Review - Mean Squared Error(MSE)
Mean Squared Error(MSE) criterion
m s e ( θ ^ ) = E [ ( θ ^ − θ ) 2 ] = v a r ( θ ^ ) + b 2 ( θ ) mse(\hat \theta) = E[(\hat \theta -\theta)^2] =var(\hat \theta) + b^2(\theta) m s e ( θ ^ ) = E [ ( θ ^ − θ ) 2 ] = v a r ( θ ^ ) + b 2 ( θ )
Note that, in many cases, minimum MSE criterion leads to unrealizable estimator , which cannot be written solely as a function of the data, i.e.,
A ˇ = a 1 N ∑ n = 0 N − 1 x [ n ] , A : u n k n o w n o b j e c t i v e : e s t i m a t e A f r o m x [ n ] \widecheck A =a\dfrac{1}{N}\displaystyle\sum_{n=0}^{N-1}x[n],\;A\;:\;unknown\\objective\;:\;estimate\;A\;from\;x[n] A = a N 1 n = 0 ∑ N − 1 x [ n ] , A : u n k n o w n o b j e c t i v e : e s t i m a t e A f r o m x [ n ]
where α \textcolor{red}{\alpha} α minimize MSE
E ( A ˇ ) = α A , v a r ( A ˇ ) = a 2 σ 2 N → m s e ( A ˇ ) = a 2 σ 2 N + ( a − 1 ) 2 A 2 ∴ a o p t = A 2 A 2 + σ 2 / N E(\widecheck A)=\textcolor{red}\alpha A,\;var(\widecheck A)=\dfrac{a^2\sigma^2}{N} \rightarrow mse(\widecheck A)=\dfrac{a^2\sigma^2}{N}+(a-1)^2A^2\\[0.4cm] \therefore a_{opt}=\dfrac{A^2}{A^2+\sigma^2/N} E ( A ) = α A , v a r ( A ) = N a 2 σ 2 → m s e ( A ) = N a 2 σ 2 + ( a − 1 ) 2 A 2 ∴ a o p t = A 2 + σ 2 / N A 2
Review - MVUE
Minimum variance unbiased estimator(MVUE)Alternatively, constrain the bias to be zero
Find the estimator which minimizes the variance ⋯ ( ∗ ) \cdots\textcolor{red}{~ (*)} ⋯ ( ∗ )
Minimuzing the MSE as well for unbiased case
m s e ( θ ^ ) = v a r ( θ ^ ) + b 2 ( θ ) = v a r ( θ ^ ) , E [ b 2 ( θ ) ] = 0 ⋯ ( ∗ ) mse(\hat \theta)=var(\hat \theta) +b^2(\theta)=var(\hat \theta),\;E[b^2(\theta)]=0 \;\cdots\textcolor{red}{~ (*)} m s e ( θ ^ ) = v a r ( θ ^ ) + b 2 ( θ ) = v a r ( θ ^ ) , E [ b 2 ( θ ) ] = 0 ⋯ ( ∗ )
That's Minimum variance unbiased estimator so called MVUE
Then... how can we know MVUE Exsist!!!?
Outline
Cramer-Rao Lower Bound(CRLB)
Estimator Accuracy Considerations
CRLB for a Scalar ParameterCRLB ProofGeneral CRLB for Signals in WGN
Transformation of Parameters
Vector form of the CRLB
General Gaussian Case and Fisher Infromation
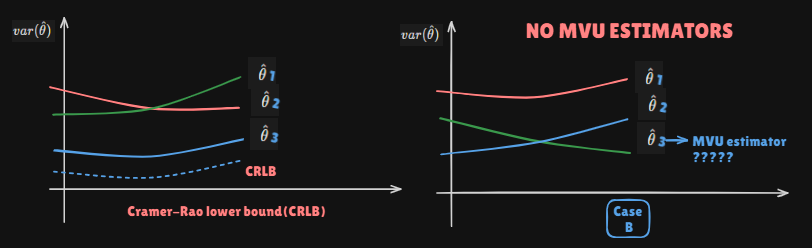
Cramer-Rao Lower Bound(CRLB)
Cramer-Rao Lower Bound(CRLB) or Cramer-Rao Bound(CRB) - Same things
The CRLB give a lower bound on the variance of any unbiased estimator
Does not guarantee bound can be obtained
If one finds out an unbiased estimator whose variance = CRLB then it's MVUE(very very very very ideal cases...)
Otherwise can use Ch.5 tools(Rao-Blackwell-Lehmann-Scheffe Teorem and Neyman-Fisher Facorization Theorem) to construct a better estimator from any unbiased one-possibly the MVUE if condidtions are met
Estimator Accuracy Considerations
All information is observed data and underlying PDF
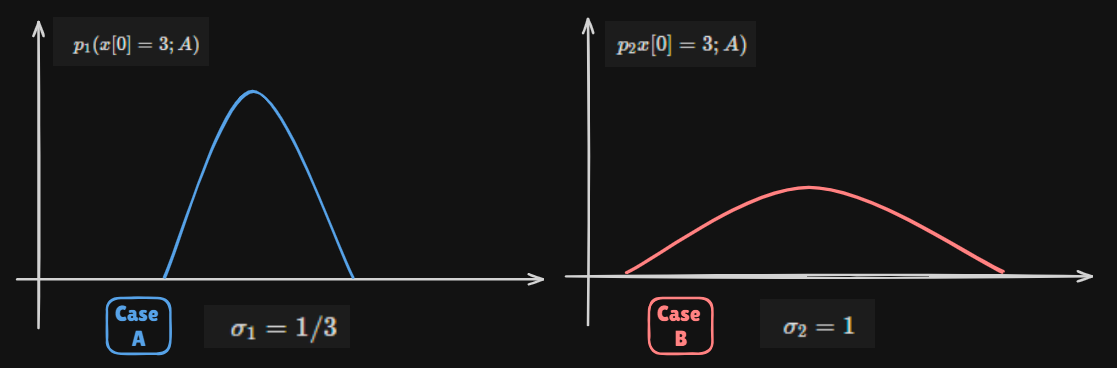
Estimation accuracy depends directly on the PDF
For example) PDF dependence on unknown parameter
Signal sample observation
x [ 0 ] = A + w [ 0 ] , w [ 0 ] ∼ N ( 0 , σ 2 ) N ( 0 , σ 2 ) : A d a p t i v e W h i t e G a u s s i a n N o i s e x[0]=A+w[0],\;w[0] \sim \mathcal{N}(0, \sigma^2)\\ \mathcal{N}(0, \sigma^2)\;:\;Adaptive\;White\;Gaussian\;Noise x [ 0 ] = A + w [ 0 ] , w [ 0 ] ∼ N ( 0 , σ 2 ) N ( 0 , σ 2 ) : A d a p t i v e W h i t e G a u s s i a n N o i s e
Good unbiased estimator : A ^ = x [ 0 ] \hat A =x[0] A ^ = x [ 0 ]
The smaller σ 2 \sigma^2 σ 2 better the estimator accuracy is
Alternatively, likelihood function(≠ \neq =
p i ( x [ 0 ] ; A ) = 1 2 π σ i 2 e x p [ − 1 2 σ i 2 ( x [ 0 ] − A ) 2 ] p_i(x[0];A)=\dfrac{1}{\sqrt{2\pi\sigma_i^2}}exp\left[-\dfrac{1}{2\sigma_i^2}(x[0]-A)^2\right] p i ( x [ 0 ] ; A ) = 2 π σ i 2 1 e x p [ − 2 σ i 2 1 ( x [ 0 ] − A ) 2 ]
Likelihood : What is Prob for θ = A \theta =A θ = A Variance indicates how estimators Accurate The Sharpness of the likelihood function determines the accuracy of the estimate
Measured by the curvature of the log-likelihood function
It's negative of the second derivative of the logarithm of the likelihood function at its peak. i.e.,
l n p ( x [ 0 ] ; A ) = − l n 2 π σ 2 − 1 2 σ 2 ( x [ 0 ] − A 2 ) , ∂ 2 ∂ A 2 → − l n 2 π σ 2 = 0 , n o A d e p e n d e n c y − ∂ 2 l n p ( x [ 0 ] ; A ) ∂ A 2 = 1 σ 2 , v a r ( A ^ ) = σ 2 = 1 ∂ 2 l n p ( x [ 0 ] ; A ) ∂ A 2 lnp(x[0];A)=-ln\sqrt{2\pi\sigma^2}-\dfrac{1}{2\sigma^2}(x[0]-A^2),\\ \dfrac{\partial^2}{\partial A^2} \rightarrow -ln\sqrt{2\pi\sigma^2}=0,\;no\;A\;dependency\\[0.5cm] -\dfrac{\partial^2 lnp(x[0];A)}{\partial A^2}=\dfrac{1}{\sigma^2},\quad var(\hat A)=\sigma^2=\dfrac{1}{\dfrac{\partial^2lnp(x[0];A)}{\partial A^2}} l n p ( x [ 0 ] ; A ) = − l n 2 π σ 2 − 2 σ 2 1 ( x [ 0 ] − A 2 ) , ∂ A 2 ∂ 2 → − l n 2 π σ 2 = 0 , n o A d e p e n d e n c y − ∂ A 2 ∂ 2 l n p ( x [ 0 ] ; A ) = σ 2 1 , v a r ( A ^ ) = σ 2 = ∂ A 2 ∂ 2 l n p ( x [ 0 ] ; A ) 1
Average curvature : − E [ ∂ 2 l n p ( x [ 0 ] ; A ∂ A 2 ] -E\left[\dfrac{\partial ^2ln\;p(x[0];A}{\partial A^2}\right] − E [ ∂ A 2 ∂ 2 l n p ( x [ 0 ] ; A ]
In general, the 2 n d 2^{nd} 2 n d x [ 0 ] → x[0] \rightarrow x [ 0 ] → likelihood function is a R.V.
