강화학습
1.[강화학습] 1. 미로찾기
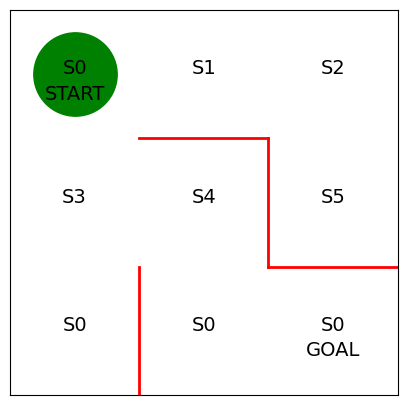
강화학습에서 에이전트가 어떻게 행동할지를 결정하는 규칙을 정책(Policy)이라고 한다$\\pi\_\\theta(s,a)$ : 상태가 $s$일 때 행동 $a$를 취할 확률을 파라미터 $\\theta$가 결정하는 정책 $\\pi$를 따른다미로탐색의 경우 상태 $s$는 에
2.[강화학습] 2. 정책반복 구현
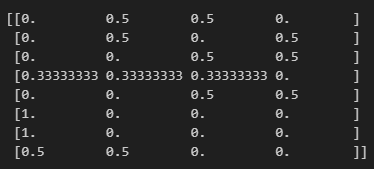
앞서 진행했던 부분은 미로 안을 무작위로 이동하는 정책을 구현했다. 이번에는 에이전트가 목표로 곧장 향하도록 정책을 학습해야 하는데 크게 두 가지 방법으로 나뉜다.목표에 빠르게 도달했던 경우에 수행했던 행동(action)이때의 행동을 앞으로도 취할 수 있도록 정책을 수
3.[강화학습] 3. 가치반복 구현

강화학습에서는 가치의 척도로 돈 대신 보상(reward)를 사용한다어떤 시각 $t$에 받을 수 있는 보상 $R_t$를 즉각보상(immediate reward)이라고 한다그리고 앞으로 받을 수 있으리라 예상되는 보상의 합계 $Gt$를 총보상이라고 한다$$R_t=R{t+1
4.[강화학습] 4. Q러닝 구현
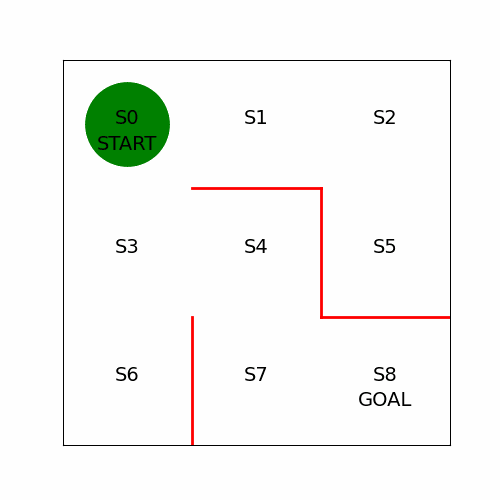
Sarsa와의 차이점은 행동가치 함수 $Q$를 수정하는 식만 다르다는 것이다$$Q(st,a_t)=Q(s_t,a_t)+\\eta\*(R{t+1}+\\gamma Q(s{t+1},a{t+1})-Q(st,a_t))$$$$Q(s_t,a_t)=Q(s_t,a_t)+\\eta\*(R
5.[강화학습] 5. 역진자 문제
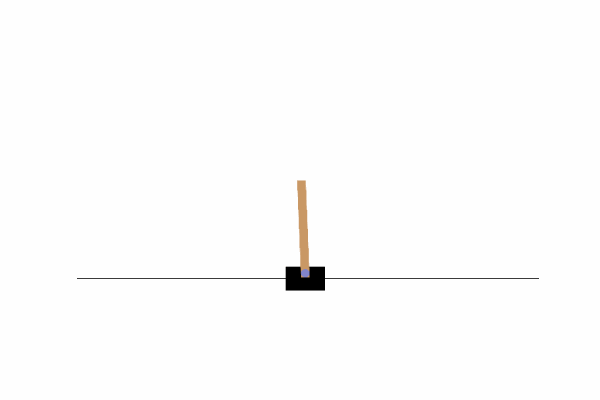
Setup 우선 셋업을 위해 Conda 가상환경을 준비하고 다음의 라이브러리를 인스톨한다 이후 Jupyter Application install하고 Launch한다 역진자 태스크 "CartPole" 진자를 쓰러지지 않게 하는 태스크 OpenAI Gym에서 CartP
6.[강화학습] 6. 다변수, 연속값 상태 표현
미로에서상태 : 에이전트가 어느 칸에 위치했는지 변수 하나로 나타냄(0 ~ 8 단순 이산값)역진자 태스크에서는 더 복잡하게 상태가 정의되어야함역진자에서의 상태수레의 위치 : $-2.4 \\sim 2.4$수레의 속도 : $-\\infty \\sim \\infty$봉의 각
7.[강화학습] 7. 역진자 태스크 Q러닝 구현
구현할 클래스는 Agent, Brain, EnvironmentAgent : CartPole의 수레update_Q_function : Q함수의 수정get_action : 다음에 취할 행동을 결정Brain : Agent 클래스의 두뇌 역할bins, digitize_stat
8.[강화학습] 왜 Pytorch...? +맛보기

