도, 많은 오브젝트 디텍팅이 가능합니다.

저조도 환경에서의 비교입니다. 두 모델 다 훌륭하게 오브젝트를 예측합니다.
5. Wandb 웹페이지 연동
Wandb : https://wandb.ai/home
홈페이지에서 튜토리얼을 확인할 수 있습니다.
YOLO5는 Wandb와의 연동을 지원합니다. 웹페이지에서 모델의 정확도나 손실, 시스템에서의 cpu 및 gpu 사용량 등의 세부정보를 확인할 수 있습니다.
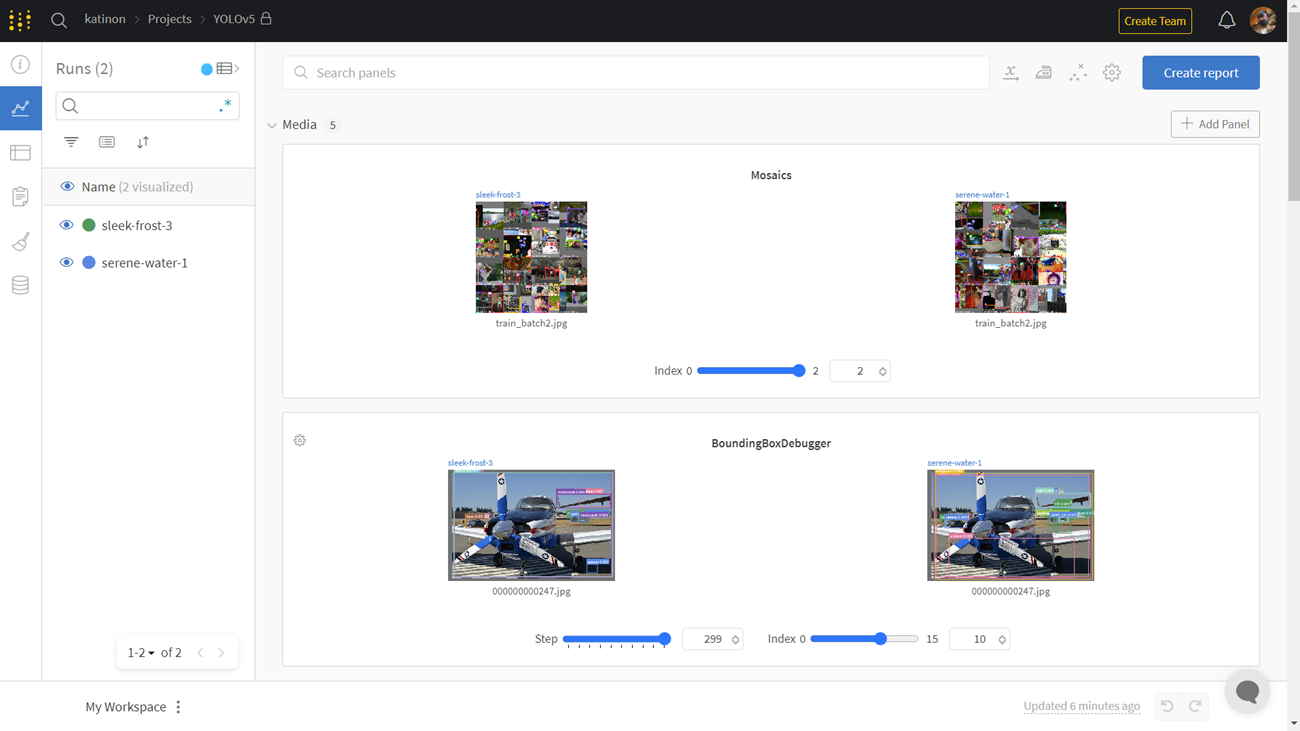
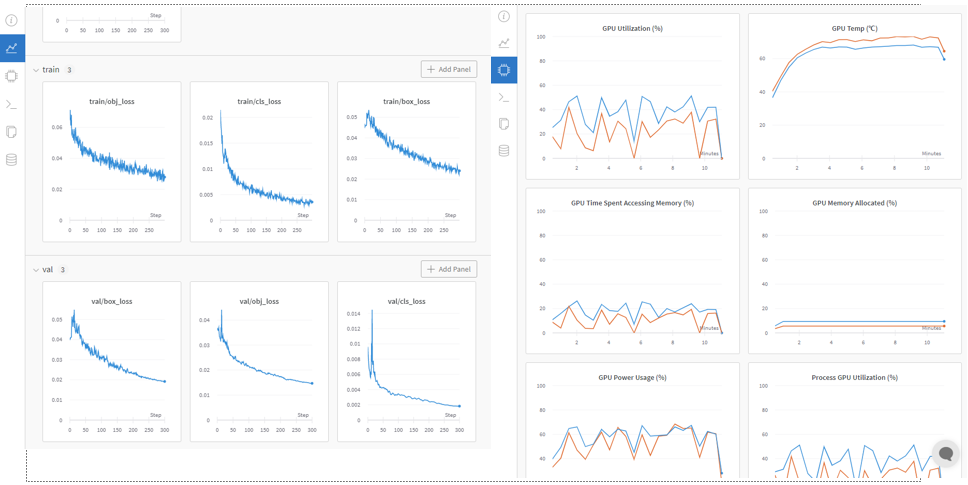
6. 결론 및 검증사항
YOLOv5는 분명 사용하기 쉽고 좋은 정확도를 가진 모델입니다. 그러나 우리가 준비할 훈련 데이터가 이 모델과 정말 잘 맞는지, 어느 정도의 정확도와 loss를 보여주는지 타 모델과 비교하여 확인해 보아야 합니다.
이제 훈련 데이터를 준비해야 합니다. 훈련 데이터를 모델에 맞게 재가공하고, 레이블링해야합니다. 훈련 데이터가 준비된다면 타 모델과 비교하고, 어느 부분이 부족하며 어느 부분을 최적화해야 하는지를 고민해보아야 합니다.