Theorem : Cramer-Rao Lower Bound(CRLB) - Scalar Parameter
Let p ( x ; θ ) p(x;\theta) p ( x ; θ ) regularity condition :
E [ ∂ l n p ( x ; θ ) ∂ θ ] = 0 f o r a l l θ E\left[\dfrac{\partial \;ln\;p(x;\theta)}{\partial \theta}\right]=0\;for\;all\;\theta E [ ∂ θ ∂ l n p ( x ; θ ) ] = 0 f o r a l l θ
Then, the variance of any unbiased estimator θ ^ \hat \theta θ ^
v a r ( θ ^ ) ≥ 1 − E [ ∂ 2 l n p ( x ; θ ) ∂ θ 2 ] = 1 E [ ( ∂ l n p ( x ; θ ) ∂ θ ) 2 ] var(\hat \theta)\geq\dfrac{1}{-E\left[\dfrac{\partial^2\;ln\;p(x;\theta)}{\partial \theta^2}\right]}=\dfrac{1}{E\left[\left(\dfrac{\partial\;ln\;p(x;\theta)}{\partial\theta}\right)^2\right]} v a r ( θ ^ ) ≥ − E [ ∂ θ 2 ∂ 2 l n p ( x ; θ ) ] 1 = E [ ( ∂ θ ∂ l n p ( x ; θ ) ) 2 ] 1
Where the derivative is evaluated at the true value of θ \theta θ p ( x ; θ ) p(x;\theta) p ( x ; θ )
Furthermore, an unbiased estimator may be founc that attains the bound for all θ \theta θ
∂ l n p ( x ; θ ) ∂ θ = I ( θ ) ( g ( x ) − θ ) \dfrac{\partial\;ln\;p(x;\theta)}{\partial \theta}=I(\theta)(g(x)-\theta) ∂ θ ∂ l n p ( x ; θ ) = I ( θ ) ( g ( x ) − θ )
For some functions g ( x ) g(x) g ( x ) I I I estimator, which is the MVUE, is θ ^ = g ( x ) \hat \theta =g(x) θ ^ = g ( x ) 1 / I ( θ ) 1/I(\theta) 1 / I ( θ )
To sum up : If some functions's logarithm cavarture could be decomposed just like I ( θ ) ( g ( x ) − θ ) I(\theta)(g(x)-\theta) I ( θ ) ( g ( x ) − θ ) Then g ( x ) g(x) g ( x )
CRLB Proof (Appendix 3A)
CRLB for a scalar parameter α = g ( θ ) \alpha =g(\theta) α = g ( θ ) PDF is parameterized with θ \theta θ
Consider unbiased estimator α ^ \hat \alpha α ^
E ( α ^ ) = ∫ a ^ p ( x ; θ ) d x = α = g ( θ ) ⋯ ( ∗ ) E(\hat \alpha) =\int\hat ap(x;\theta)dx=\alpha=g(\theta)\cdots\textcolor{red}{(*)} E ( α ^ ) = ∫ a ^ p ( x ; θ ) d x = α = g ( θ ) ⋯ ( ∗ )
Regularity condition : holds if the order of differentiation and integration may be interchanged
E [ ∂ l n p ( x ; θ ) ∂ θ ] = ∫ ∂ l n p ( x ; θ ) ∂ θ p ( x ; θ ) d x = 0 E\left[\dfrac{\partial\;ln\;p(x;\theta)}{\partial \theta}\right]=\int\dfrac{\partial\;ln\;p(x;\theta)}{\partial\theta}p(x;\theta)dx=0 E [ ∂ θ ∂ l n p ( x ; θ ) ] = ∫ ∂ θ ∂ l n p ( x ; θ ) p ( x ; θ ) d x = 0
Differentiating both sides of ( ∗ ) \textcolor{red}{(*)} ( ∗ )
∫ α ^ ∂ p ( x ; θ ) ∂ θ d x = ∂ g ( θ ) ∂ θ → ∫ α ^ ∂ l n p ( x ; θ ) ∂ θ p ( x ; θ ) d x ⋯ ( ∗ ∗ ) = ∂ g ( θ ) ∂ θ \int\hat \alpha\dfrac{\partial\;p(x;\theta)}{\partial\theta}dx=\dfrac{\partial\;g(\theta)}{\partial \theta}\\ \rightarrow \int\hat \alpha\dfrac{\partial\;ln\;p(x;\theta)}{\partial \theta}p(x;\theta)dx\cdots\textcolor{red}{(**)}=\dfrac{\partial g(\theta)}{\partial \theta} ∫ α ^ ∂ θ ∂ p ( x ; θ ) d x = ∂ θ ∂ g ( θ ) → ∫ α ^ ∂ θ ∂ l n p ( x ; θ ) p ( x ; θ ) d x ⋯ ( ∗ ∗ ) = ∂ θ ∂ g ( θ )
∂ ∂ θ l n C ( θ ) = 1 C ( θ ) ∂ C ( θ ) ∂ θ , C ( θ ) = P ( x ; θ ) ⋯ ( ∗ ∗ ) \dfrac{\partial}{\partial\theta}ln\;C(\theta)=\dfrac{1}{C(\theta)}\dfrac{\partial\;C(\theta)}{\partial\theta},\;C(\theta)=P(x;\theta)\cdots\textcolor{red}{(**)} ∂ θ ∂ l n C ( θ ) = C ( θ ) 1 ∂ θ ∂ C ( θ ) , C ( θ ) = P ( x ; θ ) ⋯ ( ∗ ∗ )
By using regularity condition,
∫ ( α ^ − α ) ∂ l n p ( x ; θ ) ∂ θ p ( x ; θ ) d x = ∂ g ( θ ) ∂ θ \int\textcolor{blue}{(\hat \alpha-\alpha)}\dfrac{\partial \;ln\;p(x;\theta)}{\partial \theta}p(x;\theta)dx=\dfrac{\partial\;g(\theta)}{\partial\theta} ∫ ( α ^ − α ) ∂ θ ∂ l n p ( x ; θ ) p ( x ; θ ) d x = ∂ θ ∂ g ( θ )
By using Cauchy-Schwarz inequality,
( ∂ g ( θ ) ∂ θ ) 2 ≤ ∫ ( α ^ − α ) 2 p ( x ; θ ) d x ∫ ( ∂ l n p ( x ; θ ) ∂ θ ) 2 p ( x ; θ ) d x ∫ ( α ^ − α ) 2 p ( x ; θ ) d x = E [ ( α ^ − E [ α ^ ] ) 2 = E [ ( α ^ − α ) 2 ] ∴ v a r ( α ^ ) ≥ ( ∂ g ( θ ) ∂ θ ) 2 E [ ( ∂ l n p ( x ; θ ) ∂ θ ) 2 ] \left(\dfrac{\partial g(\theta)}{\partial\theta}\right)^2\leq\int(\hat \alpha -\alpha)^2p(x;\theta)dx\int\left(\dfrac{\partial\;ln\;p(x;\theta)}{\partial\theta}\right)^2p(x;\theta)dx\\[0.5cm] \int(\hat\alpha-\alpha)^2p(x;\theta)dx=E[(\hat \alpha-E[\hat \alpha])^2=E[(\hat \alpha-\alpha)^2]\\[0.5cm] \therefore var(\hat \alpha) \geq \dfrac{\left(\dfrac{\partial\;g(\theta)}{\partial\theta}\right)^2}{E\left[\left(\dfrac{\partial\;ln\;p(x;\theta)}{\partial \theta}\right)^2\right]} ( ∂ θ ∂ g ( θ ) ) 2 ≤ ∫ ( α ^ − α ) 2 p ( x ; θ ) d x ∫ ( ∂ θ ∂ l n p ( x ; θ ) ) 2 p ( x ; θ ) d x ∫ ( α ^ − α ) 2 p ( x ; θ ) d x = E [ ( α ^ − E [ α ^ ] ) 2 = E [ ( α ^ − α ) 2 ] ∴ v a r ( α ^ ) ≥ E [ ( ∂ θ ∂ l n p ( x ; θ ) ) 2 ] ( ∂ θ ∂ g ( θ ) ) 2