Pytorch와 체이너 장점으로 설계상 Define by Run(동적 계란 그래프)이라는 사상을 따르고 있다는 점Define by Run입력 데이터의 크기나 차원 수에 맞춰 신경망의 구조와 계산 과정을 변화시킬 수 있다그러나 Tensorflow에서는 Define and
9.[강화학습] 8. DQN 구현(1)
표형식 표현을 사용했던 Q러닝에서는 표의 각 행이 에이전트의 상태를, 표의 각 열이 에이전트가 취할 수 있는 행동에 해당했다그리고 셀의 각 값은 행동가치 $Q(s,a)$였다에이전트의 상태란미로 태스크에서는 에이전트가 있는 칸의 의치였고역진자에서는 4개 변수를 이산변수로
10.[강화학습] 9. DQN 구현(2)

미니 배치 사용Experience Replay 및 유사 Fixed Tager Q-Network를 구현하기 위해 미니 배치 학습 적용DQN은 각 단계의 trasnsition(상태 $st$, 행동 $a_t$, 그다음 상태 $s{t+1}$, 보상$r\_{t+1}$을 메모리
11.[강화학습] 10. DDQN(Double-DQN) 구현
2013년 발표 버전Target Q-Network를 따로 두고 Main Q-Network를 학습시킨다몇 단계마다 한번씩 Target Q-Network를 수정해서 Main Q-Network와 일치시킨다2015년 네이처 발표 버전$$Qm(s_t,a_t)=Q_m(s_t,a_
12.[강화학습] 1-2. Q-learning
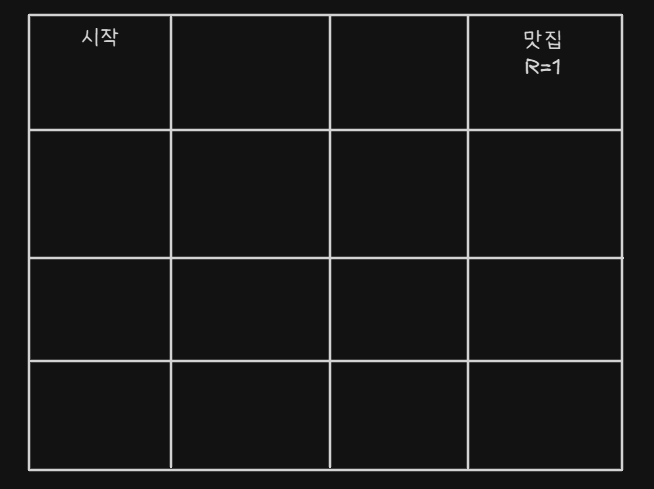
내 AI Agent가 맛집을 찾아가게 하고 싶은 상황이다뭐 랜덤으로 움직이다가 맛집으로 들어갈 수도 있겠지어쨋든 찾아가게 하고 싶다각 방향에 대해 점수를 부여한다각 셀에서는 위, 아래, 왼쪽, 오른쪽으로 갈 수 있다(모서리 제외)맛집에 들어가면 R(Reward) 보상을
13.[강화학습] 1-3. Markov Decision Process
Markov Decision Process 1. 모든 State와 Action은 Random Variable이다 $$ p(a1|s0,a0,s1) $$ $s1$일때 $a1$을 구하려면 굳이 $s0$과 $a0$는 알 필요가 없다. 왜? 이미 $s_1$에 반영이 되어있으니까