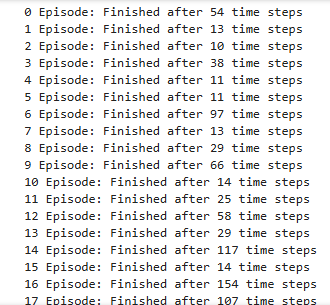
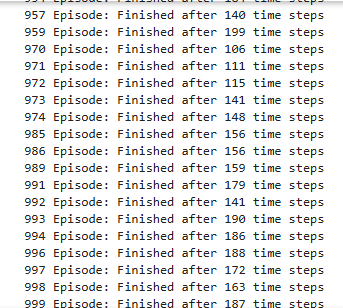
Q러닝 구현
- 구현할 클래스는
Agent, Brain, Environment
Agent : CartPole의 수레
- update_Q_function : Q함수의 수정
- get_action : 다음에 취할 행동을 결정
Brain : Agent 클래스의 두뇌 역할
- bins, digitize_state : 관측한 상태 observation을 이산변수로 변환
- update_Q_table : Q테이블 수정
- decide_action : Q테이블을 이용해 행동을 결정
Environment : 실행 환경
from JSAnimation.IPython_display import display_animation
from matplotlib import animation
from IPython.display import display
def display_frames_as_gif(frames):
'''
Displays a list of frames as a gif, with controls
'''
plt.figure(figsize=(frames[0].shape[1]/72.0, frames[0].shape[0]/72.0), dpi=72)
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames), interval=50)
anim.save('movie_cartpole.gif')
ENV = 'CartPole-v0'
NUM_DIZITIZED = 6
GAMMA = 0.99
ETA = 0.5
MAX_STEPS = 200
NUM_EPISODES = 1000
class Agent :
'''CartPole 에이전트 역할을 할 클래스, 봉 달린 수레'''
def __init__(self, num_states, num_actions) :
self.brain = Brain(num_states, num_actions)
def update_Q_function(self, observation, action, reward, observation_next) :
'''Q함수 수정'''
self.brain.update_Q_table(
observation, action, reward, observation_next
)
def get_action(self, observation, step) :
'''행동 결정'''
action = self.brain.decide_action(observation, step)
return action
class Brain :
'''에이전트의 두뇌 역할을 하는 클래스, Q러닝을 실제 수행'''
def __init__(self, num_states, num_actions):
self.num_actions = num_actions
self.q_table = np.random.uniform(low=0, high=1, size=(
NUM_DIZITIZED**num_states, num_actions
))
def bins(self, clip_min, clip_max, num):
'''관측된 상태(연속값)를 이산변수로 변환하는 구간을 계산'''
return np.linspace(clip_min, clip_max, num + 1)[1:-1]
def digitize_state(self, observation):
'''관측된 상태 observation을 이산변수로 반환'''
cart_pos, cart_v, pole_angle_pole_v = observation
digitized = [
np.digitize(cart_pos, bins=bins(-2.4, 2.4, NUM_DIZITIZED)),
np.digitize(cart_v, bins=bins(-3.0, 3.0, NUM_DIZITIZED)),
np.digitize(pole_angle, bins=bins(-0.5, 0.5, NUM_DIZITIZED)),
np.digitize(pole_v, bins=bins(-2.0, 2.0, NUM_DIZITIZED))
]
return sum([x * (NUM_DIZITIZED**i) for i, x in enumerate(digitized)])
def update_Q_table(self, observation, action, reward, observation_next):
'''Q러닝으로 Q테이블을 수정'''
state = self.digitize_state(observation)
state_next = self.digitize_state(observation_next)
Max_Q_next = max(self.q_table[state_next][:])
self.q_table[state, action] = self.q_table[state, action] + \
ETA * (reward + GAMMA + Max_Q_next - self.q_table[state, action])
def decide_action(self, observation, episode):
'''Epsilon-Greedy 알고리즘 적용 서서히 최적행동의 비중을 늘림'''
state = self.digitize_state(observation)
epsilon = 0.5 * (1 / (episode + 1))
if epsilon <= np.random.uniform(0, 1):
action = np.argmax(self.q_table[state][:])
else :
action = np.random.choice(self.num_actions)
return action
class Environment:
'''CartPole을 실행하는 환경 역할을 하는 클래스'''
def __init__(self):
self.env = gym.make(ENV, render_mode = 'rgb_array')
num_states = self.env.observation_space.shape[0]
num_actions = self.env.action_space.n
self.agent = Agent(num_states, num_actions)
def run(self):
'''실행'''
complete_episodes = 0
is_episode_final = False
frames = []
for episode in range(NUM_EPISODES) :
observation, info = self.env.reset()
if episode == NUM_EPISODES - 1 :
is_episode_final = True
for step in range(MAX_STEPS) :
if is_episode_final is True :
frames.append(self.env.render())
action = self.agent.get_action(observation, episode)
observation_next, _, done, _, _ = self.env.step(
action
)
if done :
if step < 195 :
reward = -1
complete_episodes = 0
else :
reward = 1
complete_episodes += 1
else :
reward = 0
self.agent.update_Q_function(
observation, action, reward, observation_next
)
observation = observation_next
if done :
print('{0} Episode: Finished after {1} time steps'.format(
episode, step + 1
))
break
if is_episode_final is True :
display_frames_as_gif(frames)
break
if complete_episodes >= 10 :
print("10 연속 에피소드 성공")
is_episode_final = True
cartpole_env = Environment()
cartpole_env.run()
- 예시에서는 200에피소드 이상 쯤 되면 학습이 완료되어 꽤 버티는데 난 그렇게까진 안나왔다
 |  |
|---|
| 학습 전 | 학습 후 |