Cauchy-Schwarz Inequality
[ ∫ w ( x ) g ( x ) h ( x ) d x ] 2 ≤ ∫ w ( x ) g 2 ( x ) d x ∫ w ( x ) h 2 ( x ) d x \left[\int w(x)g(x)h(x)dx\right]^2\leq\int w(x)g^2(x)dx\int w(x)h^2(x)dx [ ∫ w ( x ) g ( x ) h ( x ) d x ] 2 ≤ ∫ w ( x ) g 2 ( x ) d x ∫ w ( x ) h 2 ( x ) d x
Arbitrary function g ( x ) g(x) g ( x ) h ( x ) h(x) h ( x ) w ( x ) ≥ 0 w(x)\geq0 w ( x ) ≥ 0 x x x
Equality holds in and only ifg ( x ) = c h ( x ) g(x)=c\;h(x) g ( x ) = c h ( x )
By differentiating the regularity condition,
∂ ∂ θ ∫ ∂ l n p ( x ; θ ) ∂ θ p ( x ; θ ) d x = 0 ∫ [ ∂ 2 l n p ( x ; θ ) ∂ θ 2 p ( x ; θ ) + ∂ l n p ( x ; θ ) ∂ θ ∂ p ( x ; θ ) ∂ θ ] d x = 0 − E [ ∂ 2 l n p ( x ; θ ) ∂ θ 2 ] = ∫ ∂ l n p ( x ; θ ) ∂ θ ∂ l n p ( x ; θ ) ∂ θ p ( x ; θ ) d x = E [ ( ∂ l n p ( x ; θ ) ∂ θ ) 2 ] → v a r ( α ^ ) ≥ ( ∂ g ( θ ) ∂ θ ) 2 E [ ( ∂ l n p ( x ; θ ) ∂ θ ) 2 ] = ( ∂ g ( θ ) ∂ θ ) 2 − E [ ∂ 2 l n p ( x ; θ ) ∂ θ 2 ] \dfrac{\partial}{\partial\theta}\int\dfrac{\partial\;ln\;p(x;\theta)}{\partial\theta}p(x;\theta)dx=0\\[0.5cm] \int\left[\dfrac{\partial^2\;ln\;p(x;\theta)}{\partial\theta^2}p(x;\theta)+\dfrac{\partial\;ln\;p(x;\theta)}{\partial\theta}\dfrac{\partial p(x;\theta)}{\partial\theta}\right]dx=0\\[0.5cm] -E\left[\dfrac{\partial^2\;ln\;p(x;\theta)}{\partial \theta^2}\right]=\int \dfrac{\partial\;ln\;p(x;\theta)}{\partial\theta}\dfrac{\partial\;ln\;p(x;\theta)}{\partial\theta}p(x;\theta)dx\\[0.5cm] =E\left[\left(\dfrac{\partial\;ln\;p(x;\theta)}{\partial \theta}\right)^2\right]\\[0.5cm] \rightarrow var(\hat \alpha)\geq\dfrac{\left(\dfrac{\partial\;g(\theta)}{\partial\theta}\right)^2}{E\left[\left(\dfrac{\partial\;ln\;p(x;\theta)}{\partial\theta}\right)^2\right]}=\dfrac{\left(\dfrac{\partial\;g(\theta)}{\partial\theta}\right)^2}{-E\left[\dfrac{\partial^2\;ln\;p(x;\theta)}{\partial\theta^2}\right]} ∂ θ ∂ ∫ ∂ θ ∂ l n p ( x ; θ ) p ( x ; θ ) d x = 0 ∫ [ ∂ θ 2 ∂ 2 l n p ( x ; θ ) p ( x ; θ ) + ∂ θ ∂ l n p ( x ; θ ) ∂ θ ∂ p ( x ; θ ) ] d x = 0 − E [ ∂ θ 2 ∂ 2 l n p ( x ; θ ) ] = ∫ ∂ θ ∂ l n p ( x ; θ ) ∂ θ ∂ l n p ( x ; θ ) p ( x ; θ ) d x = E [ ( ∂ θ ∂ l n p ( x ; θ ) ) 2 ] → v a r ( α ^ ) ≥ E [ ( ∂ θ ∂ l n p ( x ; θ ) ) 2 ] ( ∂ θ ∂ g ( θ ) ) 2 = − E [ ∂ θ 2 ∂ 2 l n p ( x ; θ ) ] ( ∂ θ ∂ g ( θ ) ) 2
if α = g ( θ ) = θ , \text{if} \;\alpha=g(\theta)=\theta, if α = g ( θ ) = θ , var ( θ ^ ) ≥ 1 − E [ ∂ 2 ln p ( x ; θ ) ∂ θ 2 ] = 1 E [ ( ∂ ln p ( x ; θ ) ∂ θ ) 2 ] Condition for equality: ∂ l n p ( x ; θ ) ∂ θ = 1 c ( α ^ − α ) , α ^ = MVUE ∂ l n p ( x ; θ ) ∂ θ = 1 c ( θ ) ( θ ^ − θ ) To determine c( θ ) , ∂ 2 l n p ( x ; θ ) ∂ θ 2 = − 1 c ( θ ) + ∂ ( 1 c ( θ ) ) ∂ θ ( θ ^ − θ ) − E [ ∂ 2 l n p ( x ; θ ) ∂ θ 2 = 1 c ( θ ) = I ( θ ) \text{var}(\hat{\theta}) \geq \frac{1}{-E \left[ \frac{\partial^2 \ln p(x; \theta)}{\partial \theta^2} \right]} = \frac{1}{E \left[ \left( \frac{\partial \ln p(x; \theta)}{\partial \theta} \right)^2 \right]}\\ \text{Condition for equality:}\\ \frac{\partial lnp(x;\theta)}{\partial\theta}=\frac{1}{c}(\hat \alpha-\alpha),\;\hat \alpha=\text{MVUE}\\ \frac{\partial ln p(x;\theta)}{\partial \theta}=\frac{1}{c(\theta)}(\hat \theta - \theta)\\ \text{To determine c(}\theta\text{)},\\ \frac{\partial^2 ln p(x;\theta)}{\partial\theta^2}=-\frac{1}{c(\theta)}+\frac{\partial(\frac{1}{c(\theta)})}{\partial\theta}(\hat \theta - \theta)\\[0.3cm] -E[\frac{\partial^2 ln p(x;\theta)}{\partial \theta^2}=\frac{1}{c(\theta)}=I(\theta) var ( θ ^ ) ≥ − E [ ∂ θ 2 ∂ 2 l n p ( x ; θ ) ] 1 = E [ ( ∂ θ ∂ l n p ( x ; θ ) ) 2 ] 1 Condition for equality: ∂ θ ∂ l n p ( x ; θ ) = c 1 ( α ^ − α ) , α ^ = MVUE ∂ θ ∂ l n p ( x ; θ ) = c ( θ ) 1 ( θ ^ − θ ) To determine c( θ ) , ∂ θ 2 ∂ 2 l n p ( x ; θ ) = − c ( θ ) 1 + ∂ θ ∂ ( c ( θ ) 1 ) ( θ ^ − θ ) − E [ ∂ θ 2 ∂ 2 l n p ( x ; θ ) = c ( θ ) 1 = I ( θ )
CRLB Example - DC Level in WGN
x [ n ] = A + w [ n ] , n = 0 , 1 , … , N − 1 x[n] = A + w[n], \quad n=0,1,\dots,N-1 x [ n ] = A + w [ n ] , n = 0 , 1 , … , N − 1 p ( x ; A ) = 1 ( 2 π σ 2 ) N / 2 exp [ − 1 2 σ 2 ∑ n = 0 N − 1 ( x [ n ] − A ) 2 ] ∂ l n p ( x ; A ) ∂ A = 1 σ 2 ∑ n = 0 N − 1 ( x [ n ] − A ) = N σ 2 ( x ^ − A ) → ∂ 2 l n p ( x ; A ) ∂ A 2 = − N σ 2 var ( A ^ ) ≥ σ 2 N p(x;A)=\frac{1}{(2\pi\sigma^2)^{N/2}}\text{exp}\left[-\frac{1}{2\sigma^2}\displaystyle\sum_{n=0}^{N-1}(x[n]-A)^2\right]\\[0.5cm] \frac{\partial ln p(x;A)}{\partial A}=\frac{1}{\sigma^2}\displaystyle\sum_{n=0}^{N-1}(x[n]-A)=\frac{N}{\sigma^2}(\hat x - A) \rightarrow \frac{\partial^2 ln p (x;A)}{\partial A^2}=-\frac{N}{\sigma^2}\\[0.5cm] \text{var}(\hat A) \geq \frac{\sigma^2}{N} p ( x ; A ) = ( 2 π σ 2 ) N / 2 1 exp [ − 2 σ 2 1 n = 0 ∑ N − 1 ( x [ n ] − A ) 2 ] ∂ A ∂ l n p ( x ; A ) = σ 2 1 n = 0 ∑ N − 1 ( x [ n ] − A ) = σ 2 N ( x ^ − A ) → ∂ A 2 ∂ 2 l n p ( x ; A ) = − σ 2 N var ( A ^ ) ≥ N σ 2
Let A ^ = x ^ \hat A = \hat x A ^ = x ^
CRLB Example - Phase Estimation
x [ n ] = A cos ( 2 π f 0 n + ϕ ) + w [ n ] , n = 0 , 1 , … , N − 1 A , f 0 : known , w [ n ] : WGN x[n] = A \cos(2 \pi f_0 n + \phi) + w[n],\quad n=0,1,\dots,N-1\\A,f_0:\text{known},\;w[n]:\text{WGN} x [ n ] = A cos ( 2 π f 0 n + ϕ ) + w [ n ] , n = 0 , 1 , … , N − 1 A , f 0 : known , w [ n ] : WGN p ( x ; ϕ ) = 1 ( 2 π σ 2 ) N / 2 exp [ − 1 2 σ 2 ∑ n = 0 N − 1 [ x [ n ] − A cos ( 2 π f 0 n + ϕ ) ] 2 ] ∂ l n p ( x ; ϕ ) ∂ ϕ = − A σ 2 ∑ n = 0 N − 1 [ x [ n ] s i n ( 2 π f 0 n + ϕ − A 2 sin ( 4 π f 0 n + 2 ϕ ] ∂ 2 l n p ( x ; ϕ ) ∂ ϕ 2 = − A σ 2 ∑ n = 0 N − 1 [ x [ n ] cos ( 2 π f 0 n + ϕ ) − A cos ( 4 π f 0 n + 2 ϕ ) ] − E [ ∂ 2 l n p ( x ; ϕ ) ∂ ϕ 2 ] = A σ 2 ∑ n = 0 N − 1 [ A cos 2 ( 2 π f 0 n + ϕ ) − A cos ( 4 π f 0 n + 2 ϕ ) ] = A 2 σ 2 ∑ n = 0 N − 1 [ 1 2 + 1 2 cos ( 4 π f 0 n + 2 ϕ ) − cos ( 4 π f 0 n + 2 ϕ ) ] = A 2 σ 2 − 1 2 N − A 2 σ 2 × 1 2 ∑ n = 0 N − 1 cos ( ) ≈ N A 2 2 σ 2 p(x;\phi)=\frac{1}{(2\pi\sigma^2)^{N/2}} \text{exp} \left[-\frac{1}{2\sigma^2}\displaystyle\sum_{n=0}^{N-1}[x[n]-A\text{cos}(2\pi f_0n+\phi)]^2\right]\\[0.5cm] \frac{\partial ln p(x;\phi)}{\partial\phi}=-\frac{A}{\sigma^2} \displaystyle\sum_{n=0}^{N-1}[x[n]sin(2\pi f_0n + \phi-\frac{A}{2}\text{sin}(4\pi f_0n+2\phi]\\[0.5cm] \frac{\partial^2 ln p(x;\phi)}{\partial\phi^2}=-\frac{A}{\sigma^2}\displaystyle\sum_{n=0}^{N-1}[x[n]\text{cos}(2\pi f_0n +\phi) -A\text{cos}(4\pi f_0 n+2\phi)]\\[0.5cm] -E\left[\frac{\partial^2 ln p(x;\phi)}{\partial\phi^2}\right]=\frac{A}{\sigma^2}\displaystyle\sum_{n=0}^{N-1}[A\text{cos}^2(2\pi f_0 n+\phi)-A\text{cos}(4\pi f_0 n +2\phi)]\\[0.5cm] =\frac{A^2}{\sigma^2}\displaystyle\sum_{n=0}^{N-1}\left[\frac{1}{2}+\frac{1}{2}\text{cos}(4\pi f_0 n+2\phi)-\text{cos}(4\pi f_0n+2\phi)\right]=\frac{A^2}{\sigma^2}-\frac{1}{2}N-\frac{A^2}{\sigma^2}\times\frac{1}{2}\displaystyle\sum_{n=0}^{N-1}\text{cos}()\\[0.5cm] \approx\frac{NA^2}{2\sigma^2} p ( x ; ϕ ) = ( 2 π σ 2 ) N / 2 1 exp [ − 2 σ 2 1 n = 0 ∑ N − 1 [ x [ n ] − A cos ( 2 π f 0 n + ϕ ) ] 2 ] ∂ ϕ ∂ l n p ( x ; ϕ ) = − σ 2 A n = 0 ∑ N − 1 [ x [ n ] s i n ( 2 π f 0 n + ϕ − 2 A sin ( 4 π f 0 n + 2 ϕ ] ∂ ϕ 2 ∂ 2 l n p ( x ; ϕ ) = − σ 2 A n = 0 ∑ N − 1 [ x [ n ] cos ( 2 π f 0 n + ϕ ) − A cos ( 4 π f 0 n + 2 ϕ ) ] − E [ ∂ ϕ 2 ∂ 2 l n p ( x ; ϕ ) ] = σ 2 A n = 0 ∑ N − 1 [ A cos 2 ( 2 π f 0 n + ϕ ) − A cos ( 4 π f 0 n + 2 ϕ ) ] = σ 2 A 2 n = 0 ∑ N − 1 [ 2 1 + 2 1 cos ( 4 π f 0 n + 2 ϕ ) − cos ( 4 π f 0 n + 2 ϕ ) ] = σ 2 A 2 − 2 1 N − σ 2 A 2 × 2 1 n = 0 ∑ N − 1 cos ( ) ≈ 2 σ 2 N A 2
for f 0 f_0 f 0 1 2 \frac{1}{2} 2 1 → var ( ϕ ^ ) ≥ 2 σ 2 N A 2 \rightarrow\text{var}(\hat\phi)\geq\frac{2\sigma^2}{NA^2} → var ( ϕ ^ ) ≥ N A 2 2 σ 2
Efficient estimator
An unbiased estimator that attains the CRLB
MVUE may or may not be efficient
Fisher Information I ( θ ) = − E [ ∂ 2 l n p ( x ; θ ) ∂ θ 2 ] = E [ ( ∂ l n p ( x ; θ ) ∂ θ ) 2 ] I(\theta)=-E\left[\frac{\partial^2 ln p(x;\theta)}{\partial \theta^2}\right]=E\left[\left(\frac{\partial ln p (x;\theta)}{\partial \theta}\right)^2\right] I ( θ ) = − E [ ∂ θ 2 ∂ 2 l n p ( x ; θ ) ] = E [ ( ∂ θ ∂ l n p ( x ; θ ) ) 2 ]
Why "Information"?
The more information, the lower the bound
Non-negative
Additive for independent observations
CRLB True or False The CRLB always exists regardless of p ( x ; θ ) p(x;\theta) p ( x ; θ ) False, regularity condition
The CRLB applies to unbiased estimators only : True
Determining the CRLB requires statistics of all possible estimators θ ^ \hat \theta θ ^ False, likelihood P ( x ˉ ; θ ) P(\bar x;\theta) P ( x ˉ ; θ )
The CRLB depends on the observations x x x False, applied expectations, removing dependency
The CRLB depends on the parameter to be estimated θ \theta θ True
The CRLB tells you whether or not a MVUE exists False, don't tell anything about MVUE
General CRLB for Signals in WGN
x [ n ] = x [ n ; θ ] + w [ n ] , n = 0 , 1 , … , N − 1 p ( x ; θ ) = 1 ( 2 π σ 2 ) N / 2 exp [ − 1 2 σ 2 ∑ n = 0 N − 1 ( x [ n ] − s [ n ; θ ] ) 2 ] ∂ l n p ( x ; θ ) ∂ θ = 1 σ 2 ∑ n = 0 N − 1 ( x [ n ] − s [ n ; θ ] ) ∂ s [ n ; θ ] ∂ θ ∂ 2 l n p ( x ; θ ) ∂ θ 2 = 1 σ 2 ∑ n = 0 N − 1 [ ( x [ n ] − s [ n ; θ ) ∂ 2 s [ n ; θ ] ∂ θ 2 − ( ∂ s [ n ; θ ] ∂ θ ) 2 ] E [ ∂ 2 l n p ( x ; θ ) ∂ θ 2 ] = − 1 σ 2 ∑ n = 0 N − 1 ( ∂ s [ n ; θ ] ∂ θ ) 2 v a r ( θ ^ ) ≥ σ 2 ∑ n = 0 N − 1 ( ∂ s [ n ; θ ] ∂ θ ) 2 x[n] = x[n;\theta]+w[n],\quad n=0,1,\dots,N-1\\[0.5cm] p(x;\theta)=\frac{1}{(2\pi\sigma^2)^{N/2}}\text{exp}\left[-\frac{1}{2\sigma^2}\displaystyle\sum_{n=0}^{N-1}(x[n]-s[n;\theta])^2\right]\\[0.5cm] \frac{\partial ln p (x;\theta)}{\partial \theta}=\frac{1}{\sigma^2}\displaystyle\sum_{n=0}^{N-1}(x[n]-s[n;\theta])\frac{\partial s[n;\theta]}{\partial \theta}\\[0.5cm] \frac{\partial^2lnp(x;\theta)}{\partial\theta^2}=\frac{1}{\sigma^2}\displaystyle\sum_{n=0}^{N-1}\left[(x[n]-s[n;\theta)\frac{\partial^2s[n;\theta]}{\partial\theta^2}-(\frac{\partial s[n;\theta]}{\partial\theta})^2\right]\\[0.5cm] E\left[\frac{\partial^2 ln p(x;\theta)}{\partial\theta^2}\right]=-\frac{1}{\sigma^2}\displaystyle\sum_{n=0}^{N-1}\left(\frac{\partial s[n;\theta]}{\partial \theta}\right)^2\\[0.5cm] var(\hat \theta)\geq\frac{\sigma^2}{\sum_{n=0}^{N-1}\left(\frac{\partial s[n;\theta]}{\partial\theta}\right)^2} x [ n ] = x [ n ; θ ] + w [ n ] , n = 0 , 1 , … , N − 1 p ( x ; θ ) = ( 2 π σ 2 ) N / 2 1 exp [ − 2 σ 2 1 n = 0 ∑ N − 1 ( x [ n ] − s [ n ; θ ] ) 2 ] ∂ θ ∂ l n p ( x ; θ ) = σ 2 1 n = 0 ∑ N − 1 ( x [ n ] − s [ n ; θ ] ) ∂ θ ∂ s [ n ; θ ] ∂ θ 2 ∂ 2 l n p ( x ; θ ) = σ 2 1 n = 0 ∑ N − 1 [ ( x [ n ] − s [ n ; θ ) ∂ θ 2 ∂ 2 s [ n ; θ ] − ( ∂ θ ∂ s [ n ; θ ] ) 2 ] E [ ∂ θ 2 ∂ 2 l n p ( x ; θ ) ] = − σ 2 1 n = 0 ∑ N − 1 ( ∂ θ ∂ s [ n ; θ ] ) 2 v a r ( θ ^ ) ≥ ∑ n = 0 N − 1 ( ∂ θ ∂ s [ n ; θ ] ) 2 σ 2 Wish to estimate α = g ( θ ) \alpha = g(\theta) α = g ( θ ) θ \theta θ
v a r ( α ^ ) ≥ ( ∂ g ( θ ) ∂ θ ) 2 − E [ ∂ 2 l n p ( x ; θ ) ∂ θ 2 ] var(\hat \alpha)\geq\frac{\left(\frac{\partial g(\theta)}{\partial\theta}\right)^2}{-E\left[\frac{\partial^2 lnp(x;\theta)}{\partial\theta^2}\right]} v a r ( α ^ ) ≥ − E [ ∂ θ 2 ∂ 2 l n p ( x ; θ ) ] ( ∂ θ ∂ g ( θ ) ) 2 Ex) DC level in WGN, α = g ( A ) = A 2 \alpha =g(A) =A^2 α = g ( A ) = A 2
v a r ( A 2 ^ ) ≥ ( 2 A ) 2 N σ 2 = 4 A 2 σ 2 N var(\hat{A^2})\geq\frac{(2A)^2}{\frac{N}{\sigma^2}}=\frac{4A^2\sigma^2}{N} v a r ( A 2 ^ ) ≥ σ 2 N ( 2 A ) 2 = N 4 A 2 σ 2
Is x ˉ 2 \bar x^2 x ˉ 2 A 2 A^2 A 2
if variance of x ˉ 2 \bar x^2 x ˉ 2
variance is now function of A A A
We know the Bound
We don't know how to find it
Linear transformation: g ( θ ) = a θ + b g(\theta) =a\theta +b g ( θ ) = a θ + b
g ( θ ) ^ = a θ ^ + b , θ ^ : efficient = hit CRLB E ( g ( θ ) ^ = a E ( θ ^ ) + b = a θ + b = g ( θ ) : unbiased var ( g ( θ ) ^ ) ≥ ( ∂ g ( t h e t a ) ∂ θ ) 2 I ( θ ) = ( ∂ g ( θ ) ∂ θ ) 2 var ( θ ^ ) Since θ ^ is efficient var ( θ ^ ) = 1 I ( θ ) = a 2 v a r ( θ ^ ) \hat{g(\theta)}=a\hat\theta+b,\;\hat\theta:\text{efficient}=\text{hit CRLB}\\ E(\hat{g(\theta)}=aE(\hat\theta)+b=a\theta+b =g(\theta):\text{unbiased}\\[0.5cm] \text{var}(\hat{g(\theta)})\geq\frac{\left(\frac{\partial g(theta)}{\partial\theta}\right)^2}{I(\theta)}=\left(\frac{\partial g(\theta)}{\partial\theta}\right)^2\text{var}(\hat \theta)\\ \text{Since} \; \hat\theta \text{ is efficient}\;\text{var}(\hat\theta)=\frac{1}{I(\theta)}\\ =a^2var(\hat\theta) g ( θ ) ^ = a θ ^ + b , θ ^ : efficient = hit CRLB E ( g ( θ ) ^ = a E ( θ ^ ) + b = a θ + b = g ( θ ) : unbiased var ( g ( θ ) ^ ) ≥ I ( θ ) ( ∂ θ ∂ g ( t h e t a ) ) 2 = ( ∂ θ ∂ g ( θ ) ) 2 var ( θ ^ ) Since θ ^ is efficient var ( θ ^ ) = I ( θ ) 1 = a 2 v a r ( θ ^ )
Since v a r ( g ( θ ) ^ = a 2 var ( θ ^ ) var(\hat{g(\theta)}=a^2\text{var}(\hat\theta) v a r ( g ( θ ) ^ = a 2 var ( θ ^ )
Else if, Efficiency is approximately maintained over nonlinear transformations if the data record is large enough.A 2 A^2 A 2 A 2 ^ = x ˉ 2 , var ( A ^ 2 ) ≥ ( 2 A ) 2 N σ 2 = 4 A 2 σ 2 N \hat{A^2}=\bar x^2, \text{var}(\hat A^2)\geq\frac{(2A)^2}{\frac{N}{\sigma^2}}=\frac{4A^2\sigma^2}{N} A 2 ^ = x ˉ 2 , var ( A ^ 2 ) ≥ σ 2 N ( 2 A ) 2 = N 4 A 2 σ 2
E ( x ˉ 2 ) = E 2 ( x ˉ ) + var ( x ˉ ) = A 2 + σ 2 N → A 2 as N → ∞ : asymptotically unbiased v a r ( x ˉ 2 ) = E ( x ˉ 4 ) − E 2 ( x ˉ 2 ) = 4 A 2 σ 2 N + 2 σ 2 N 2 → 4 A 2 σ 2 N a s N → ∞ : asymptotically efficient if ξ ∼ N ( μ , σ 2 ) , E ( ξ 2 ) = μ 2 + σ 2 , E ( ξ 4 ) = μ 4 + 6 μ 2 σ 2 + 3 σ 4 , and x ˉ ∼ N ( A , σ 2 N ) E(\bar{x}^2) = E^2(\bar{x}) + \text{var}(\bar{x}) = A^2 + \frac{\sigma^2}{N} \\ \rightarrow A^2 \text{ as } N \rightarrow \infty : \text{asymptotically unbiased}\\[0.5cm] var(\bar x^2)=E(\bar x^4)-E^2(\bar x^2)=\frac{4A^2\sigma^2}{N}+\frac{2\sigma^2}{N^2}\\ \rightarrow \frac{4A^2\sigma^2}{N}as\;N\rightarrow\infty:\text{asymptotically efficient}\\ \text{if } \xi \sim N(\mu, \sigma^2), E(\xi^2) = \mu^2 + \sigma^2, E(\xi^4) = \mu^4 + 6\mu^2\sigma^2 + 3\sigma^4, \text{ and } \bar{x} \sim N(A, \frac{\sigma^2}{N}) E ( x ˉ 2 ) = E 2 ( x ˉ ) + var ( x ˉ ) = A 2 + N σ 2 → A 2 as N → ∞ : asymptotically unbiased v a r ( x ˉ 2 ) = E ( x ˉ 4 ) − E 2 ( x ˉ 2 ) = N 4 A 2 σ 2 + N 2 2 σ 2 → N 4 A 2 σ 2 a s N → ∞ : asymptotically efficient if ξ ∼ N ( μ , σ 2 ) , E ( ξ 2 ) = μ 2 + σ 2 , E ( ξ 4 ) = μ 4 + 6 μ 2 σ 2 + 3 σ 4 , and x ˉ ∼ N ( A , N σ 2 )
Statiscal linearity of the trasformation : linear approximation is possible when the PDF of the x ˉ \bar x x ˉ A A A Even though Non-Linear : We can get CRLB
When the parameter θ = [ θ 1 θ 2 ⋯ θ p ] T \theta = [\theta_1\;\theta_2\;\cdots\;\theta_p]^T θ = [ θ 1 θ 2 ⋯ θ p ] T C θ ^ C_{\hat\theta} C θ ^ θ ^ \hat\theta θ ^ θ \theta θ Fisher Information Matrix is the quantity of importance here, and is the generalization of I ( θ ) I(\theta) I ( θ ) p × p p\times p p × p i , j i,\;j i , j
[ I ( θ ) ] i j = − E [ ∂ 2 l n p ( x ; θ ) ∂ θ i ∂ θ j ] [I(\theta)]_{ij}=-E\left[\frac{\partial^2 ln p(x;\theta)}{\partial\theta_i\partial\theta_j}\right] [ I ( θ ) ] i j = − E [ ∂ θ i ∂ θ j ∂ 2 l n p ( x ; θ ) ] where expectations are again taken over p ( x ; θ ) p(x;\theta) p ( x ; θ )
Assuming p ( x ; θ ) p(x;\theta) p ( x ; θ ) the regularity conditionE [ ∂ l n p ( x ; θ ) ∂ θ ] = 0 , for all θ E\left[\frac{\partial ln p(x;\theta)}{\partial\theta}\right]=0,\quad \text{for all }\theta E [ ∂ θ ∂ l n p ( x ; θ ) ] = 0 , for all θ
The covariance matrix of any unbiased estimator θ ^ \hat \theta θ ^ C θ ^ − I − 1 ( θ ) ≥ 0 C_{\hat \theta}-I^{-1}(\theta) \geq 0 C θ ^ − I − 1 ( θ ) ≥ 0 ≥ 0 \geq 0 ≥ 0
Furthermore, an unbiased estimator may be found that attains the bound C θ ^ = I − 1 ( θ ) C_{\hat\theta}=I^{-1}(\theta) C θ ^ = I − 1 ( θ ) ∂ l n p ( x ; θ ) ∂ θ = I ( θ ) ( g ( x ) − θ ) \frac{\partial ln p(x;\theta)}{\partial\theta}=I(\theta)(g(x)-\theta) ∂ θ ∂ l n p ( x ; θ ) = I ( θ ) ( g ( x ) − θ )
In that case, θ ^ = g ( x ) \hat \theta =g(x) θ ^ = g ( x ) I − 1 ( θ ) I^{-1}(\theta) I − 1 ( θ )
x [ n ] = A + w [ n ] , unknown A , σ 2 x[n] = A + w[n],\quad \text{unknown }A,\;\sigma^2 x [ n ] = A + w [ n ] , unknown A , σ 2 Ex) DC level in AWGN with unkwnown noise variance : θ = [ A σ 2 ] T \theta = [A \; \sigma^2]^T θ = [ A σ 2 ] T
The Fisher information matrix would be,I ( θ ) = [ − E [ ∂ 2 ln p ( x ; θ ) ∂ A 2 ] − E [ ∂ 2 ln p ( x ; θ ) ∂ A ∂ σ 2 ] − E [ ∂ 2 ln p ( x ; θ ) ∂ A ∂ σ 2 ] − E [ ∂ 2 ln p ( x ; θ ) ∂ σ 4 ] ] ln p ( x ; θ ) = − N 2 ln 2 π − N 2 ln σ 2 − 1 2 σ 2 ∑ n = 0 N − 1 ( x [ n ] − A ) 2 ∂ ln p ( x ; θ ) ∂ A = 1 σ 2 ∑ n = 0 N − 1 ( x [ n ] − A ) ∂ ln p ( x ; θ ) ∂ σ 2 = − N 2 σ 2 + 1 2 σ 4 ∑ n = 0 N − 1 ( x [ n ] − A ) 2 ∂ 2 ln p ( x ; θ ) ∂ A 2 = − N σ 2 ∂ 2 ln p ( x ; θ ) ∂ A ∂ σ 2 = − 1 σ 4 ∑ n = 0 N − 1 ( x [ n ] − A ) ∂ 2 ln p ( x ; θ ) ∂ σ 2 = N 2 σ 4 − 1 σ 6 ∑ n = 0 N − 1 ( x [ n ] − A ) 2 → I ( θ ) = [ N σ 2 0 0 N 2 σ 4 ] I(\theta) = \begin{bmatrix} -E\left[ \frac{\partial^2 \ln p(x; \theta)}{\partial A^2} \right] & -E\left[ \frac{\partial^2 \ln p(x; \theta)}{\partial A \partial \sigma^2} \right] \\ -E\left[ \frac{\partial^2 \ln p(x; \theta)}{\partial A \partial \sigma^2} \right] & -E\left[ \frac{\partial^2 \ln p(x; \theta)}{\partial \sigma^4} \right] \end{bmatrix}\\ \ln p(x; \theta) = -\frac{N}{2} \ln 2\pi - \frac{N}{2} \ln \sigma^2 - \frac{1}{2\sigma^2} \sum_{n=0}^{N-1} (x[n] - A)^2\\ \frac{\partial \ln p(x; \theta)}{\partial A} = \frac{1}{\sigma^2} \sum_{n=0}^{N-1} (x[n] - A)\\ \frac{\partial \ln p(x; \theta)}{\partial \sigma^2} = -\frac{N}{2\sigma^2} + \frac{1}{2\sigma^4} \sum_{n=0}^{N-1} (x[n] - A)^2\\ \frac{\partial^2\ln p(x;\theta)}{\partial A^2}=-\frac{N}{\sigma^2}\\ \frac{\partial^2 \ln p(x; \theta)}{\partial A \partial \sigma^2} = - \frac{1}{\sigma^4} \sum_{n=0}^{N-1} (x[n] - A)\\ \frac{\partial^2 \ln p(x; \theta)}{\partial \sigma^2} = \frac{N}{2\sigma^4} - \frac{1}{\sigma^6} \sum_{n=0}^{N-1} (x[n] - A)^2\\ \rightarrow I(\theta) = \begin{bmatrix} \frac{N}{\sigma^2} & 0 \\ 0 & \frac{N}{2\sigma^4} \end{bmatrix} I ( θ ) = ⎣ ⎢ ⎡ − E [ ∂ A 2 ∂ 2 l n p ( x ; θ ) ] − E [ ∂ A ∂ σ 2 ∂ 2 l n p ( x ; θ ) ] − E [ ∂ A ∂ σ 2 ∂ 2 l n p ( x ; θ ) ] − E [ ∂ σ 4 ∂ 2 l n p ( x ; θ ) ] ⎦ ⎥ ⎤ ln p ( x ; θ ) = − 2 N ln 2 π − 2 N ln σ 2 − 2 σ 2 1 n = 0 ∑ N − 1 ( x [ n ] − A ) 2 ∂ A ∂ ln p ( x ; θ ) = σ 2 1 n = 0 ∑ N − 1 ( x [ n ] − A ) ∂ σ 2 ∂ ln p ( x ; θ ) = − 2 σ 2 N + 2 σ 4 1 n = 0 ∑ N − 1 ( x [ n ] − A ) 2 ∂ A 2 ∂ 2 ln p ( x ; θ ) = − σ 2 N ∂ A ∂ σ 2 ∂ 2 ln p ( x ; θ ) = − σ 4 1 n = 0 ∑ N − 1 ( x [ n ] − A ) ∂ σ 2 ∂ 2 ln p ( x ; θ ) = 2 σ 4 N − σ 6 1 n = 0 ∑ N − 1 ( x [ n ] − A ) 2 → I ( θ ) = [ σ 2 N 0 0 2 σ 4 N ]
Diagonal Fisher information matrix, v a r ( A ^ ) ≥ σ 2 N , v a r ( σ ^ 2 ) ≥ 2 σ 4 N var(\hat A) \geq \frac{\sigma^2}{N}, var(\hat \sigma^2 ) \geq \frac{2\sigma^4}{N} v a r ( A ^ ) ≥ N σ 2 , v a r ( σ ^ 2 ) ≥ N 2 σ 4
Estimate α = g ( θ ) \alpha = g(\theta) α = g ( θ ) g g g
The covariance matrix C α ^ C_{\hat \alpha} C α ^ α ^ \hat \alpha α ^ C α ^ − ∂ g ( θ ) ∂ θ I − 1 ( θ ) ∂ g ( θ ) T ∂ θ ≥ 0 C_{\hat \alpha}-\frac{\partial g(\theta)}{\partial \theta}I^{-1}(\theta)\frac{\partial g(\theta)^T}{\partial \theta} \geq 0 C α ^ − ∂ θ ∂ g ( θ ) I − 1 ( θ ) ∂ θ ∂ g ( θ ) T ≥ 0
Here, ∂ g ( θ ) / ∂ θ \partial g(\theta)/\partial\theta ∂ g ( θ ) / ∂ θ r × p r\times p r × p Jacobian matrix, whose elements are[ ∂ g ( θ ) ∂ θ ] i , j = ∂ g j ( θ ) ∂ θ \left[\frac{\partial g(\theta)}{\partial \theta}\right]_{i,j}=\frac{\partial g_j(\theta)}{\partial \theta} [ ∂ θ ∂ g ( θ ) ] i , j = ∂ θ ∂ g j ( θ )
CRLB for General Gaussian Case
When observations are Gaussian and one knows the dependence of the mean and covariance matrix on the unknown parameters, we know the closed form of the CRLB(or Fisher information matrix):x ∼ N ( μ ( θ ) , C ( θ ) ) , \mathbf{x} \sim \mathcal{N}(\mu(\theta), C(\theta)), x ∼ N ( μ ( θ ) , C ( θ ) ) ,
Then, the Fisher information matrix I ( θ ) I(\theta) I ( θ ) [ I ( θ ) ] i , j = [ ∂ μ ( θ ) ∂ θ i ] T C − 1 ( θ ) [ ∂ μ ( θ ) ∂ θ j ] + 1 2 tr [ C − 1 ( θ ) ∂ C ( θ ) ∂ θ i C − 1 ( θ ) ∂ C ( θ ) ∂ θ j ] [I(\theta)]_{i,j}=\left[\frac{\partial \mu(\theta)}{\partial\theta_i}\right]^T C^{-1}(\theta)\left[\frac{\partial \mu(\theta)}{\partial \theta_j}\right] +\frac{1}{2}\text{tr}\left[C^{-1}(\theta)\frac{\partial C(\theta)}{\partial \theta_i} C^{-1} (\theta)\frac{\partial C(\theta)}{\partial \theta_j}\right] [ I ( θ ) ] i , j = [ ∂ θ i ∂ μ ( θ ) ] T C − 1 ( θ ) [ ∂ θ j ∂ μ ( θ ) ] + 2 1 tr [ C − 1 ( θ ) ∂ θ i ∂ C ( θ ) C − 1 ( θ ) ∂ θ j ∂ C ( θ ) ]
Phase Estimation CRLB
Phase estimation example, x [ n ] = A cos ( 2 π f 0 n + ϕ ) + w [ n ] x[n]=A\text{cos}(2\pi f_0 n+\phi) +w[n] x [ n ] = A cos ( 2 π f 0 n + ϕ ) + w [ n ] var ( ϕ ^ ) ≥ 2 σ 2 N A 2 \text{var}(\hat\phi)\geq\frac{2\sigma^2}{NA^2} var ( ϕ ^ ) ≥ N A 2 2 σ 2
Does an efficient estimator exist for this problem? The CRLB theorem says there is only if∂ ln p ( x ; θ ) ∂ θ = I ( θ ) ( g ( x ) − θ ) \frac{\partial \ln p(x;\theta)}{\partial \theta}=I(\theta)(g(x)-\theta) ∂ θ ∂ ln p ( x ; θ ) = I ( θ ) ( g ( x ) − θ )
From earlier result,∂ ln p ( x ; ϕ ) ∂ ϕ = − A σ 2 ∑ n = 0 N − 1 [ x [ n ] sin ( 2 π f 0 n + ϕ ) ] − A 2 sin ( 4 π f 0 n + 2 ϕ ) \frac{\partial \ln p(x; \phi)}{\partial \phi} = - \frac{A}{\sigma^2} \sum_{n=0}^{N-1} \left[ x[n] \sin(2\pi f_0 n + \phi) \right] - \frac{A}{2} \sin(4\pi f_0 n + 2\phi) ∂ ϕ ∂ ln p ( x ; ϕ ) = − σ 2 A n = 0 ∑ N − 1 [ x [ n ] sin ( 2 π f 0 n + ϕ ) ] − 2 A sin ( 4 π f 0 n + 2 ϕ )
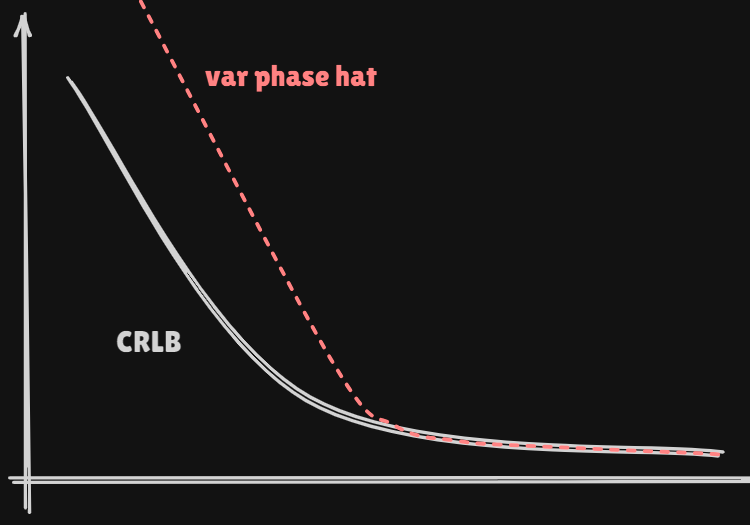
The condition for bound to hod is not satisfied!
We saw the estimator for which var ( ϕ ^ ) → C R L B a s N → ∞ \text{var}(\hat\phi) \rightarrow CRLB \;as\; N \rightarrow \infty var ( ϕ ^ ) → C R L B a s N → ∞
Such an estimator is called an asymptotically efficient estimator
Range Estimation CRLB
Transmit pulse s ( t ) s(t) s ( t ) t ∈ [ 0 , T s ] t \in [0,T_s] t ∈ [ 0 , T s ]
Receive reflection s ( t − τ 0 ) s(t-\tau_0) s ( t − τ 0 )
Estimation of time delay τ 0 \tau_0 τ 0 τ 0 = 2 R / c \tau_0 =2R/c τ 0 = 2 R / c
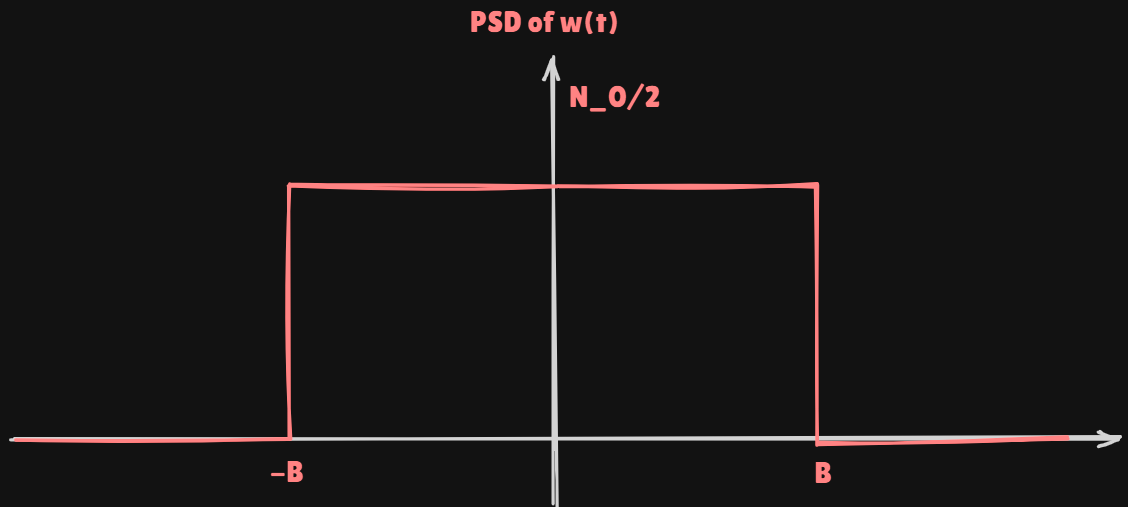
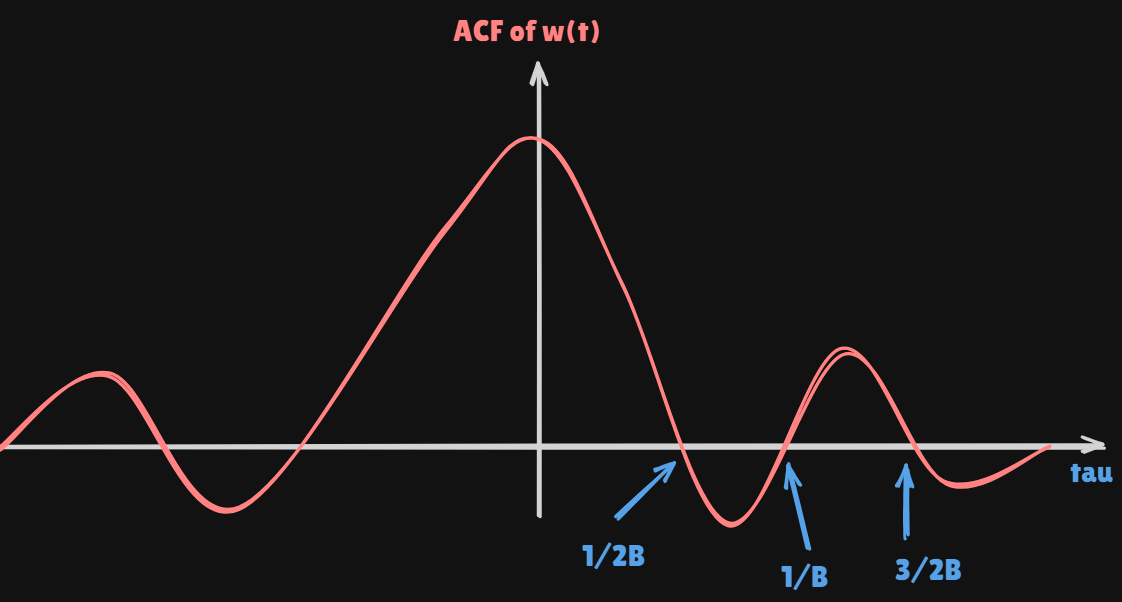
Continuous time signal modelx ( t ) = s ( t − τ 0 ) + w ( t ) 0 ≤ t ≤ T = T s + τ 0 m a x x(t) = s(t-\tau_0)+w(t) \quad 0\leq t\leq T=T_s+\tau_{0max} x ( t ) = s ( t − τ 0 ) + w ( t ) 0 ≤ t ≤ T = T s + τ 0 m a x r w w ( τ ) = N 0 B sin ( 2 π τ B ) 2 π τ B r_{ww}(\tau) = N_0 B \frac{\sin(2\pi \tau B)}{2\pi \tau B} r w w ( τ ) = N 0 B 2 π τ B s i n ( 2 π τ B )
Discrete time signal model
Sample every δ = 1 / ( 2 B ) \delta=1/(2B) δ = 1 / ( 2 B ) s [ n ] = s ( n δ − τ 0 ) + w [ n ] n = 0 , 1 , … , N − 1 s[n]=s(n\delta-\tau_0)+w[n]\quad n=0,1,\dots,N-1 s [ n ] = s ( n δ − τ 0 ) + w [ n ] n = 0 , 1 , … , N − 1
s ( n δ − τ 0 ) s(n\delta-\tau_0) s ( n δ − τ 0 ) M M M n 0 n_0 n 0 x [ n ] = { w [ n ] 0 ≤ n ≤ n 0 − 1 s ( n Δ − τ 0 ) + w [ n ] n 0 ≤ n ≤ n 0 + M − 1 w [ n ] n 0 + M ≤ n ≤ N − 1 x[n] = \begin{cases} w[n] & 0 \leq n \leq n_0 - 1 \\ s(n\Delta - \tau_0) + w[n] & n_0 \leq n \leq n_0 + M - 1 \\ w[n] & n_0 + M \leq n \leq N - 1 \end{cases} x [ n ] = ⎩ ⎪ ⎪ ⎨ ⎪ ⎪ ⎧ w [ n ] s ( n Δ − τ 0 ) + w [ n ] w [ n ] 0 ≤ n ≤ n 0 − 1 n 0 ≤ n ≤ n 0 + M − 1 n 0 + M ≤ n ≤ N − 1
Now apply standard CRLB result for signal + WGN
var ( τ 0 ^ ) ≥ σ 2 ∑ n = 0 N − 1 ( ∂ s [ n ; τ 0 ] ∂ τ 0 ) 2 = σ 2 ∑ n = n 0 n 0 + M − 1 ( ∂ s ( n Δ − τ 0 ) ∂ τ 0 ) 2 = σ 2 ∑ n = n 0 n 0 + M − 1 ( ∂ s ( t ) ∂ t ∣ t = n Δ − τ 0 ) 2 = σ 2 ∑ n = 0 M − 1 ( ∂ s ( t ) ∂ t ∣ t = n Δ ) 2 \text{var}(\hat{\tau_0}) \geq \frac{\sigma^2}{\sum_{n=0}^{N-1} \left( \frac{\partial s[n; \tau_0]}{\partial \tau_0} \right)^2}\\[0.4cm] = \frac{\sigma^2}{\sum_{n=n_0}^{n_0+M-1} \left( \frac{\partial s(n\Delta - \tau_0)}{\partial \tau_0} \right)^2}\\[0.4cm] = \frac{\sigma^2}{\sum_{n=n_0}^{n_0+M-1} \left( \frac{\partial s(t)}{\partial t} \Big|_{t = n\Delta - \tau_0} \right)^2}\\[0.4cm] = \frac{\sigma^2}{\sum_{n=0}^{M-1} \left( \frac{\partial s(t)}{\partial t} \Big|_{t = n\Delta} \right)^2} var ( τ 0 ^ ) ≥ ∑ n = 0 N − 1 ( ∂ τ 0 ∂ s [ n ; τ 0 ] ) 2 σ 2 = ∑ n = n 0 n 0 + M − 1 ( ∂ τ 0 ∂ s ( n Δ − τ 0 ) ) 2 σ 2 = ∑ n = n 0 n 0 + M − 1 ( ∂ t ∂ s ( t ) ∣ ∣ ∣ ∣ t = n Δ − τ 0 ) 2 σ 2 = ∑ n = 0 M − 1 ( ∂ t ∂ s ( t ) ∣ ∣ ∣ ∣ t = n Δ ) 2 σ 2
Assume sample spacing is samll...approx. sum by integral...
var ( τ 0 ^ ) ≥ σ 2 1 Δ ∫ 0 T s ( ∂ s ( t ) ∂ t ) 2 d t = N 0 / 2 ∫ 0 T s ( ∂ s ( t ) ∂ t ) 2 d t = 1 E s N 0 / 2 ⋅ 1 E s ∫ 0 T s ( ∂ s ( t ) ∂ t ) 2 d t = 1 SNR ⋅ B rms 2 (sec 2 ) \text{var}(\hat{\tau_0}) \geq \frac{\sigma^2}{\frac{1}{\Delta} \int_0^{T_s} \left( \frac{\partial s(t)}{\partial t} \right)^2 dt}\\[0.4cm] = \frac{N_0 / 2}{\int_0^{T_s} \left( \frac{\partial s(t)}{\partial t} \right)^2 dt}\\[0.4cm] = \frac{1}{\frac{E_s}{N_0 / 2} \cdot \frac{1}{E_s} \int_0^{T_s} \left( \frac{\partial s(t)}{\partial t} \right)^2 dt}\\[0.4cm] = \frac{1}{\text{SNR} \cdot B_{\text{rms}}^2} \, \text{(sec}^2\text{)} var ( τ 0 ^ ) ≥ Δ 1 ∫ 0 T s ( ∂ t ∂ s ( t ) ) 2 d t σ 2 = ∫ 0 T s ( ∂ t ∂ s ( t ) ) 2 d t N 0 / 2 = N 0 / 2 E s ⋅ E s 1 ∫ 0 T s ( ∂ t ∂ s ( t ) ) 2 d t 1 = SNR ⋅ B rms 2 1 (sec 2 )
Using these ideas we arrive at the CRLB on the delay:
var ( τ 0 ^ ) ≥ 1 SNR ⋅ B rms 2 (sec 2 ) \text{var}(\hat{\tau_0}) \geq \frac{1}{\text{SNR} \cdot B_{\text{rms}}^2} \, \text{(sec}^2\text{)} var ( τ 0 ^ ) ≥ SNR ⋅ B rms 2 1 (sec 2 )
To get the CRLB on the range use transf. of params result with R = c τ 0 / 2 R=c\tau_0/2 R = c τ 0 / 2
CRLB R ^ = ( ∂ R ∂ τ 0 ) 2 CRLB τ 0 ^ var ( R ^ ) ≥ c 2 / 4 SNR ⋅ B rms 2 ( m 2 ) \text{CRLB}_{\hat{R}} = \left( \frac{\partial R}{\partial \tau_0} \right)^2 \text{CRLB}_{\hat{\tau_0}}\\[0.4cm] \text{var}(\hat{R}) \geq \frac{c^2 / 4}{\text{SNR} \cdot B_{\text{rms}}^2} \, (\text{m}^2) CRLB R ^ = ( ∂ τ 0 ∂ R ) 2 CRLB τ 0 ^ var ( R ^ ) ≥ SNR ⋅ B rms 2 c 2 / 4 ( m 2 )
CRLB is inversely proportional to SNR and RMS BW Measure
All Content has been written based on lecture of Prof. eui-seok.Hwang in GIST(Detection and Estimation)